智能监控概述
在运维领域落地智能运维最好的领域就是监控,因为监控系统有大量的数据。
监控系统演进的几个阶段:
- 监控自动化
-
- 监控系统可用、好用
- 监控立体化
-
- 监控覆盖面更全,采集到各维度更全面、更完整的数据
- 监控平台化
-
- 监控系统与其他运维自动化系统打通和联动,比如与跟CMDB打通,能够自动更新相关的负责人,以及集群服务器的信息,比如与部署系统打通,当集群服务上线的时候能自动屏蔽这些集群服务的告警,然后在上线完成后恢复监控。
- 监控产品化
-
- 监控系统虽然是一个内部系统,技术人员经常需要观察监控系统来发现问题,优化系统,在故障发生的时候能够更快更方便的去定位问题,判定根因。所以监控产品更需要贴近人的使用习惯,用户体验更好。
- 监控智能化
-
- 让监控系统拥有更强的智能
传统监控与智能监控的差别:
| 传统的监控 | 智能监控 |
|---|---|
| 监控指标侧重单机运行状态 | 监控指标侧重业务整体运行情况 |
| 做固定阈值的异常判断 | 对周期性波动变化的指标做预测和异常检测 |
| 发出基本的告警,数量较大 | 对信息做有效的区分和整合 |
| 做故障现象的告警,需要大量的人工分析 | 做故障根因的分析,揭示问题的本质 |
| 发现问题而不处理,由人决定如何处理 | 根据故障根因,智能决定如何处理并执行 |
| 发出告警时已经出现故障 | 在故障出现前发出预警 |
智能监控总体规划
监控业务全流程覆盖
- 故障预警:故障前可以发出故障预警
- 故障告警:能对周期性变化指标进行预测和异常检测
- 告警合并:支持按照合适的维度对告警进行合并
- 故障根因分析:智能对故障根因进行分析,给出最可能的原因,辅助人做决策
- 故障自愈:可以根据故障原因选择合适的故障自愈策略并执行,自动解决故障

关键指标的智能监控
关键指标的智能预测和异常检测
关键指标指标的定义:
比如某项业务网络流量的变化,或者某些集群或者域名访问量的变化,或者是某一个业务订单量和交易额的变化,这些指标对于衡量整个业务的健康程度是非常有效,非常相关的。
这类指标整体规律性较强、短期小幅波动较多的关键指标,不适合使用传统静态阈值的异常判断告警。
适用的场景:
- 网络出口或业务的进出流量
- 集群和域名的访问量
智能监控的需求:
- 按天对流量的提前预测
- 对实时流量的异常检测
技术实现方案:
使用机器学习和运维相关业务结合
- 使用回归模型按天预测流量变化趋势
- 使用分类模型对实时流量做异常检测
机器学习方法的四个步骤
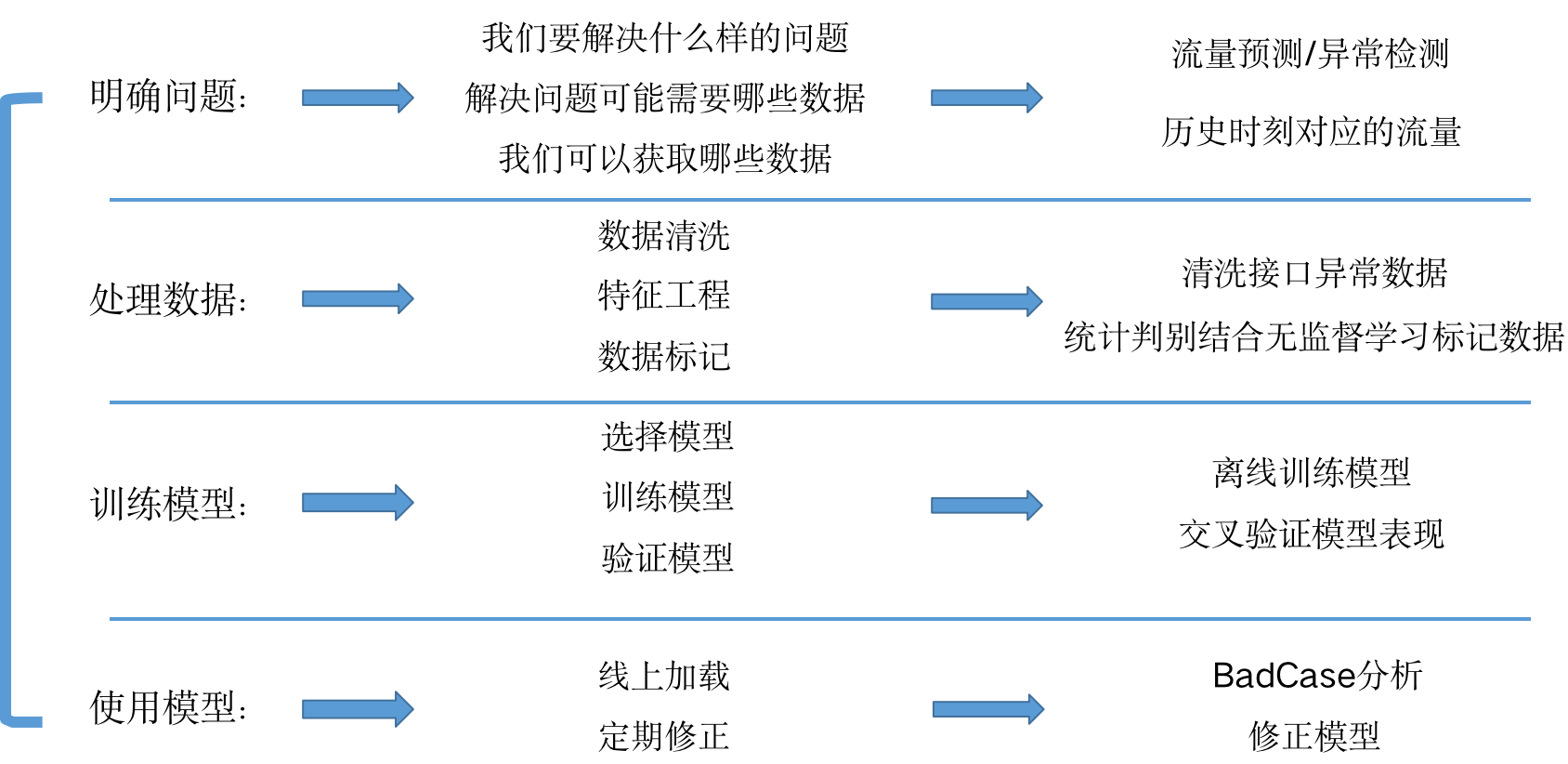
流量预测及异常检测的技术框架
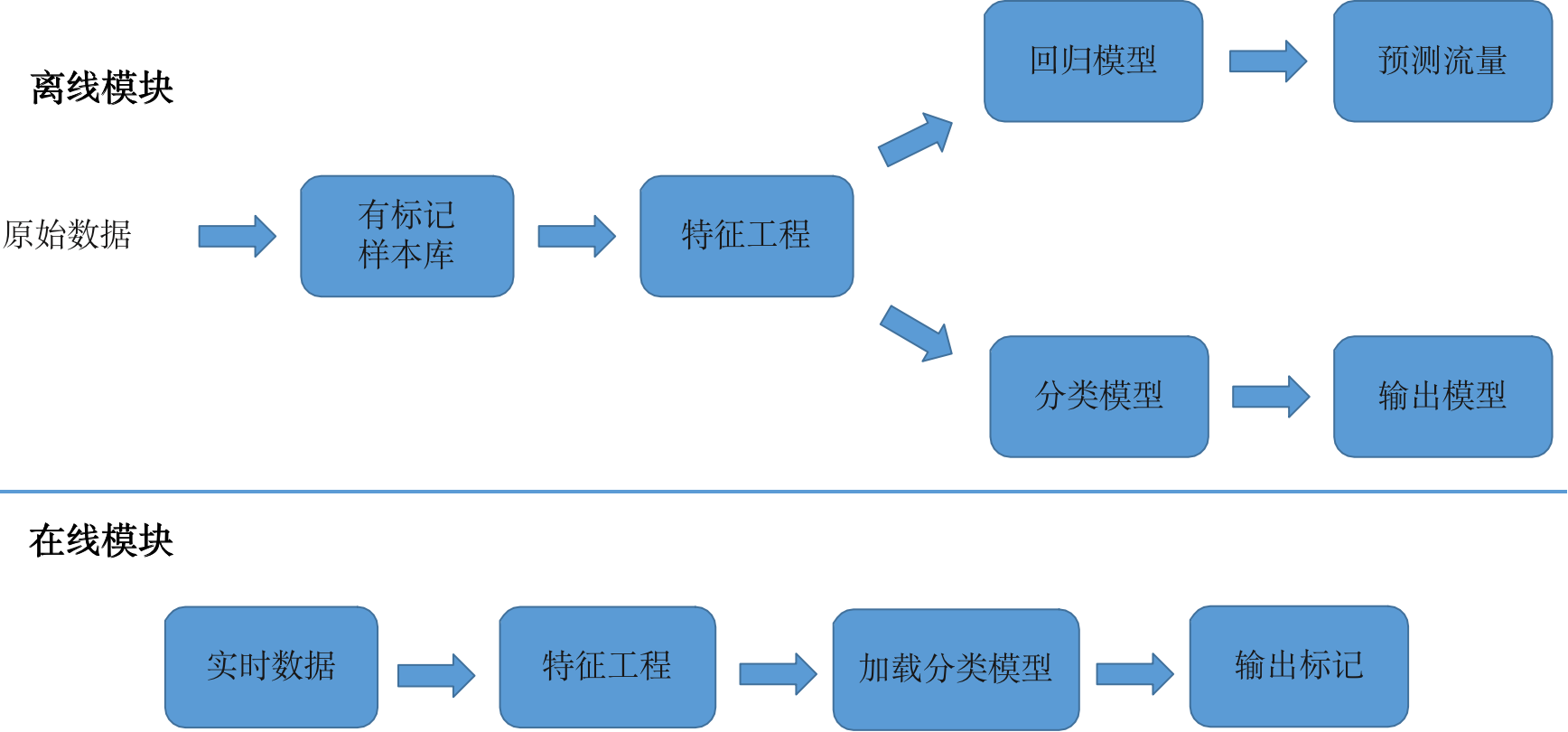
训练集样本的标记
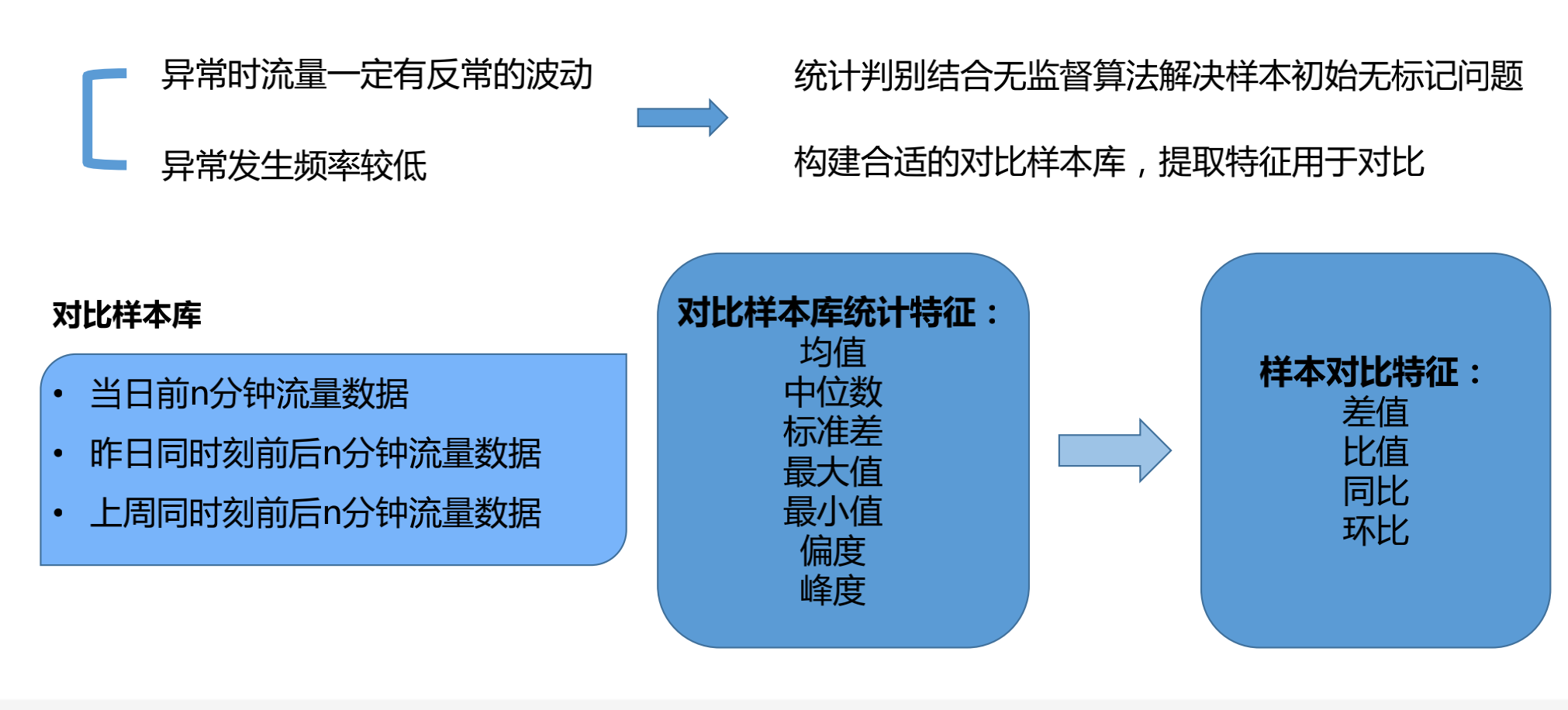
做机器学习,其实很重要的一点是对训练集样本的标记,当我们拿到的流量数据或者访问量的数据是非常大量的数据,有上百万条,这样的数据就必须得对数据进行标记。
如果采用人工的方式,必然要耗费大量的时间和工作量,这个短期之内是无法完成的,所以采用统计的方法及无监督算法的方式,对这个样本库进行二次的标记,从而可以得到一个比较准确,可以信任的一个样本库,具体的过程如下:
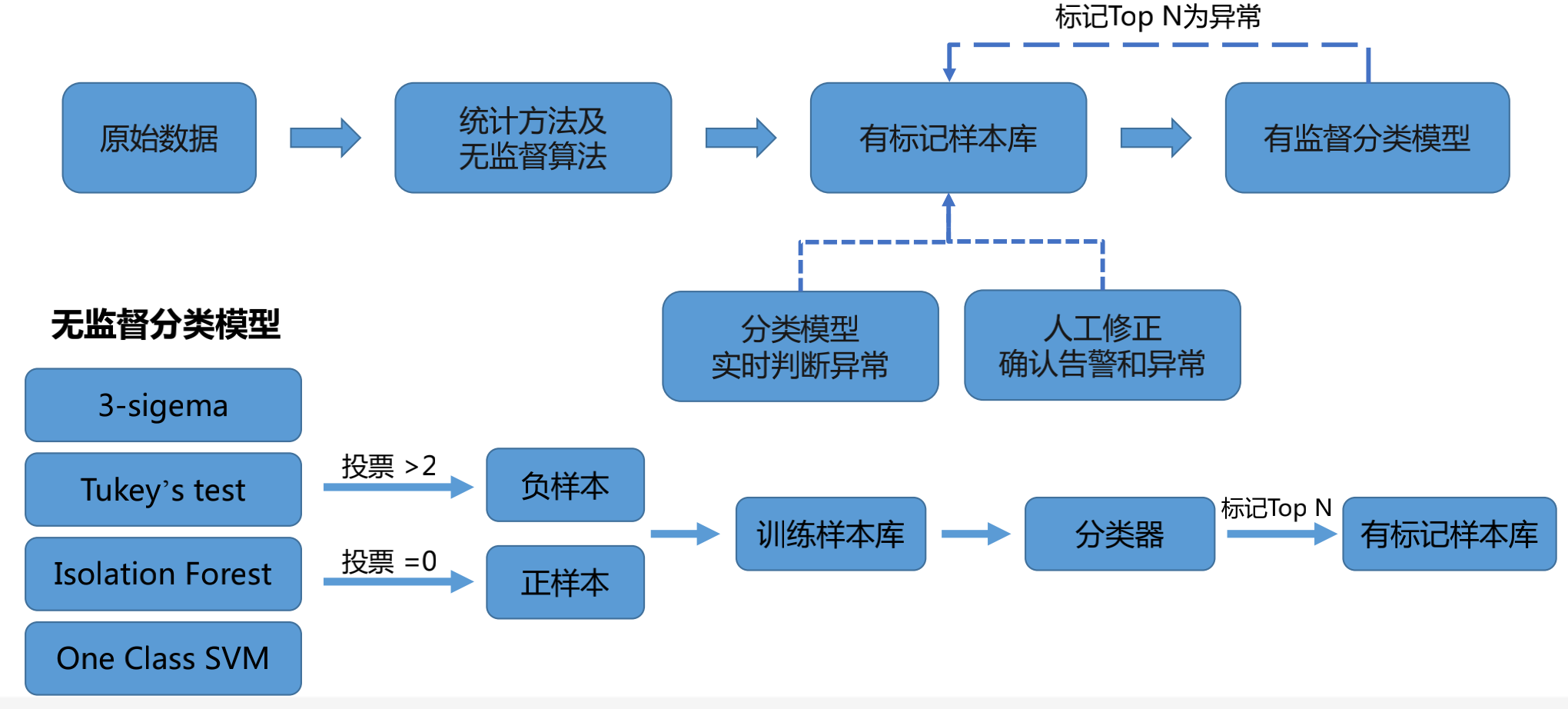
如何使用统计方法与无监督算法对数据进行标记?
3-sigema,Tukey’s test,Isolation Forest,One Class SVM每一个方法其实它的准确度不是特别高,所以采用集成模型的方法,也就是说有四个分类器采用投票的方式,共同投票出来的结果其实是好于原来每一个方法,那当这四种方法都认为某一个数据点是异常点的话那么这个点就标记为异常数据,当所有的方法都认为这个点是一个正常点的时候那么就标记为正样本。
这样就可以得到一个初步的训练的样本库,然后使用这个样本库训练出一个分类器,再将历史数据投入到这个分类器中,这个分类器输出的是一个异常的概率,我们取这个异常概率为Top N的这些数据集,再把它标记为一个有标记的样本库,这样就得到了一个相对比较准确的一个有标记的样本库,这样用这些数据就可以训练机器学习的模型了。
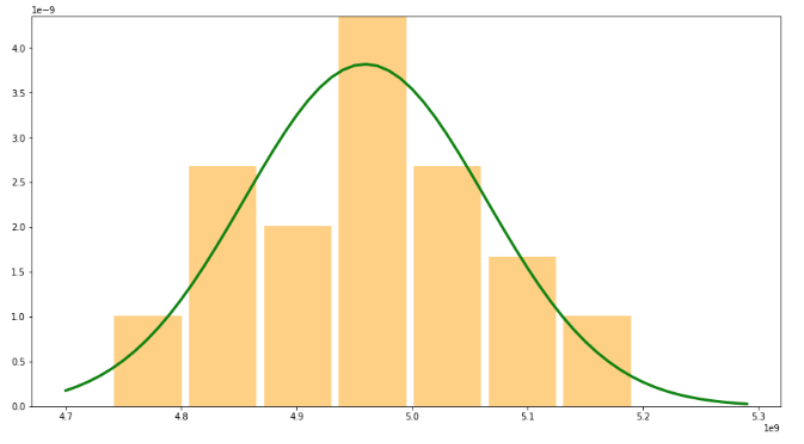
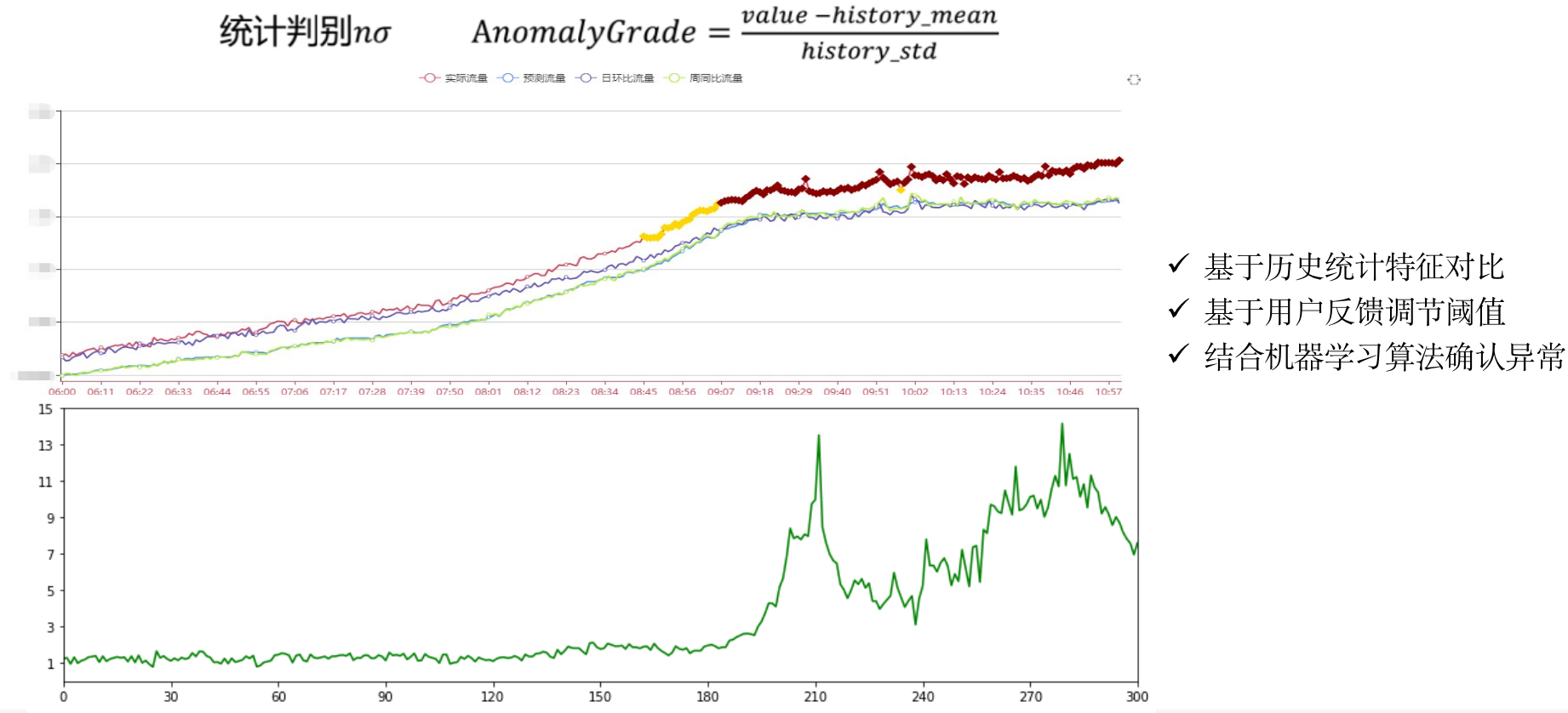
统计判别方法——3-sigema
3-sigema的特点:
- 解释性好
- 计算开销小
- 更适用于正态分布
3-sigema的缺点:
- 无法处理复杂情况
正态分布
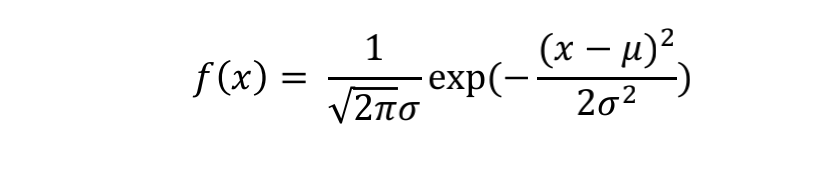
统计判别方法——Tukey’s test
Tukey’s test采用类似于上下中位数相关的一些算法,然后来决定:
- 正常数据一般来说都是比较密切的,比较接近。
- 异常数据往往是离大部分的正常数据是比较远。
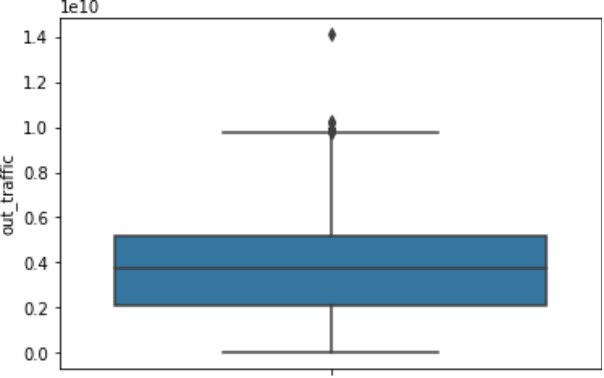
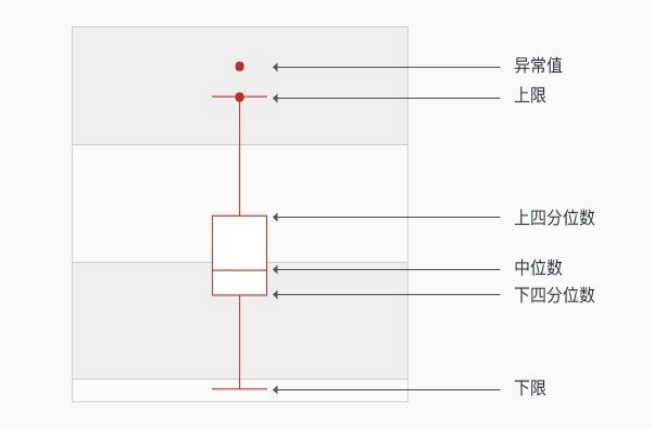
通过这种方式,我们看到它位于上面和下面这些比较边缘的点就可能是一些异常的点。
Tukey’s test的特点:
- 不受异常值的影响
- 能够准确稳定地描绘出数据的离散分布情况
Tukey’s test的缺点:
- 过于敏感,不够智能

无监督算法——Isolation Forest
Isolation Forest算法的思想是随机的选择一些点,然后去生成树形结构,但由于这个异常的点,它必然与正常点是不太一样,特征也就不太一样。
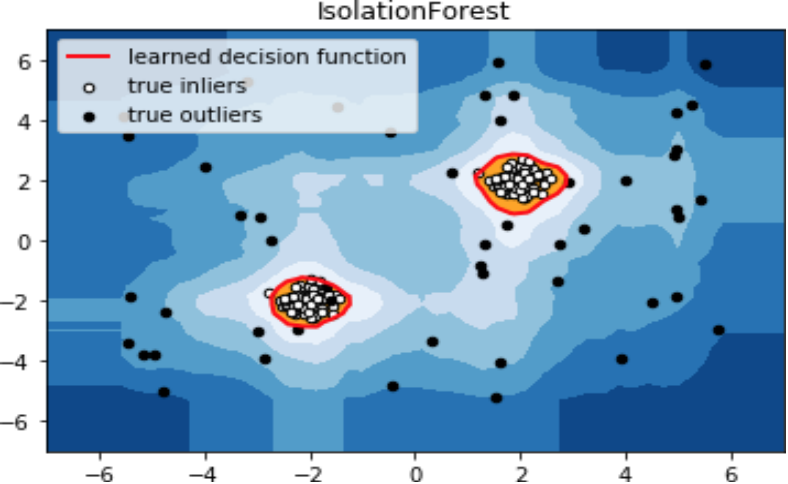
在这个空间当中,它与正常点的距离和聚集程度也是比较远。
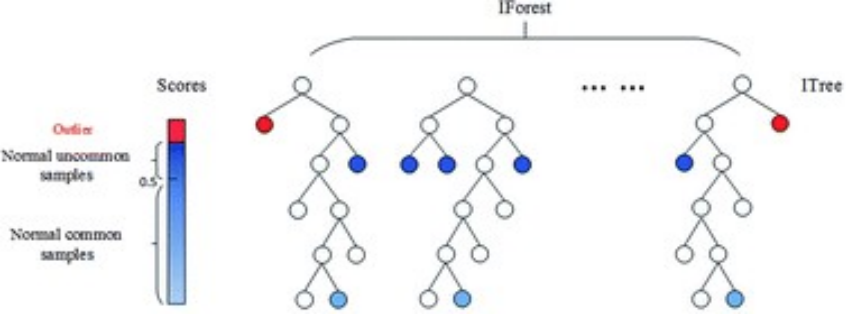
一般来说,在这个多棵树当中异常的点,它处于的层次会比较浅,那最后根据它处于这个层次基本上就能够判断出它是一个正常点还是一个异常点

Isolation Forest的特点:
- 使用集成方法的无监督算法
- 计算开销小,训练速度快
- 异常点更加靠近树的根部,而正常数据多 处于树中更深的节点
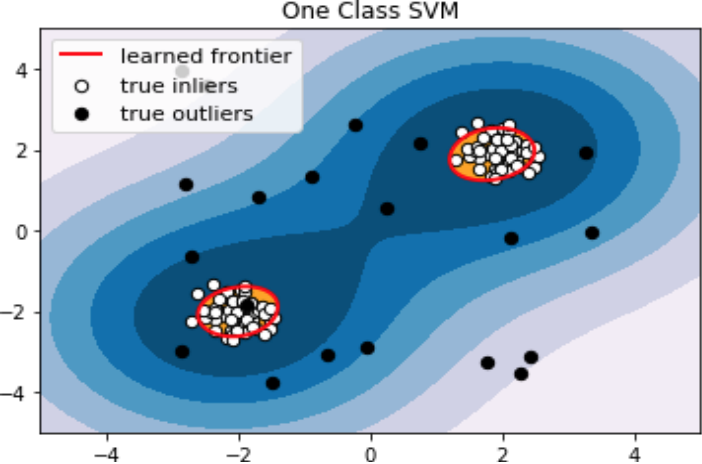
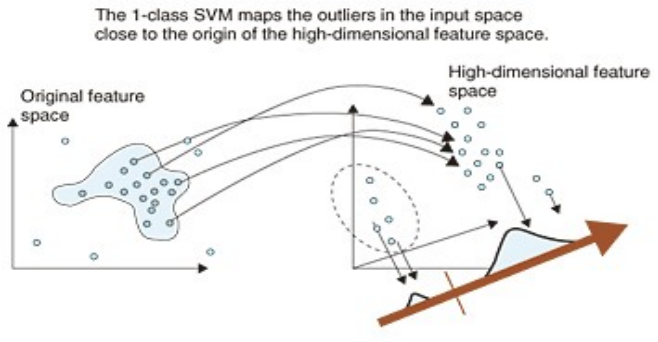
无监督算法–——One Class SVM
One Class SVM的特点:
- 利用支持向量域描述的思想,寻找分离超平面;
- 适用于连续数据的异常检测;
- 适用于筛选一定比例的样本;
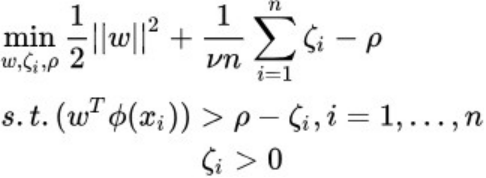
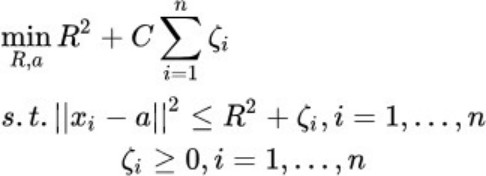
流量的预测
当得到了一个基本的有标记的一个训练集,那么就可以根据这个训练集来做流量的预测和异常检测了
流量的预测怎么做?
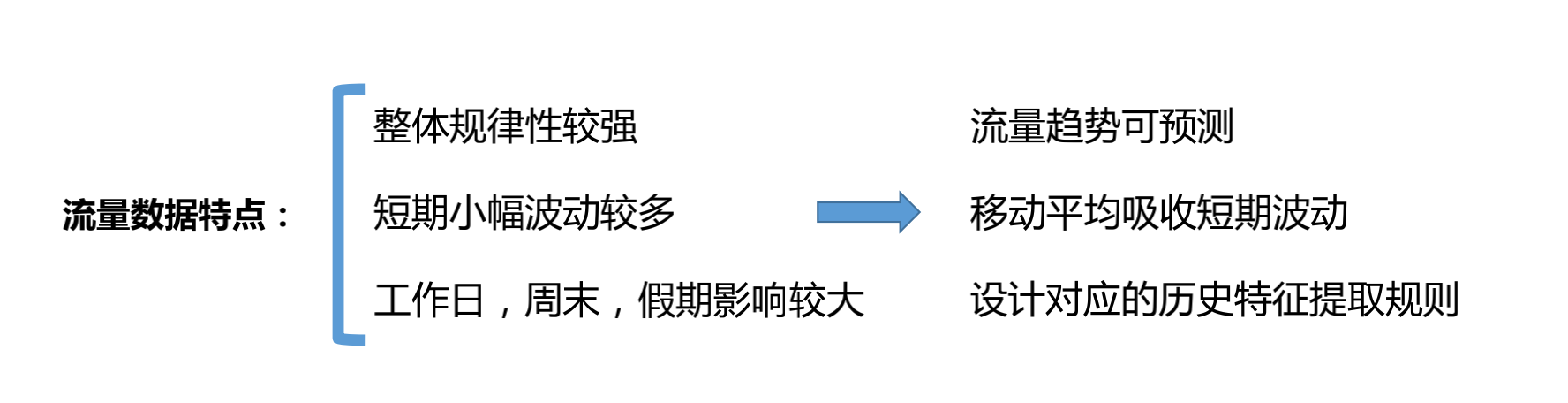
我们先来看一下这些数据的特点,首先它的整体规律性比较强,整体规律性比较强,就可以认为这个流量趋势其实是可以预测的。其次是短期的小幅波动会比较多,就可以通过移动平均的这种方式来吸收他的短期的这个波动,最后一个特点,就是在工作日周一到周五他的流量相对来说是比较高,但是在周日流量相对来说偏低,假期流量也是偏低的,所以要设计对应的历史特征提取规则。

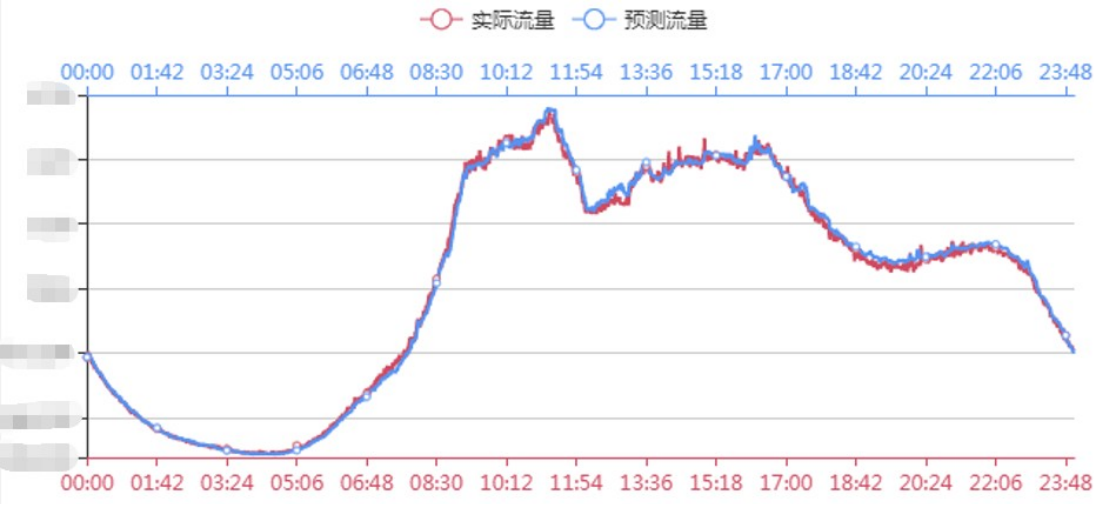
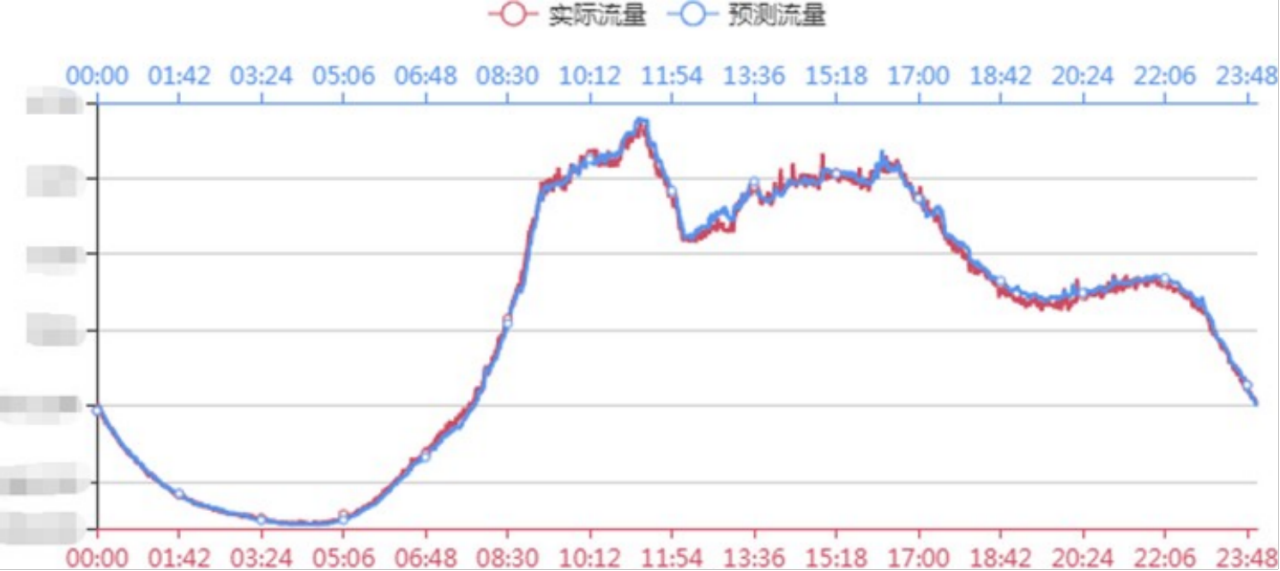
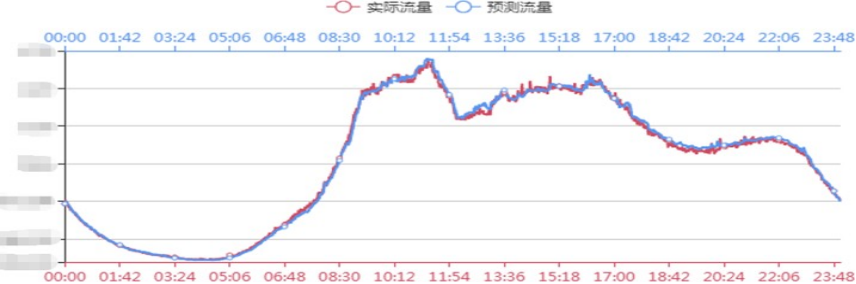
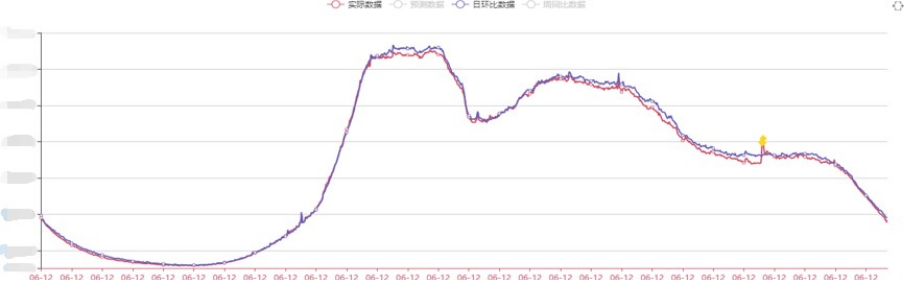
流量的预测效果
采用回归模型这种方式来看流量预测的效果,其中红色的线代表实际的流量,蓝色的线代表预测的流量,从这个图中可以看出,这两者之间吻合程度还是比较高的。
根据历史数据预测明天的数据:
异常检测
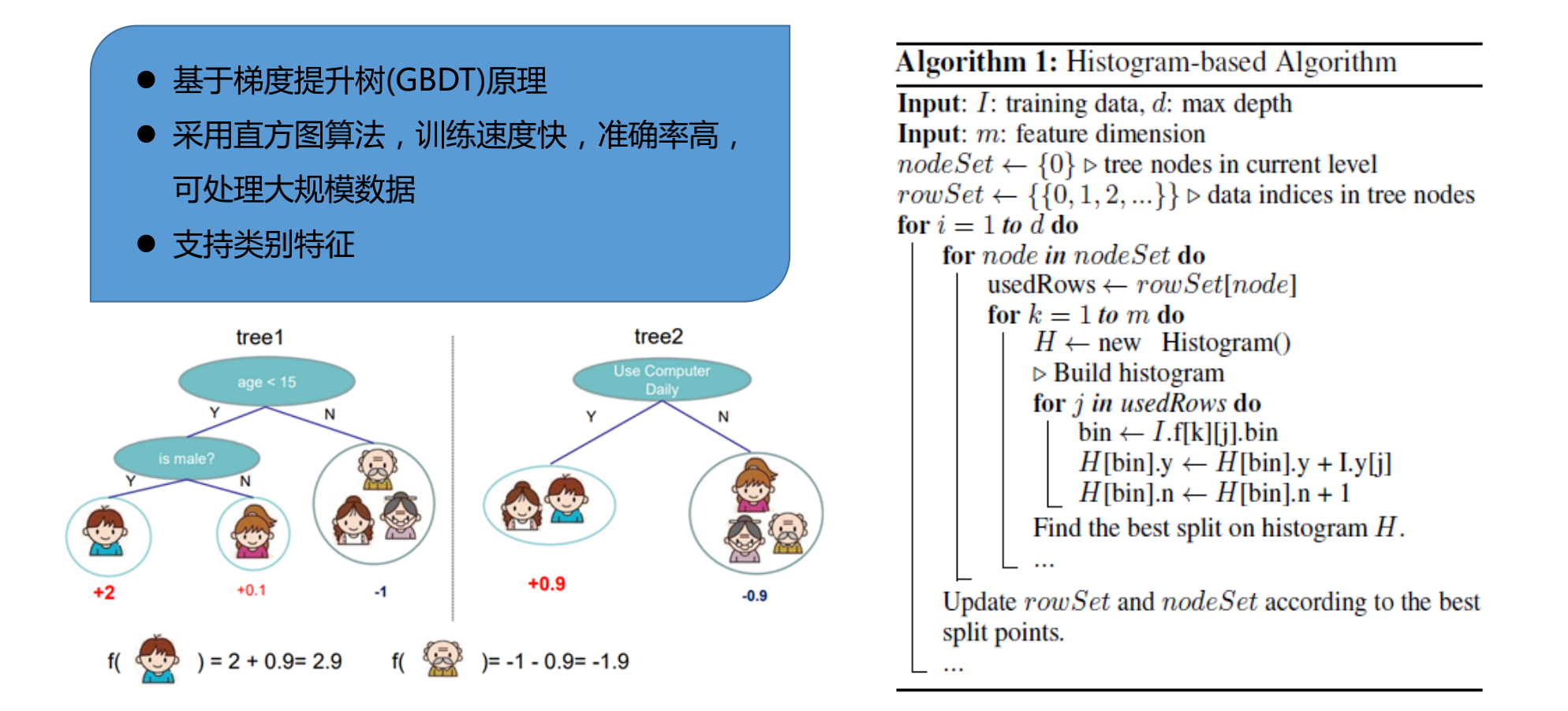
有监督算法——LightGBM
在这个回归问题和分类问题上,选择一个有监督的算法LightGBM
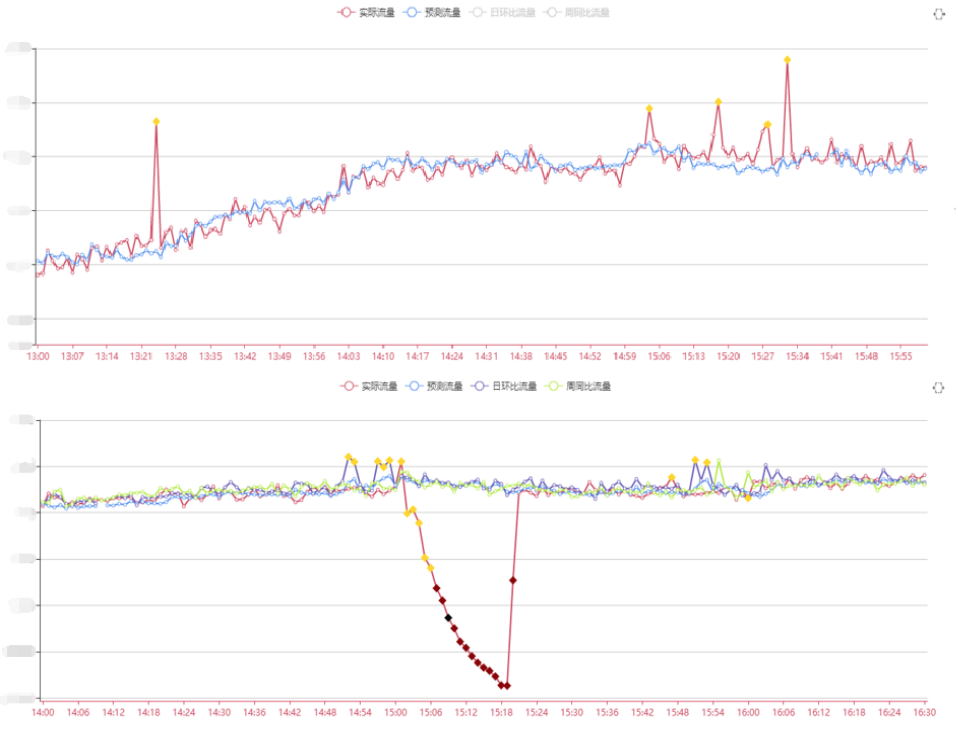
异常检测的效果
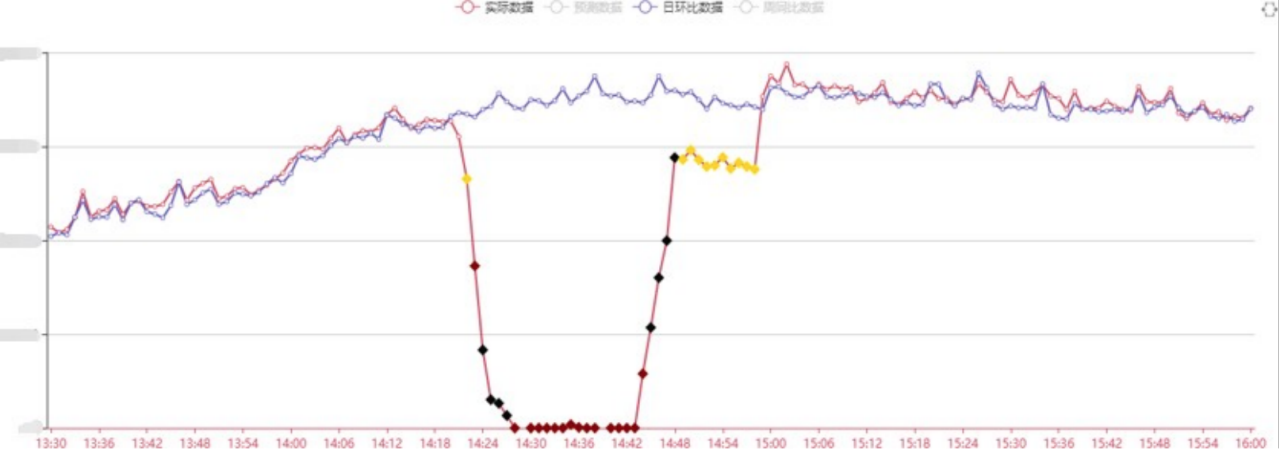
基于数据异常程度将异常分为:普通异常、严重异常、陡变异常。
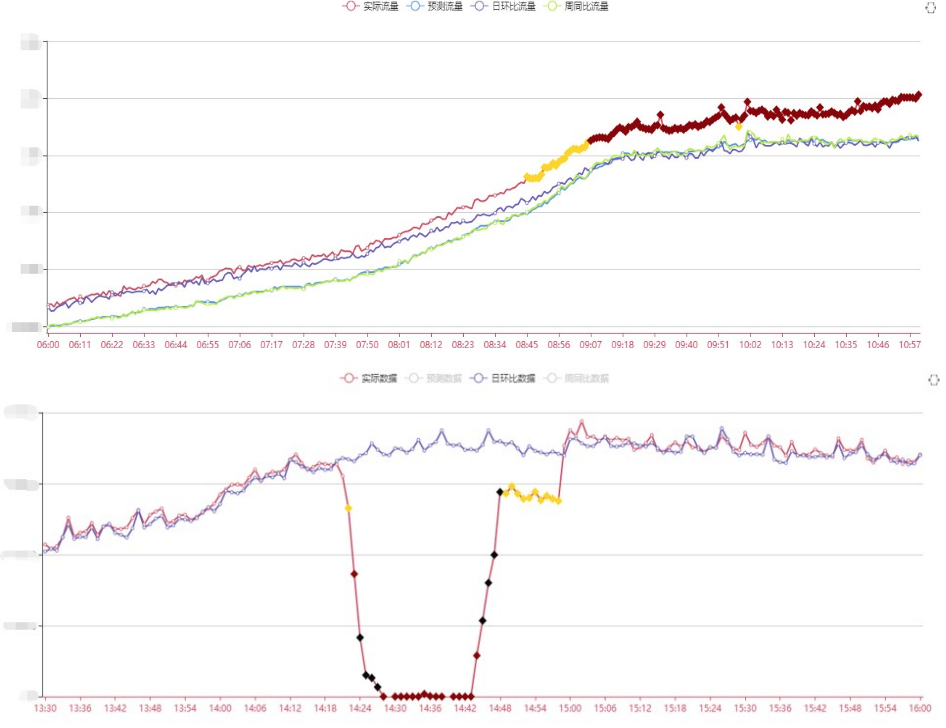
异常分级——普通异常
普通异常:数据与预期有一些短期的小的偏差,可能是与少量的用户突发访问或爬虫抓取引起的。
能发现短暂的流量异常,比较灵敏,通过连续n次异常才告警的策略过滤掉毛刺。
识别算法:机器学习算法判别(LightGBM)
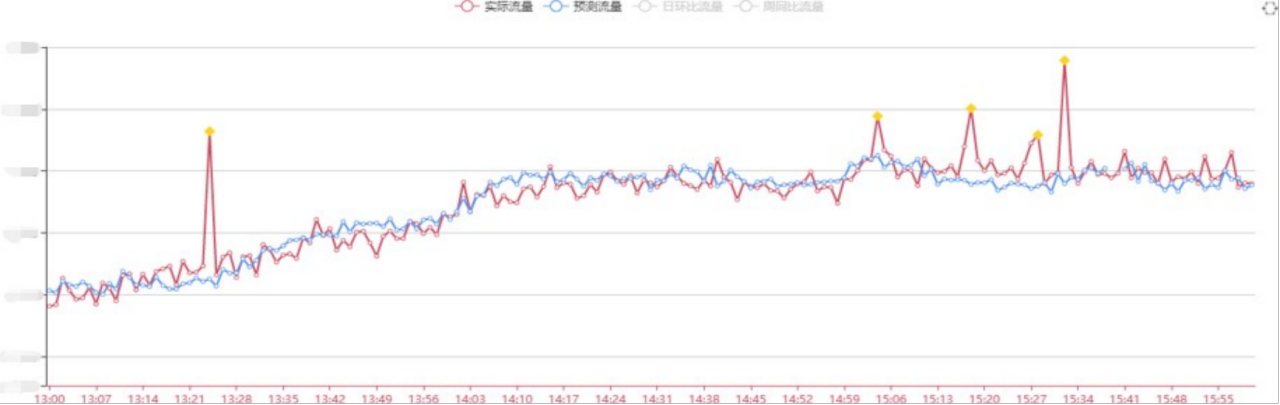
异常分级——严重异常
严重异常:数据长时间出现了较大的偏离,需要排查数据变化的原因。
可能是由于网络故障、系统故障或流量推广活动等引起较大的数据变化
识别算法:机器学习算法+历史同期数据统计判别
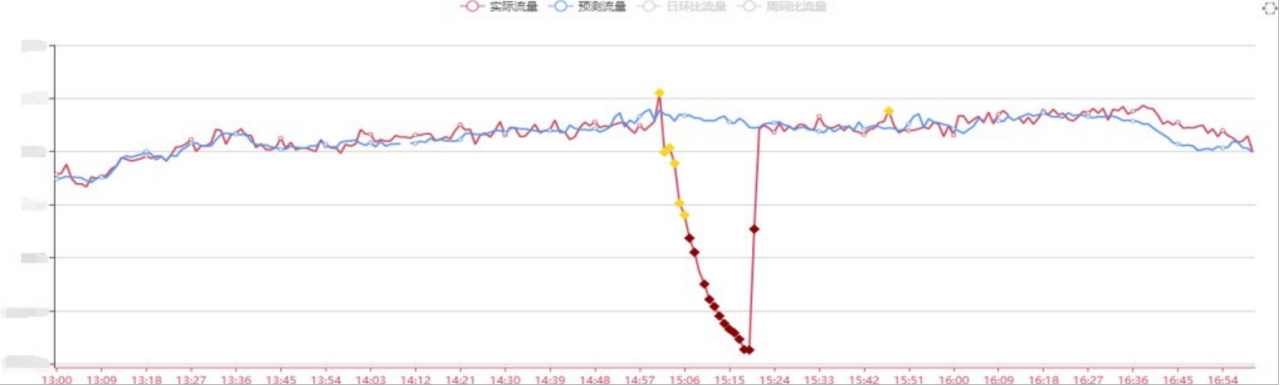
异常分级——陡变异常
陡变异常:流量突然出现断崖式的增长或者下跌。
可能是受突发的网络流量攻击,或者系统出现严重问题,需要立刻高优先级排查和解决。
识别算法:机器学习算法+均值比值阈值校验。
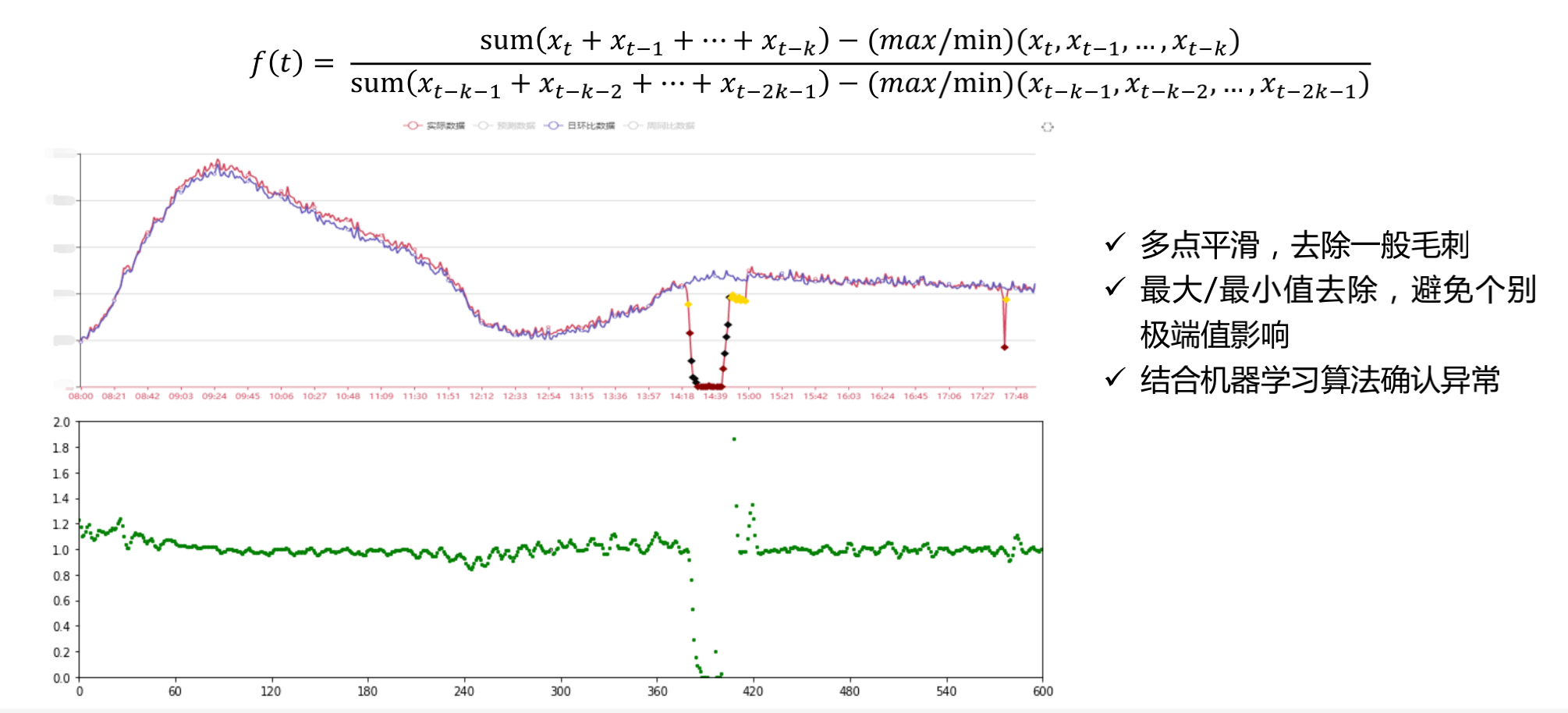
异常检测模型的普适性
模型在时间序列异常检测问题上表现出较好的普适性:
- 适用于不同数量级的数据;
- 适用于不同变化规律的数据;
- 适用于不同业务的数据;
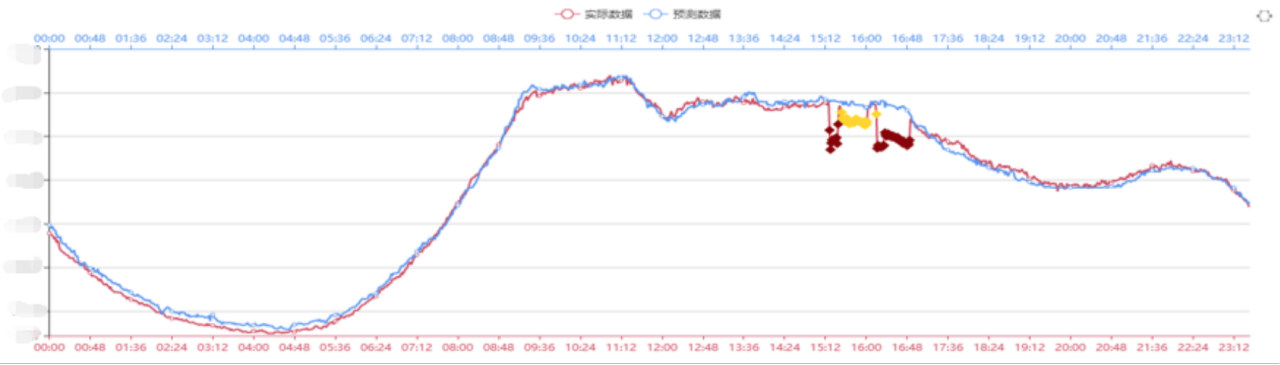
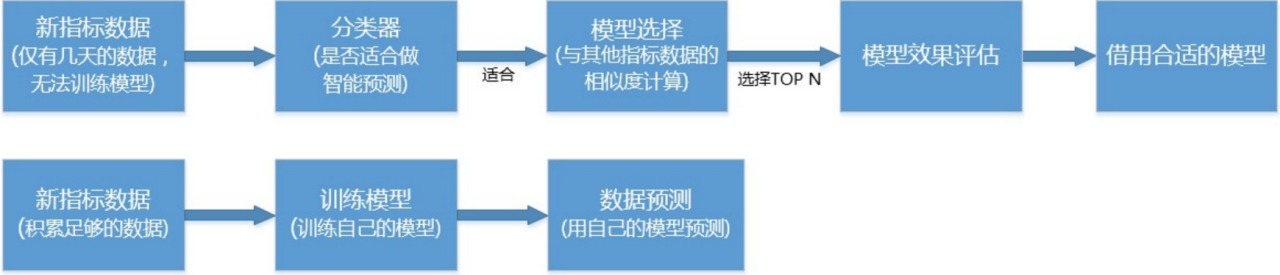
流量预测模型的个性化
网络流量预测->业务集群访问量预测(使用多个模型进行预测)
智能告警合并
智能故障告警——实现的基础
对告警的需求:
- 告警收敛
- 精准告警
告警发送策略:
- 告警分级:邮件->微信->短信->语音
- 连续m次异常则告警/在m分钟时间段内有n次异常则告警
- 告警间隔5分钟,最多告警n次
- 30分钟后未处理则升级,1天后未处理则提醒
- 告警升级后使用升级后的告警级别和接收人
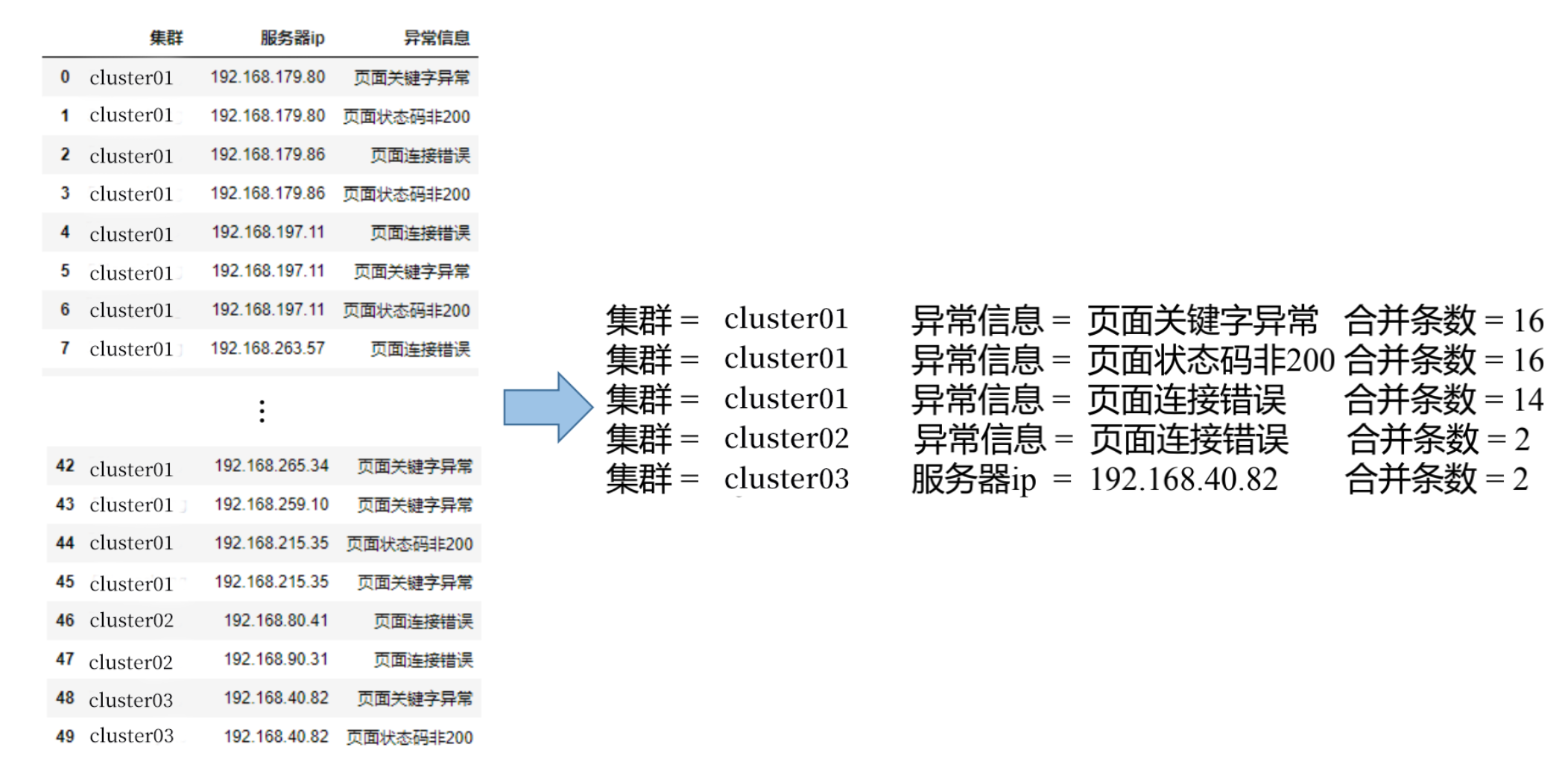
智能告警合并
合并时间窗口:
- 1分钟(可自定义)
合并策略:
- 根据集群合并
- 根据IP合并
- 根据网段合并
- 根据异常种类合并
- 根据宿主机与虚拟机的关系合并
合并收益:
- 避免海量告警轰炸
- 快速掌握故障情况
- 辅助决策故障根因
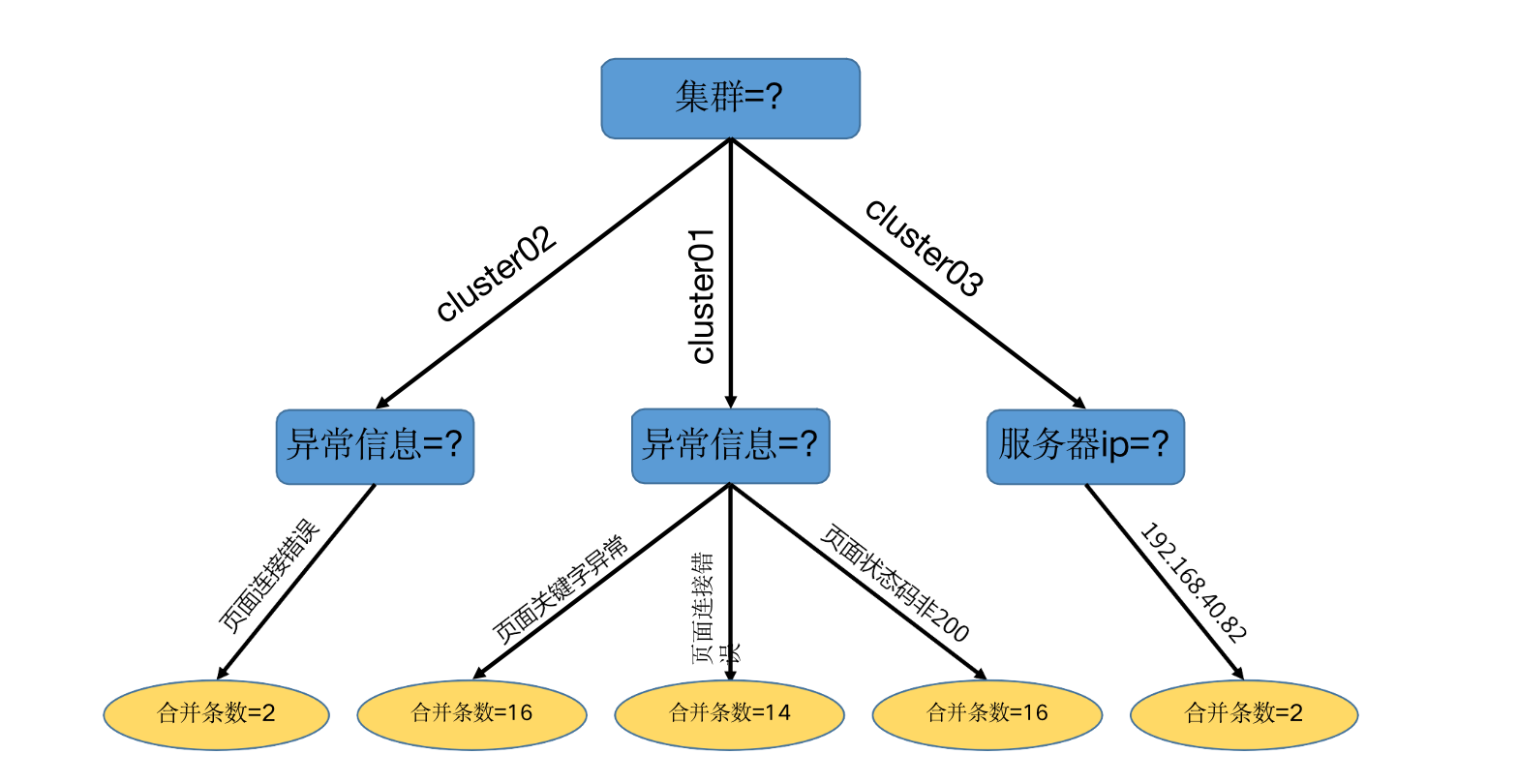
智能告警合并维度选择
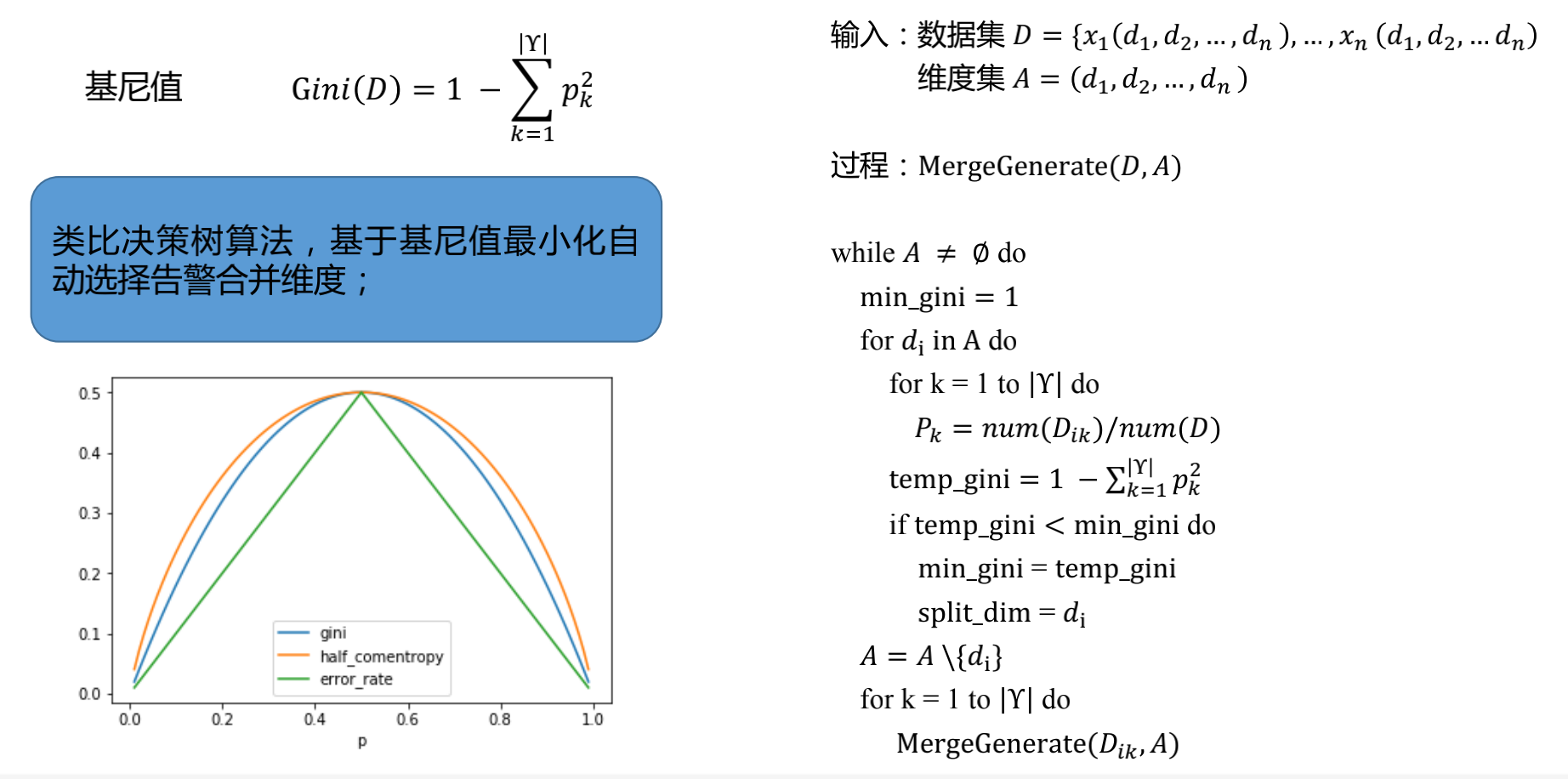
构建树形的算法:
- 遍历全部备选维度,确认当前合并维度;
- 基于合并维度划分数据集,继续选择合并维度;
- 到达停止条件后停止;
智能根因分析
智能根因分析——应用场景
周期变化业务指标突变的根因分析:
- 周期变化业务指标突变的根因分析
- 网络出口流量与业务集群访问量突变
- 多业务集群访问量突变
多层监控根因分析:
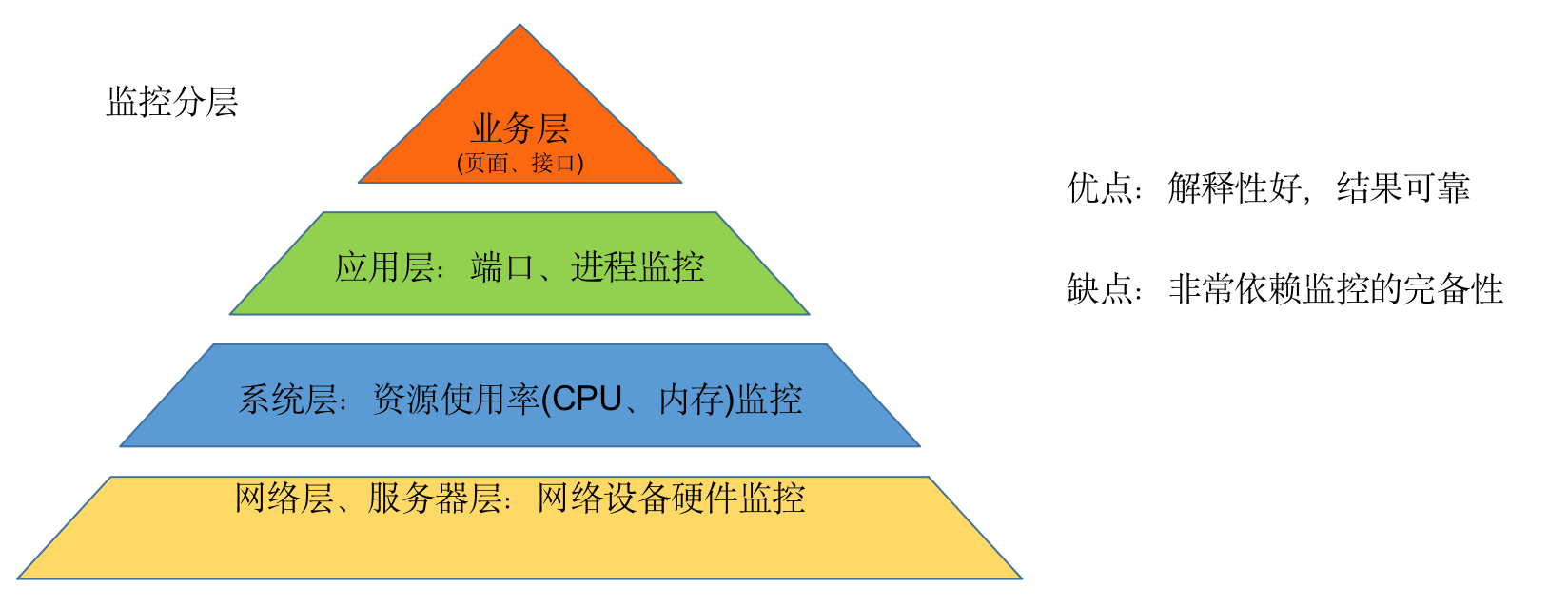
- 服务器层(宕机)、系统层(资源使用率)、服务层(端口、进程存活)、应用层(页面、接口)、 业务层(集群访问量)
基于调用链的根因分析:
- Nginx与业务集群
- 业务集群之间的调用
- 业务集群与存储服务的调用
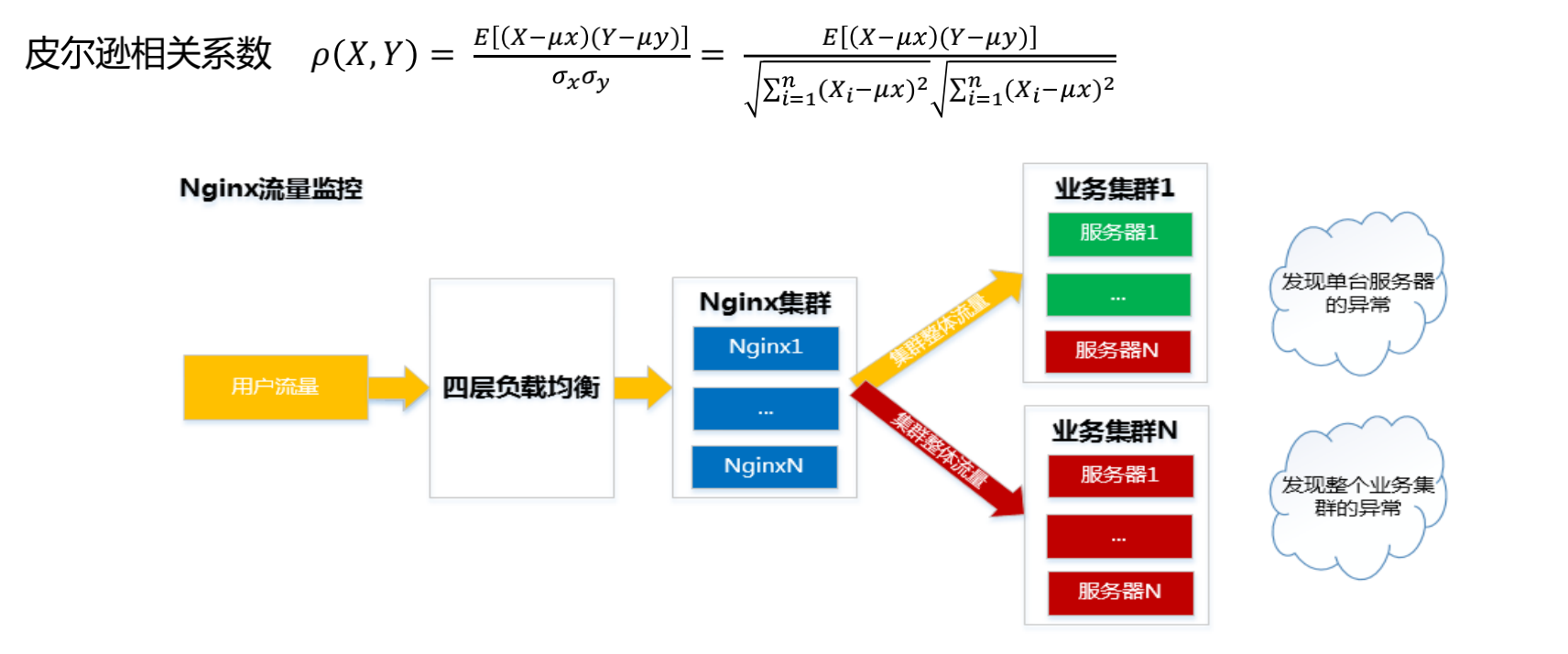
基于数据相关性分析
业务流量异常根因分析:异常发生时,基于流量/访问量曲线相关性定位异常根因。
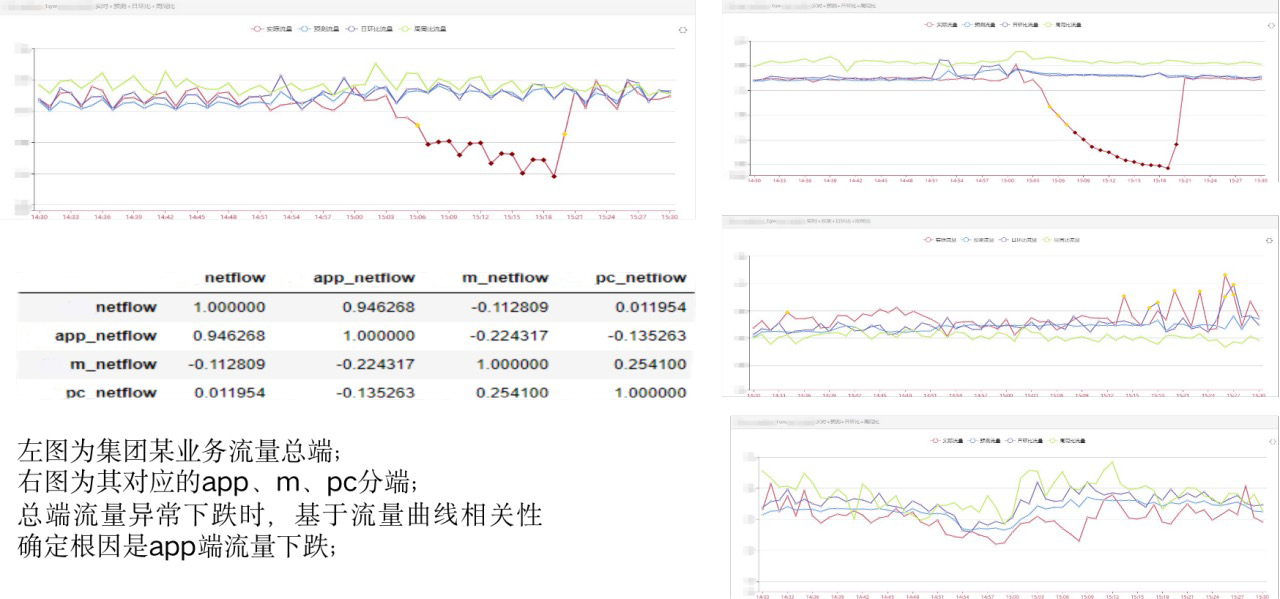
多业务网络流量的相关性分析:
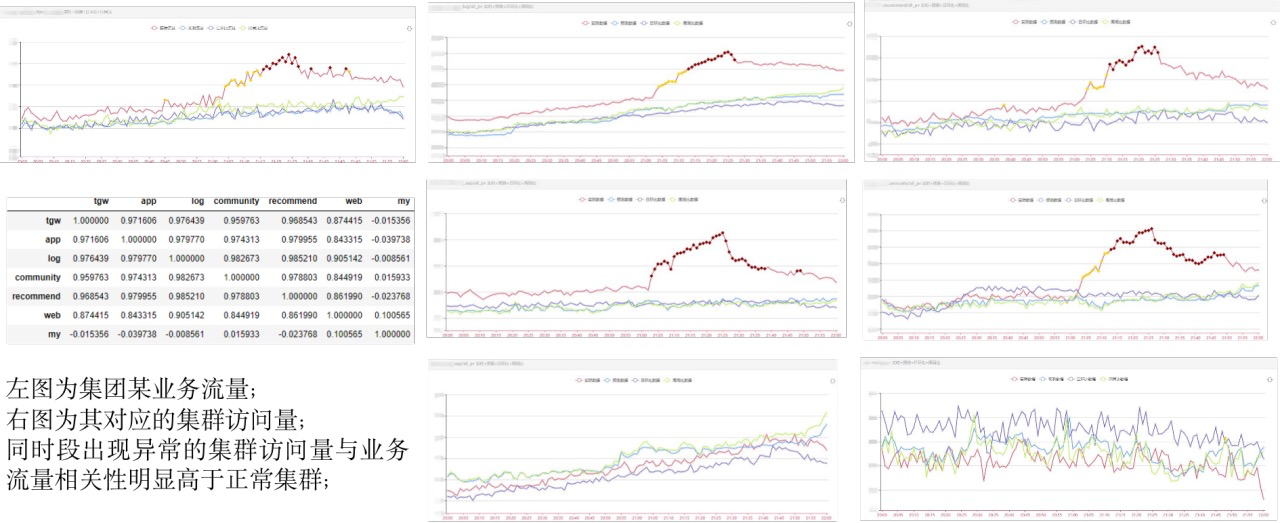
某业务流量与集群访问量的相关性分析:
基于告警信息提取
告警信息按层合并,异常发生时由上至下逐层获取告警信息,提取根因;
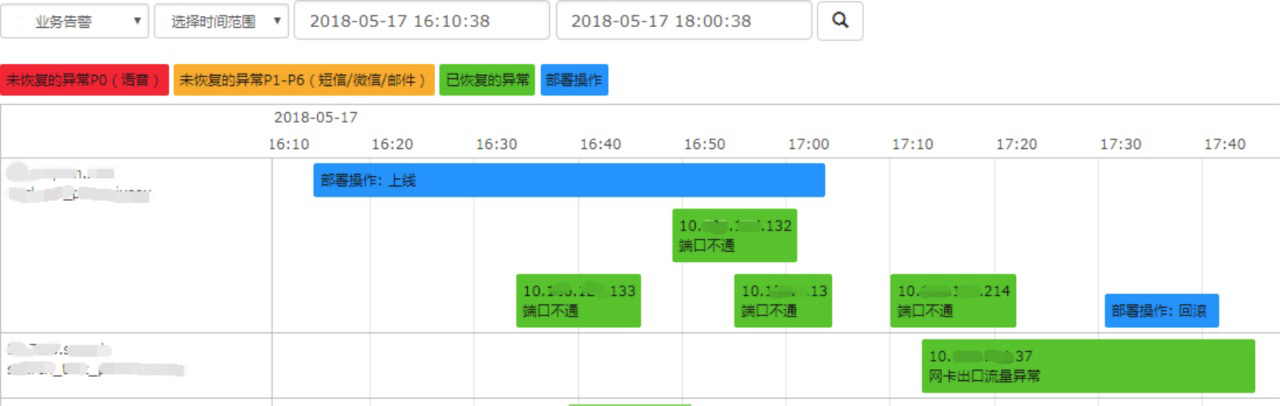
智能故障根因分析——可视化视图
异常辅助排查页面
展示:异常告警事件,部署上线事件
发现告警之间的关联,便于确定故障根因
智能故障根因分析-其他

智能故障自愈
故障自愈的策略
- 出现故障先不告警,自动执行预定义的一系列处理步骤,尝试自动处理故障。
- 如果故障自愈成功,那么无需发送告警。
- 如果故障自愈失败,按照预定义的方式发告警。
- 在合适的时间,将近期故障自愈的执行结果汇总后通知用户

执行简单命令
- 磁盘空间不足自动处理:删除预定义目录的文件。
- 服务挂掉自动拉起:执行重启服务的命令。
调用相关系统
- 服务器宕机自动处理:自动恢复;自动分配备机、部署服务、切流量。
- 负载升高自动扩容:调用部署系统和云平台。
- 流量自动调度:操作DNS、四层和七层负载均衡服务进行流量切换。
智能故障预警
智能故障预警
场景:接口、页面监控,业务集群访问错误率监控。
- 通过集群整体服务指标监控做故障告警
- 通过对集群中单机服务指标监控做预警
智能容量预警
- 根据集群中异常服务器比例评估容量风险。
- 根据流量变化风险评估容量风险。
- 根据流量变化风险评估容量风险。
智能硬件预警
- 基于硬件性能指标评估硬件损坏风险。