Linux 性能分析优化图谱
Linux 性能工具图谱
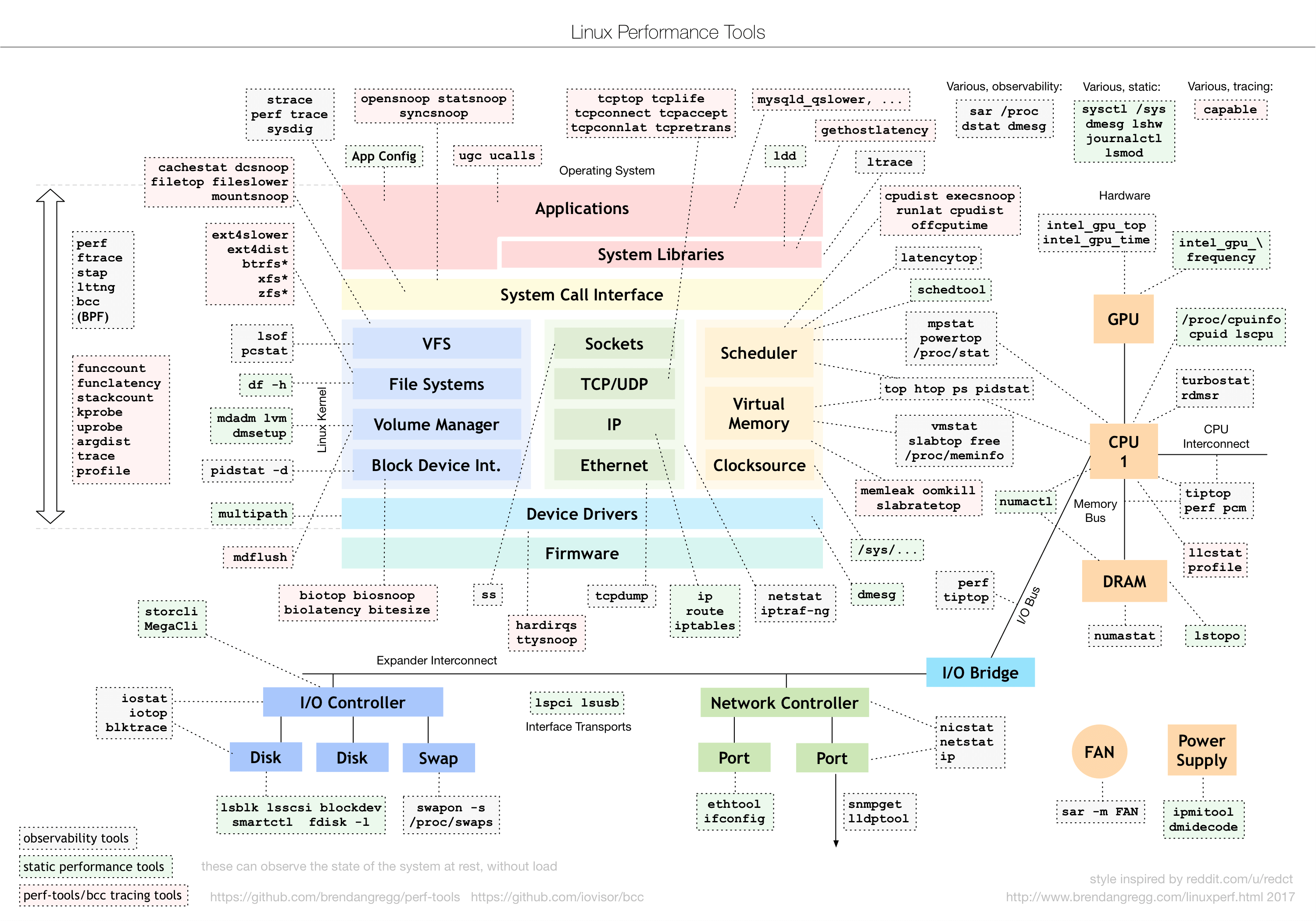
Linux 性能优化
CPU 相关
stress
stress 是一个 Linux 系统压力测试工具,可以用作异常进程模拟平均负载升高的场景。
模拟一个 CPU 使用率 100% 的场景:
$ stress --cpu 1 --timeout 600
模拟 I/O 压力,即不停地执行 sync:
$ stress -i 1 --timeout 600
模拟的是 8 个进程:
$ stress -c 8 --timeout 600
sysstat
sysstat 包含了常用的 Linux 性能工具,用来监控和分析系统的性能。
- mpstat 是一个常用的多核 CPU 性能分析工具,用来实时查看每个 CPU 的性能指标,以及所有 CPU 的平均指标。
运行 mpstat 查看 CPU 使用率的变化情况:
# -P ALL 表示监控所有CPU,后面数字5表示间隔5秒后输出一组数据
$ mpstat -P ALL 5
Linux 4.15.0 (ubuntu) 09/22/18 _x86_64_ (2 CPU)
13:30:06 CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle
13:30:11 all 50.05 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 49.95
13:30:11 0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 100.00
13:30:11 1 100.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
- pidstat 是一个常用的进程性能分析工具,用来实时查看进程的 CPU、内存、I/O 以及上下文切换等性能指标。
# 间隔5秒后输出一组数据
$ pidstat -u 5 1
13:37:07 UID PID %usr %system %guest %wait %CPU CPU Command
13:37:12 0 2962 100.00 0.00 0.00 0.00 100.00 1 stress
给它加上 -w 选项,你就可以查看每个进程上下文切换的情况了。
# 每隔5秒输出1组数据
$ pidstat -w 5
Linux 4.15.0 (ubuntu) 09/23/18 _x86_64_ (2 CPU)
08:18:26 UID PID cswch/s nvcswch/s Command
08:18:31 0 1 0.20 0.00 systemd
08:18:31 0 8 5.40 0.00 rcu_sched
...
- cswch ,表示每秒自愿上下文切换(voluntary context switches)的次数
- nvcswch ,表示每秒非自愿上下文切换(non voluntary context switches)的次数。
vmstat
vmstat 是一个常用的系统性能分析工具,主要用来分析系统的内存使用情况,也常用来分析 CPU 上下文切换和中断的次数。
# 每隔5秒输出1组数据
$ vmstat 5
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
0 0 0 7005360 91564 818900 0 0 0 0 25 33 0 0 100 0 0
- cs(context switch)是每秒上下文切换的次数。
- in(interrupt)则是每秒中断的次数。
- r(Running or Runnable)是就绪队列的长度,也就是正在运行和等待 CPU 的进程数。
- b(Blocked)则是处于不可中断睡眠状态的进程数。
vmstat 只给出了系统总体的上下文切换情况
sysbench
sysbench 是一个多线程的基准测试工具,一般用来评估不同系统参数下的数据库负载情况。
运行 sysbench ,模拟系统多线程调度的瓶颈:
# 以10个线程运行5分钟的基准测试,模拟多线程切换的问题
$ sysbench --threads=10 --max-time=300 threads run
/proc/interrupts
/proc 实际上是 Linux 的一个虚拟文件系统,用于内核空间与用户空间之间的通信。/proc/interrupts 就是这种通信机制的一部分,提供了一个只读的中断使用情况。
# -d 参数表示高亮显示变化的区域
$ watch -d cat /proc/interrupts
CPU0 CPU1
...
RES: 2450431 5279697 Rescheduling interrupts
...
CPU 使用率相关的重要指标
- user(通常缩写为 us),代表用户态 CPU 时间。注意,它不包括下面的 nice 时间,但包括了 guest 时间。
- nice(通常缩写为 ni),代表低优先级用户态 CPU 时间,也就是进程的 nice 值被调整为 1-19 之间时的 CPU 时间。这里注意,nice 可取值范围是 -20 到 19,数值越大,优先级反而越低。
- system(通常缩写为 sys),代表内核态 CPU 时间。
- idle(通常缩写为 id),代表空闲时间。注意,它不包括等待 I/O 的时间(iowait)。
- iowait(通常缩写为 wa),代表等待 I/O 的 CPU 时间。
- irq(通常缩写为 hi),代表处理硬中断的 CPU 时间。
- softirq(通常缩写为 si),代表处理软中断的 CPU 时间。
- steal(通常缩写为 st),代表当系统运行在虚拟机中的时候,被其他虚拟机占用的 CPU 时间。
- guest(通常缩写为 guest),代表通过虚拟化运行其他操作系统的时间,也就是运行虚拟机的 CPU 时间。
- guest_nice(通常缩写为 gnice),代表以低优先级运行虚拟机的时间。
CPU 使用率是最直观和最常用的系统性能指标,更是在排查性能问题时,通常会关注的第一个指标。所以要熟悉它的含义,尤其要弄清楚用户(%user)、Nice(%nice)、系统(%system) 、等待 I/O(%iowait) 、中断(%irq)以及软中断(%softirq)这几种不同 CPU 的使用率。比如说:
- 用户 CPU 和 Nice CPU 高,说明用户态进程占用了较多的 CPU,所以应该着重排查进程的性能问题。
- 系统 CPU 高,说明内核态占用了较多的 CPU,所以应该着重排查内核线程或者系统调用的性能问题。
- I/O 等待 CPU 高,说明等待 I/O 的时间比较长,所以应该着重排查系统存储是不是出现了 I/O 问题。
- 软中断和硬中断高,说明软中断或硬中断的处理程序占用了较多的 CPU,所以应该着重排查内核中的中断服务程序。
碰到 CPU 使用率升高的问题,你可以借助 top、pidstat 等工具,确认引发 CPU 性能问题的来源;再使用 perf 等工具,排查出引起性能问题的具体函数。
查看 CPU 使用率的工具
top 和 ps 是最常用的性能分析工具:
- top 显示了系统总体的 CPU 和内存使用情况,以及各个进程的资源使用情况。
$ top
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
28961 root 20 0 43816 3148 4040 R 3.2 0.0 0:00.01 top
620 root 20 0 37280 33676 908 D 0.3 0.4 0:00.01 app
1 root 20 0 160072 9416 6752 S 0.0 0.1 0:37.64 systemd
1896 root 20 0 0 0 0 Z 0.0 0.0 0:00.00 devapp
2 root 20 0 0 0 0 S 0.0 0.0 0:00.10 kthreadd
4 root 0 -20 0 0 0 I 0.0 0.0 0:00.00 kworker/0:0H
6 root 0 -20 0 0 0 I 0.0 0.0 0:00.00 mm_percpu_wq
7 root 20 0 0 0 0 S 0.0 0.0 0:06.37 ksoftirqd/0
S 列(也就是 Status 列)表示进程的状态。从这个示例里,你可以看到 R、D、Z、S、I 等几个状态,它们分别是:
- R 是 Running 或 Runnable 的缩写,表示进程在 CPU 的就绪队列中,正在运行或者正在等待运行。
- D 是 Disk Sleep 的缩写,也就是不可中断状态睡眠(Uninterruptible Sleep),一般表示进程正在跟硬件交互,并且交互过程不允许被其他进程或中断打断。
- Z 是 Zombie 的缩写,如果你玩过“植物大战僵尸”这款游戏,应该知道它的意思。它表示僵尸进程,也就是进程实际上已经结束了,但是父进程还没有回收它的资源(比如进程的描述符、PID 等)。
- S 是 Interruptible Sleep 的缩写,也就是可中断状态睡眠,表示进程因为等待某个事件而被系统挂起。当进程等待的事件发生时,它会被唤醒并进入 R 状态。
- I 是 Idle 的缩写,也就是空闲状态,用在不可中断睡眠的内核线程上。前面说了,硬件交互导致的不可中断进程用 D 表示,但对某些内核线程来说,它们有可能实际上并没有任何负载,用 Idle 正是为了区分这种情况。要注意,D 状态的进程会导致平均负载升高, I 状态的进程却不会。
- T 或者 t,也就是 Stopped 或 Traced 的缩写,表示进程处于暂停或者跟踪状态。
- X,也就是 Dead 的缩写,表示进程已经消亡,所以你不会在 top 或者 ps 命令中看到它。
- ps 则只显示了每个进程的资源使用情况。
还有上面的pidstat
perf 分析进程的 CPU 问题
perf 是 Linux 2.6.31 以后内置的性能分析工具。它以性能事件采样为基础,不仅可以分析系统的各种事件和内核性能,还可以用来分析指定应用程序的性能问题。
第一种常见用法是 perf top,类似于 top,它能够实时显示占用 CPU 时钟最多的函数或者指令,因此可以用来查找热点函数,使用界面如下所示:
$ perf top
Samples: 833 of event 'cpu-clock', Event count (approx.): 97742399
Overhead Shared Object Symbol
7.28% perf [.] 0x00000000001f78a4
4.72% [kernel] [k] vsnprintf
4.32% [kernel] [k] module_get_kallsym
3.65% [kernel] [k] _raw_spin_unlock_irqrestore
...
输出结果中,第一行包含三个数据,分别是采样数(Samples)、事件类型(event)和事件总数量(Event count)。比如这个例子中,perf 总共采集了 833 个 CPU 时钟事件,而总事件数则为 97742399。
另外,采样数需要我们特别注意。如果采样数过少(比如只有十几个),那下面的排序和百分比就没什么实际参考价值了。
再往下看是一个表格式样的数据,每一行包含四列,分别是:
- 第一列 Overhead ,是该符号的性能事件在所有采样中的比例,用百分比来表示。
- 第二列 Shared ,是该函数或指令所在的动态共享对象(Dynamic Shared Object),如内核、进程名、动态链接库名、内核模块名等。
- 第三列 Object ,是动态共享对象的类型。比如 [.] 表示用户空间的可执行程序、或者动态链接库,而 [k] 则表示内核空间。
- 最后一列 Symbol 是符号名,也就是函数名。当函数名未知时,用十六进制的地址来表示。
第二种常见用法,也就是 perf record 和 perf report。 perf top 虽然实时展示了系统的性能信息,但它的缺点是并不保存数据,也就无法用于离线或者后续的分析。而 perf record 则提供了保存数据的功能,保存后的数据,需要你用 perf report 解析展示。
$ perf record # 按Ctrl+C终止采样
[ perf record: Woken up 1 times to write data ]
[ perf record: Captured and wrote 0.452 MB perf.data (6093 samples) ]
$ perf report # 展示类似于perf top的报告
在实际使用中,我们还经常为 perf top 和 perf record 加上 -g 参数,开启调用关系的采样,方便我们根据调用链来分析性能问题。
ab(apache bench)
ab(apache bench)是一个常用的 HTTP 服务性能测试工具,可以用来模拟 Ngnix 的客户端。
# 并发10个请求测试Nginx性能,总共测试100个请求
$ ab -c 10 -n 100 http://192.168.0.10:10000/
This is ApacheBench, Version 2.3 <$Revision: 1706008 $>
Copyright 1996 Adam Twiss, Zeus Technology Ltd,
...
Requests per second: 11.63 [#/sec] (mean)
Time per request: 859.942 [ms] (mean)
...
execsnoop
execsnoop 是一个专为短时进程设计的工具。它通过 ftrace 实时监控进程的 exec() 行为,并输出短时进程的基本信息,包括进程 PID、父进程 PID、命令行参数以及执行的结果。
# 按 Ctrl+C 结束
$ execsnoop
PCOMM PID PPID RET ARGS
sh 30394 30393 0
stress 30396 30394 0 /usr/local/bin/stress -t 1 -d 1
sh 30398 30393 0
stress 30399 30398 0 /usr/local/bin/stress -t 1 -d 1
sh 30402 30400 0
stress 30403 30402 0 /usr/local/bin/stress -t 1 -d 1
sh 30405 30393 0
stress 30407 30405 0 /usr/local/bin/stress -t 1 -d 1
...
execsnoop 所用的 ftrace 是一种常用的动态追踪技术,一般用于分析 Linux 内核的运行时行为。
dstat
dstat 是一个新的性能工具,它吸收了 vmstat、iostat、ifstat 等几种工具的优点,可以同时观察系统的 CPU、磁盘 I/O、网络以及内存使用情况。
# 间隔1秒输出10组数据
$ dstat 1 10
You did not select any stats, using -cdngy by default.
--total-cpu-usage-- -dsk/total- -net/total- ---paging-- ---system--
usr sys idl wai stl| read writ| recv send| in out | int csw
0 0 96 4 0|1219k 408k| 0 0 | 0 0 | 42 885
0 0 2 98 0| 34M 0 | 198B 790B| 0 0 | 42 138
0 0 0 100 0| 34M 0 | 66B 342B| 0 0 | 42 135
0 0 84 16 0|5633k 0 | 66B 342B| 0 0 | 52 177
0 3 39 58 0| 22M 0 | 66B 342B| 0 0 | 43 144
0 0 0 100 0| 34M 0 | 200B 450B| 0 0 | 46 147
0 0 2 98 0| 34M 0 | 66B 342B| 0 0 | 45 134
0 0 0 100 0| 34M 0 | 66B 342B| 0 0 | 39 131
0 0 83 17 0|5633k 0 | 66B 342B| 0 0 | 46 168
0 3 39 59 0| 22M 0 | 66B 342B| 0 0 | 37 134
strace
strace 是最常用的跟踪进程系统调用的工具。
从 pidstat 的输出中拿到进程的 PID 号,比如 6082,然后在终端中运行 strace 命令,并用 -p 参数指定 PID 号:
$ strace -p 6082
strace: attach: ptrace(PTRACE_SEIZE, 6082): Operation not permitted
/proc/softirqs 提供了软中断的运行情况;
运行下面的命令,查看 /proc/softirqs 文件的内容,你就可以看到各种类型软中断在不同 CPU 上的累积运行次数:
$ cat /proc/softirqs
CPU0 CPU1
HI: 0 0
TIMER: 811613 1972736
NET_TX: 49 7
NET_RX: 1136736 1506885
BLOCK: 0 0
IRQ_POLL: 0 0
TASKLET: 304787 3691
SCHED: 689718 1897539
HRTIMER: 0 0
RCU: 1330771 1354737
在查看 /proc/softirqs 文件内容时,你要特别注意以下这两点。
第一,要注意软中断的类型,也就是这个界面中第一列的内容。从第一列你可以看到,软中断包括了 10 个类别,分别对应不同的工作类型。比如 NET_RX 表示网络接收中断,而 NET_TX 表示网络发送中断。
第二,要注意同一种软中断在不同 CPU 上的分布情况,也就是同一行的内容。正常情况下,同一种中断在不同 CPU 上的累积次数应该差不多。比如这个界面中,NET_RX 在 CPU0 和 CPU1 上的中断次数基本是同一个数量级,相差不大。
sar
sar 是一个系统活动报告工具,既可以实时查看系统的当前活动,又可以配置保存和报告历史统计数据。
sar 可以用来查看系统的网络收发情况,还有一个好处是,不仅可以观察网络收发的吞吐量(BPS,每秒收发的字节数),还可以观察网络收发的 PPS,即每秒收发的网络帧数。
# -n DEV 表示显示网络收发的报告,间隔1秒输出一组数据
$ sar -n DEV 1
15:03:46 IFACE rxpck/s txpck/s rxkB/s txkB/s rxcmp/s txcmp/s rxmcst/s %ifutil
15:03:47 eth0 12607.00 6304.00 664.86 358.11 0.00 0.00 0.00 0.01
15:03:47 docker0 6302.00 12604.00 270.79 664.66 0.00 0.00 0.00 0.00
15:03:47 lo 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
15:03:47 veth9f6bbcd 6302.00 12604.00 356.95 664.66 0.00 0.00 0.00 0.05
从左往右依次是:
- 第一列:表示报告的时间。
- 第二列:IFACE 表示网卡。
- 第三、四列:rxpck/s 和 txpck/s 分别表示每秒接收、发送的网络帧数,也就是 PPS。
- 第五、六列:rxkB/s 和 txkB/s 分别表示每秒接收、发送的千字节数,也就是 BPS。
hping3
hping3 是一个可以构造 TCP/IP 协议数据包的工具,可以对系统进行安全审计、防火墙测试等。
模拟 Nginx 的客户端请求:
# -S参数表示设置TCP协议的SYN(同步序列号),-p表示目的端口为80
# -i u100表示每隔100微秒发送一个网络帧
# 注:如果你在实践过程中现象不明显,可以尝试把100调小,比如调成10甚至1
$ hping3 -S -p 80 -i u100 192.168.0.30
tcpdump
tcpdump 是一个常用的网络抓包工具,常用来分析各种网络问题。
# -i eth0 只抓取eth0网卡,-n不解析协议名和主机名
# tcp port 80表示只抓取tcp协议并且端口号为80的网络帧
$ tcpdump -i eth0 -n tcp port 80
15:11:32.678966 IP 192.168.0.2.18238 > 192.168.0.30.80: Flags [S], seq 458303614, win 512, length 0
...
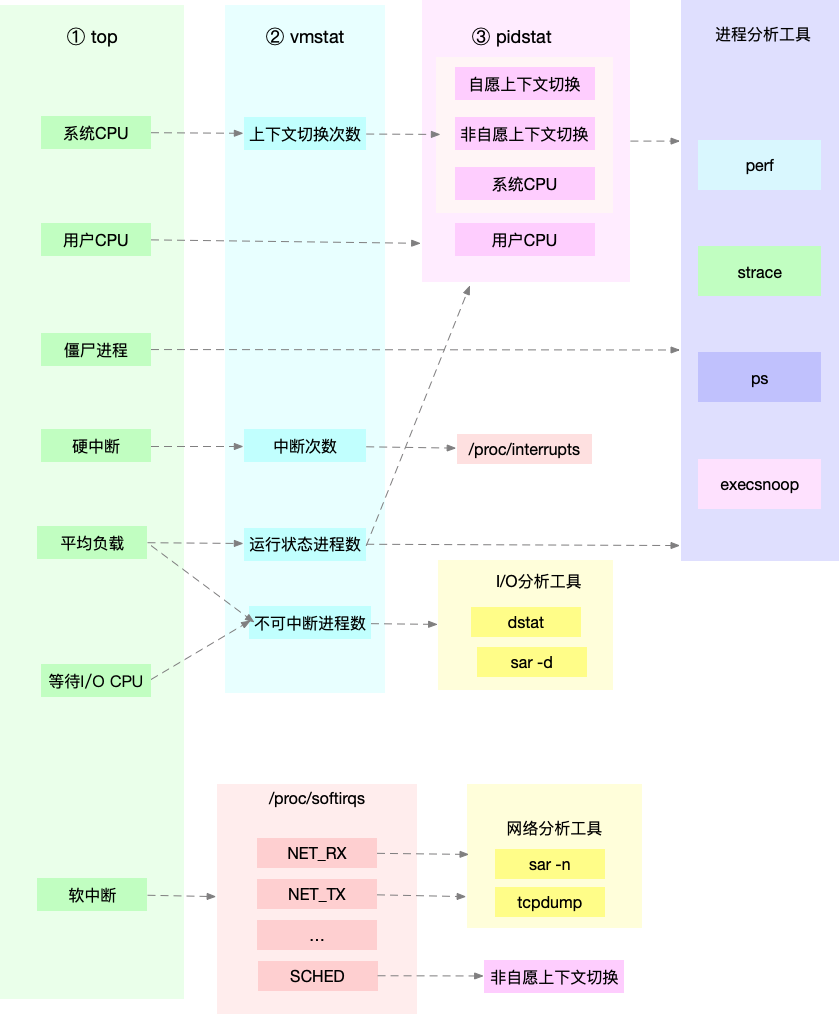
CPU 性能指标工具
又快又准找出系统瓶颈?CPU 性能分析的思路图谱
CPU 优化
应用程序优化
首先,从应用程序的角度来说,降低 CPU 使用率的最好方法当然是,排除所有不必要的工作,只保留最核心的逻辑。比如减少循环的层次、减少递归、减少动态内存分配等等
除此之外,应用程序的性能优化也包括很多种方法,这里列出了最常见的几种:
- 编译器优化:很多编译器都会提供优化选项,适当开启它们,在编译阶段你就可以获得编译器的帮助,来提升性能。比如, gcc 就提供了优化选项 -O2,开启后会自动对应用程序的代码进行优化。
- 算法优化:使用复杂度更低的算法,可以显著加快处理速度。比如,在数据比较大的情况下,可以用 O(nlogn) 的排序算法(如快排、归并排序等),代替 O(n^2) 的排序算法(如冒泡、插入排序等)。
- 异步处理:使用异步处理,可以避免程序因为等待某个资源而一直阻塞,从而提升程序的并发处理能力。比如,把轮询替换为事件通知,就可以避免轮询耗费 CPU 的问题。
- 多线程代替多进程:前面讲过,相对于进程的上下文切换,线程的上下文切换并不切换进程地址空间,因此可以降低上下文切换的成本。
- 善用缓存:经常访问的数据或者计算过程中的步骤,可以放到内存中缓存起来,这样在下次用时就能直接从内存中获取,加快程序的处理速度。
系统优化
从系统的角度来说,优化 CPU 的运行,一方面要充分利用 CPU 缓存的本地性,加速缓存访问;另一方面,就是要控制进程的 CPU 使用情况,减少进程间的相互影响。
具体来说,系统层面的 CPU 优化方法也有不少,这里列举了最常见的一些方法:
- CPU 绑定:把进程绑定到一个或者多个 CPU 上,可以提高 CPU 缓存的命中率,减少跨 CPU 调度带来的上下文切换问题。
- CPU 独占:跟 CPU 绑定类似,进一步将 CPU 分组,并通过 CPU 亲和性机制为其分配进程。这样,这些 CPU 就由指定的进程独占,换句话说,不允许其他进程再来使用这些 CPU。
- 优先级调整:使用 nice 调整进程的优先级,正值调低优先级,负值调高优先级。优先级的数值含义前面我们提到过,忘了的话及时复习一下。在这里,适当降低非核心应用的优先级,增高核心应用的优先级,可以确保核心应用得到优先处理。
- 为进程设置资源限制:使用 Linux cgroups 来设置进程的 CPU 使用上限,可以防止由于某个应用自身的问题,而耗尽系统资源。
- NUMA(Non-Uniform Memory Access)优化:支持 NUMA 的处理器会被划分为多个 node,每个 node 都有自己的本地内存空间。NUMA 优化,其实就是让 CPU 尽可能只访问本地内存。
- 中断负载均衡:无论是软中断还是硬中断,它们的中断处理程序都可能会耗费大量的 CPU。开启 irqbalance 服务或者配置 smp_affinity,就可以把中断处理过程自动负载均衡到多个 CPU 上。
内存相关
free
# 注意不同版本的free输出可能会有所不同
$ free
total used free shared buff/cache available
Mem: 8169348 263524 6875352 668 1030472 7611064
Swap: 0 0 0
你可以看到,free 输出的是一个表格,其中的数值都默认以字节为单位。表格总共有两行六列,这两行分别是物理内存 Mem 和交换分区 Swap 的使用情况,而六列中,每列数据的含义分别为:
- 第一列,total 是总内存大小;
- 第二列,used 是已使用内存的大小,包含了共享内存;
- 第三列,free 是未使用内存的大小;
- 第四列,shared 是共享内存的大小;
- 第五列,buff/cache 是缓存和缓冲区的大小;
- 最后一列,available 是新进程可用内存的大小。
available 不仅包含未使用内存,还包括了可回收的缓存,所以一般会比未使用内存更大。
关于buffer 和 cache 的说明:
- Buffers 是内核缓冲区用到的内存,对应的是 /proc/meminfo 中的 Buffers 值。既可以用作“将要写入磁盘数据的缓存”,也可以用作“从磁盘读取数据的缓存”。
- Cache 是内核页缓存和 Slab 用到的内存,对应的是 /proc/meminfo 中的 Cached 与 SReclaimable 之和。既可以用作“从文件读取数据的页缓存”,也可以用作“写文件的页缓存”。
简单来说,Buffer 是对磁盘数据的缓存,而 Cache 是文件数据的缓存,它们既会用在读请求中,也会用在写请求中。
使用 top 查看进程的内存使用情况
# 按下M切换到内存排序
$ top
...
KiB Mem : 8169348 total, 6871440 free, 267096 used, 1030812 buff/cache
KiB Swap: 0 total, 0 free, 0 used. 7607492 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
430 root 19 -1 122360 35588 23748 S 0.0 0.4 0:32.17 systemd-journal
1075 root 20 0 771860 22744 11368 S 0.0 0.3 0:38.89 snapd
1048 root 20 0 170904 17292 9488 S 0.0 0.2 0:00.24 networkd-dispat
1 root 20 0 78020 9156 6644 S 0.0 0.1 0:22.92 systemd
12376 azure 20 0 76632 7456 6420 S 0.0 0.1 0:00.01 systemd
12374 root 20 0 107984 7312 6304 S 0.0 0.1 0:00.00 sshd
...
VIRT、RES、SHR 以及 %MEM等数据,包含了进程最重要的几个内存使用情况
- VIRT 是进程虚拟内存的大小,只要是进程申请过的内存,即便还没有真正分配物理内存,也会计算在内。
- RES 是常驻内存的大小,也就是进程实际使用的物理内存大小,但不包括 Swap 和共享内存。
- SHR 是共享内存的大小,比如与其他进程共同使用的共享内存、加载的动态链接库以及程序的代码段等。
- %MEM 是进程使用物理内存占系统总内存的百分比。
查看 top 输出时,需要注意两点:
第一,虚拟内存通常并不会全部分配物理内存。从上面的输出,你可以发现每个进程的虚拟内存都比常驻内存大得多。
第二,共享内存 SHR 并不一定是共享的,比方说,程序的代码段、非共享的动态链接库,也都算在 SHR 里。当然,SHR 也包括了进程间真正共享的内存。所以在计算多个进程的内存使用时,不要把所有进程的 SHR 直接相加得出结果。
查看系统缓存命中情况的工具,cachestat 和 cachetop。
- cachestat 提供了整个操作系统缓存的读写命中情况。
- cachetop 提供了每个进程的缓存命中情况。
这两个工具都是 bcc 软件包的一部分。
bcc 提供的所有工具就都安装到 /usr/share/bcc/tools 这个目录中了。不过这里提醒你,bcc 软件包默认不会把这些工具配置到系统的 PATH 路径中,所以你得自己手动配置。
cachestat 的运行界面,它以 1 秒的时间间隔,输出了 3 组缓存统计数据:
$ cachestat 1 3
TOTAL MISSES HITS DIRTIES BUFFERS_MB CACHED_MB
2 0 2 1 17 279
2 0 2 1 17 279
2 0 2 1 17 279
- TOTAL ,表示总的 I/O 次数;
- MISSES ,表示缓存未命中的次数;
- HITS ,表示缓存命中的次数;
- DIRTIES, 表示新增到缓存中的脏页数;
- BUFFERS_MB 表示 Buffers 的大小,以 MB 为单位;
- CACHED_MB 表示 Cache 的大小,以 MB 为单位。
cachetop 的运行界面:
$ cachetop
11:58:50 Buffers MB: 258 / Cached MB: 347 / Sort: HITS / Order: ascending
PID UID CMD HITS MISSES DIRTIES READ_HIT% WRITE_HIT%
13029 root python 1 0 0 100.0% 0.0%
它的输出跟 top 类似,默认按照缓存的命中次数(HITS)排序,展示了每个进程的缓存命中情况。具体到每一个指标,这里的 HITS、MISSES 和 DIRTIES ,跟 cachestat 里的含义一样,分别代表间隔时间内的缓存命中次数、未命中次数以及新增到缓存中的脏页数。
而 READ_HIT 和 WRITE_HIT ,分别表示读和写的缓存命中率。
查看文件在内存中的缓存大小以及缓存比例 pcstat。
pcstat 运行的示例,它展示了 /bin/ls 这个文件的缓存情况:
$ pcstat /bin/ls
+---------+----------------+------------+-----------+---------+
| Name | Size (bytes) | Pages | Cached | Percent |
|---------+----------------+------------+-----------+---------|
| /bin/ls | 133792 | 33 | 0 | 000.000 |
+---------+----------------+------------+-----------+---------+
这个输出中,Cached 就是 /bin/ls 在缓存中的大小,而 Percent 则是缓存的百分比。你看到它们都是 0,这说明 /bin/ls 并不在缓存中。
memleak 专门用来检测内存泄漏的工具
memleak 可以跟踪系统或指定进程的内存分配、释放请求,然后定期输出一个未释放内存和相应调用栈的汇总情况(默认 5 秒)。
memleak 是 bcc 软件包中的一个工具
# -a 表示显示每个内存分配请求的大小以及地址
# -p 指定案例应用的PID号
$ /usr/share/bcc/tools/memleak -a -p $(pidof app)
WARNING: Couldn't find .text section in /app
WARNING: BCC can't handle sym look ups for /app
addr = 7f8f704732b0 size = 8192
addr = 7f8f704772d0 size = 8192
addr = 7f8f704712a0 size = 8192
addr = 7f8f704752c0 size = 8192
32768 bytes in 4 allocations from stack
[unknown] [app]
[unknown] [app]
start_thread+0xdb [libpthread-2.27.so]
内存性能指标
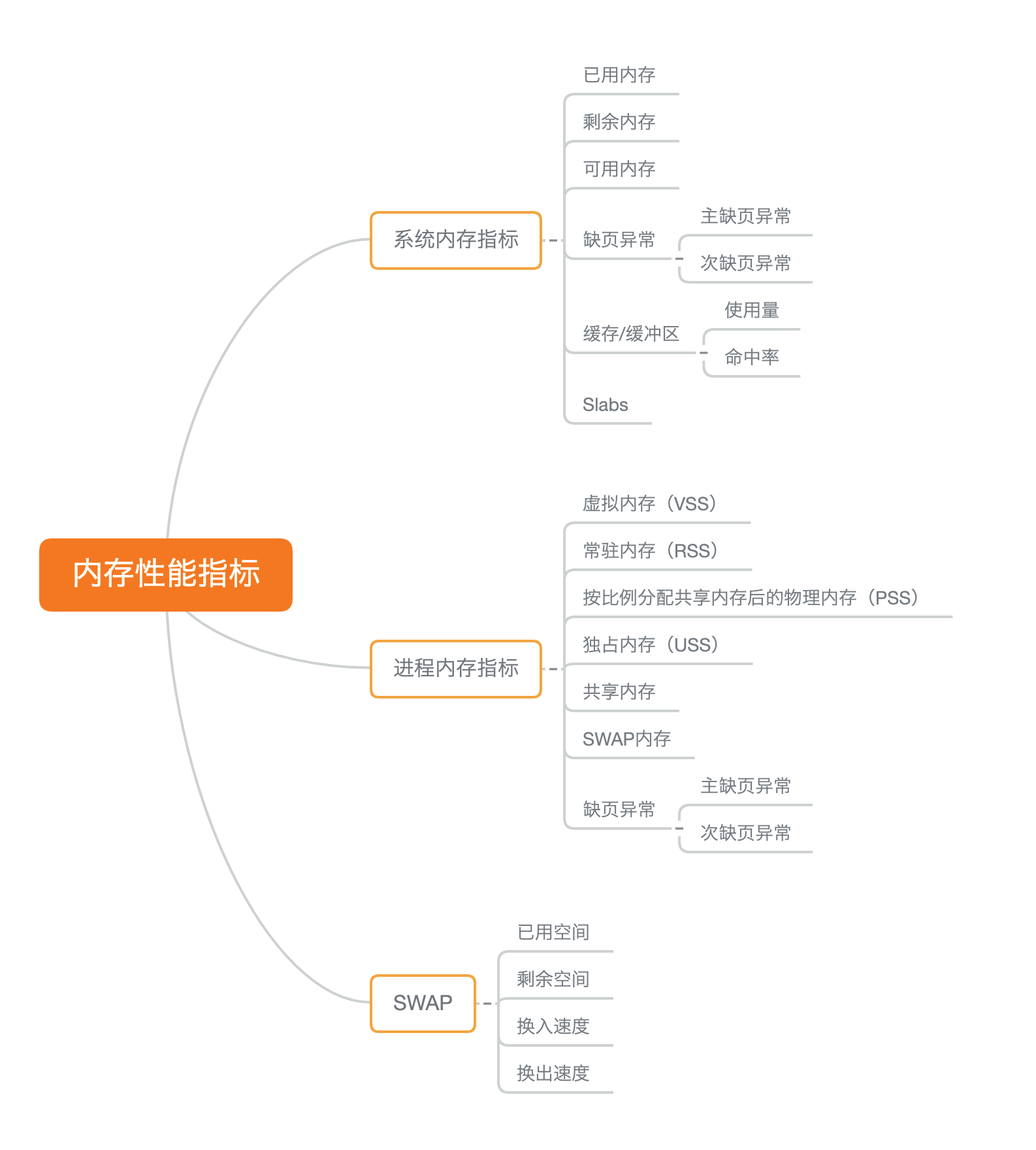
内存性能工具
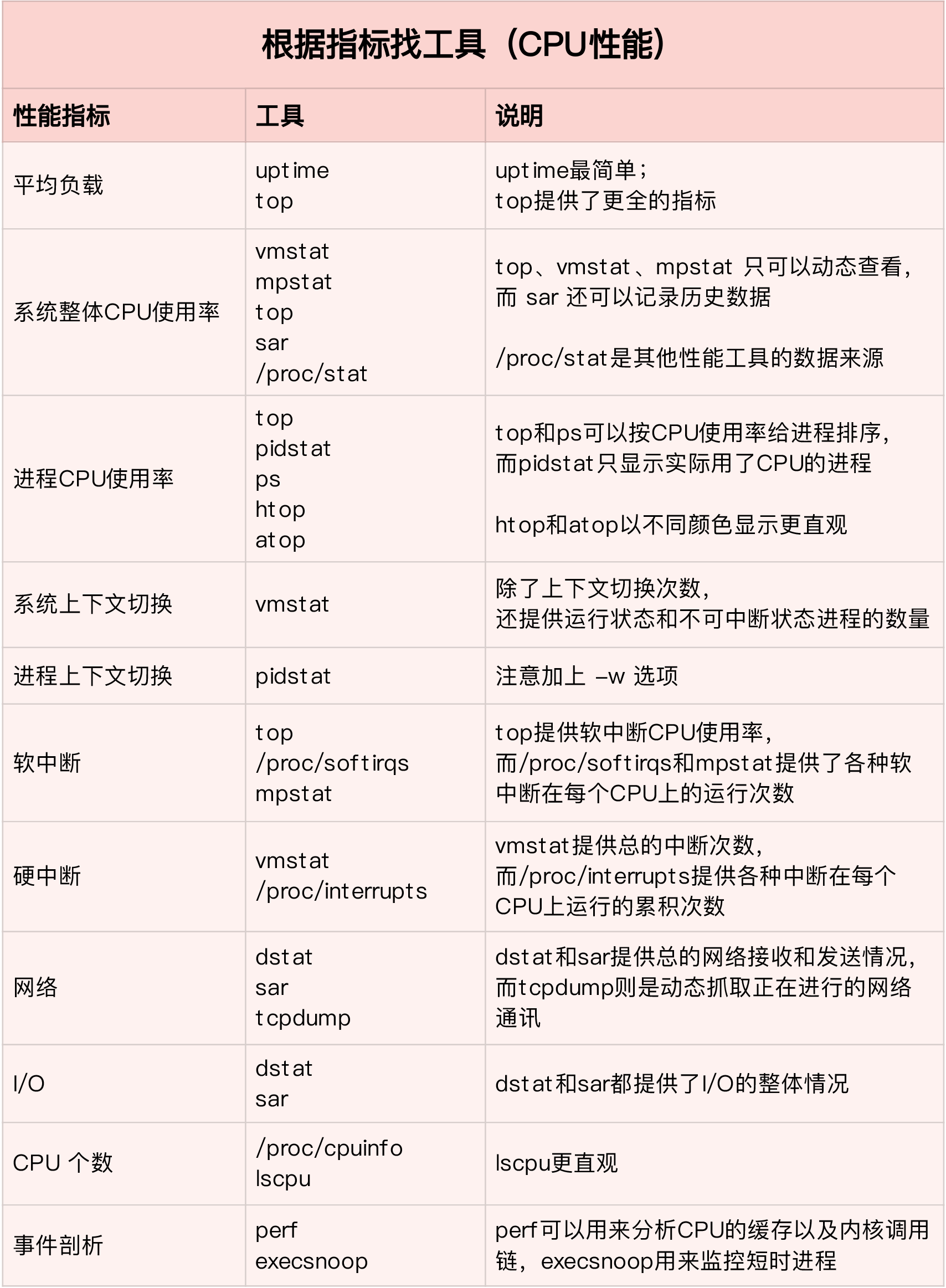
根据指标找工具
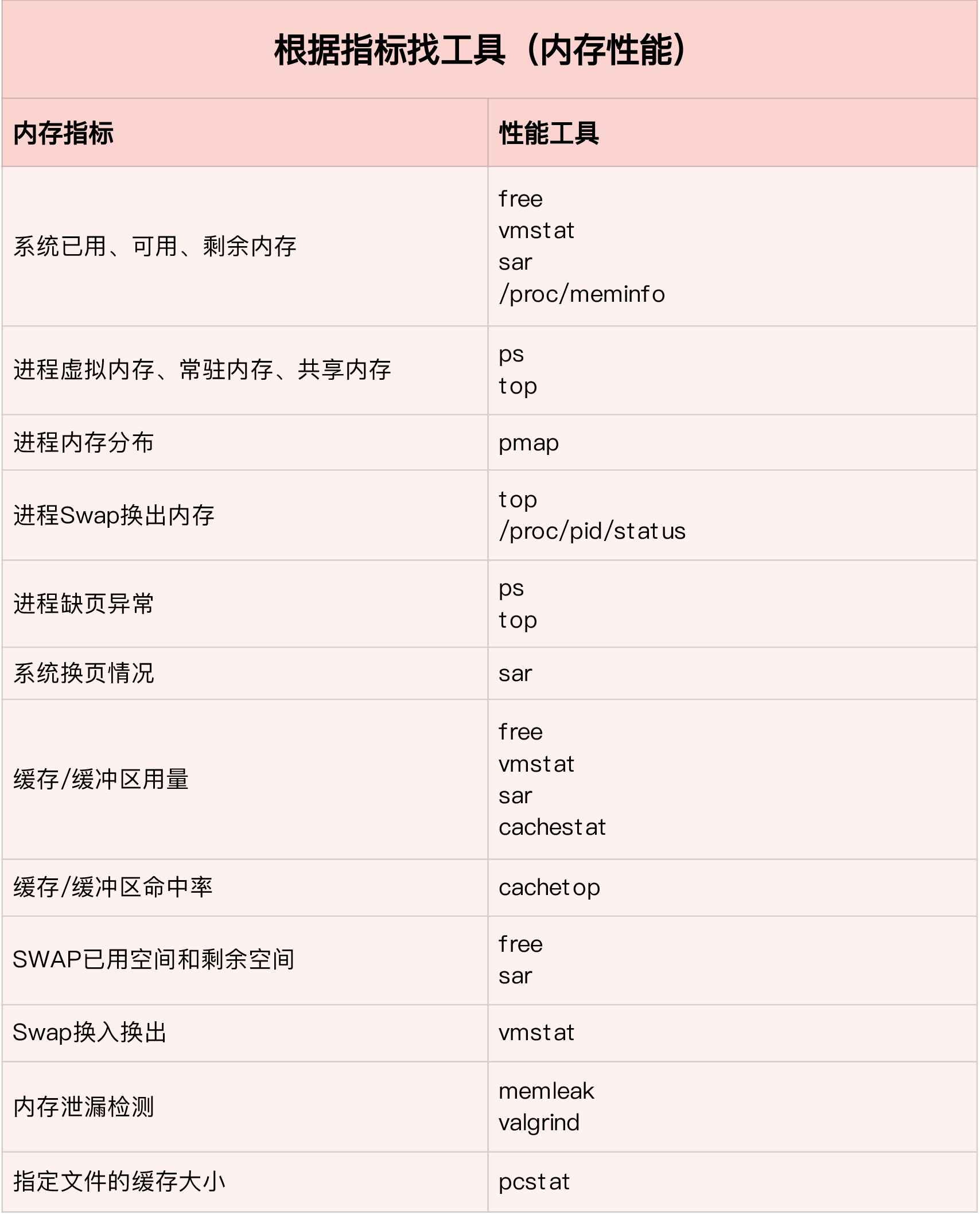
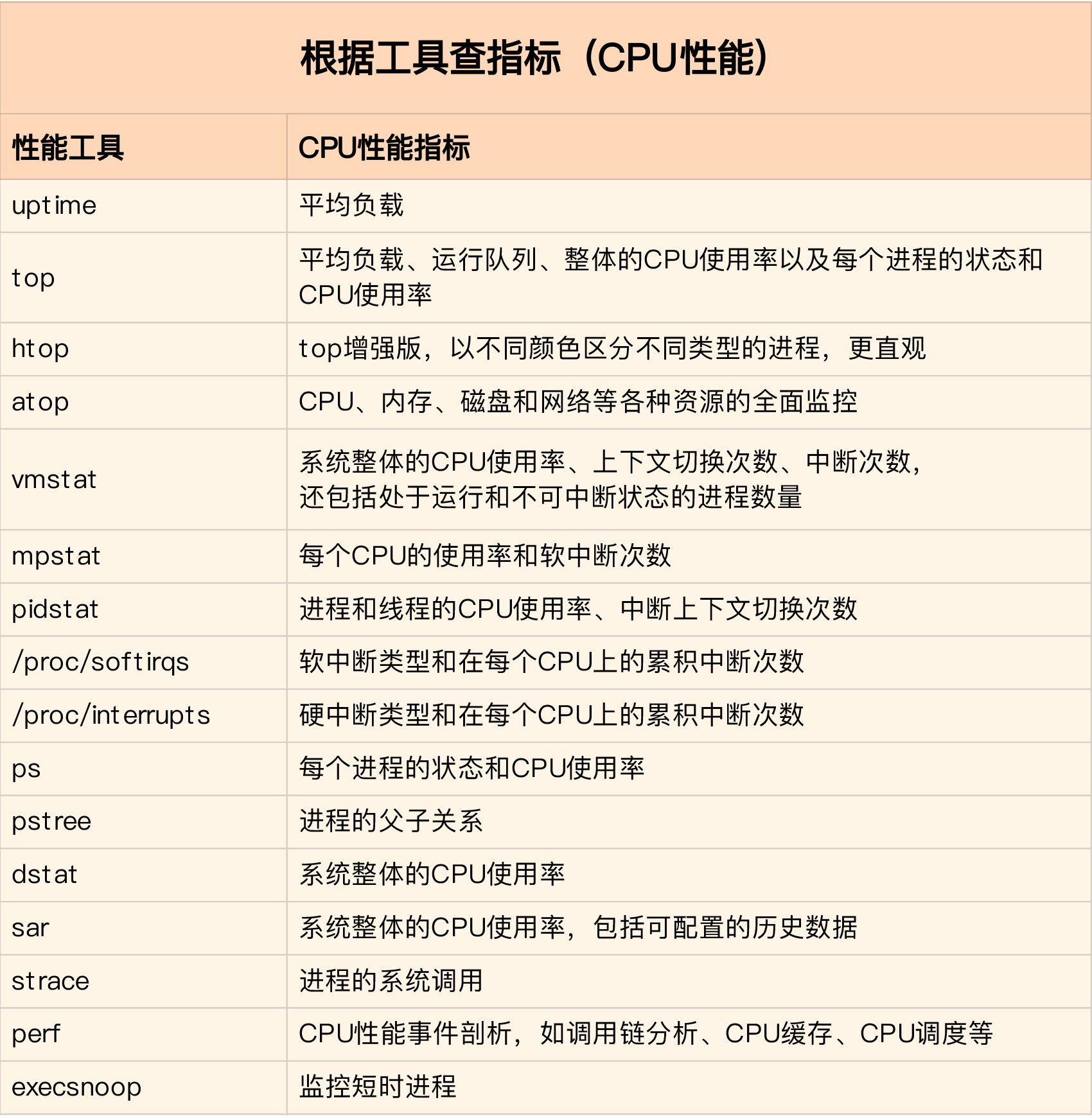
根据工具找指标
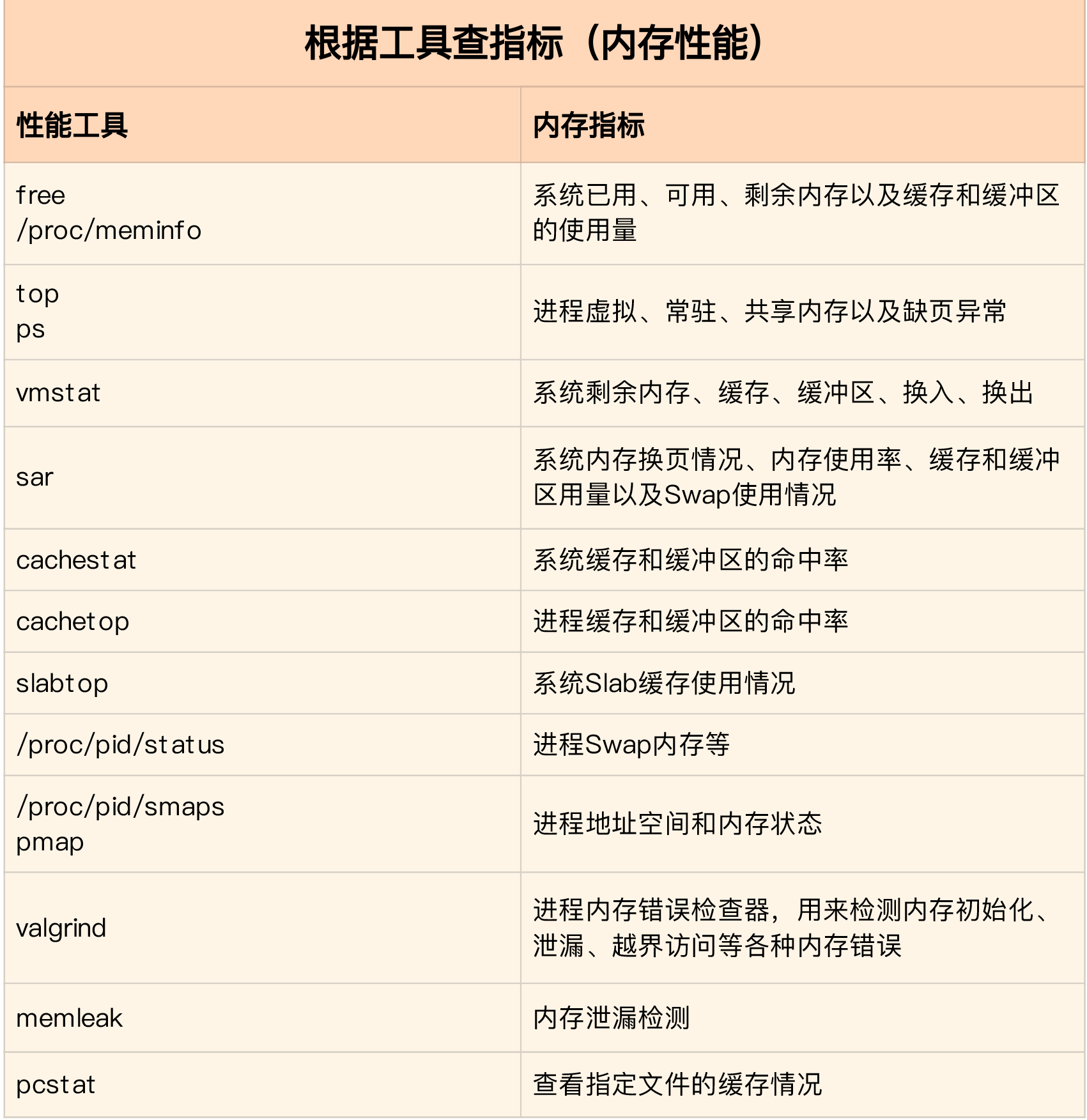
又快又准找出系统瓶颈?内存 性能分析的思路图谱
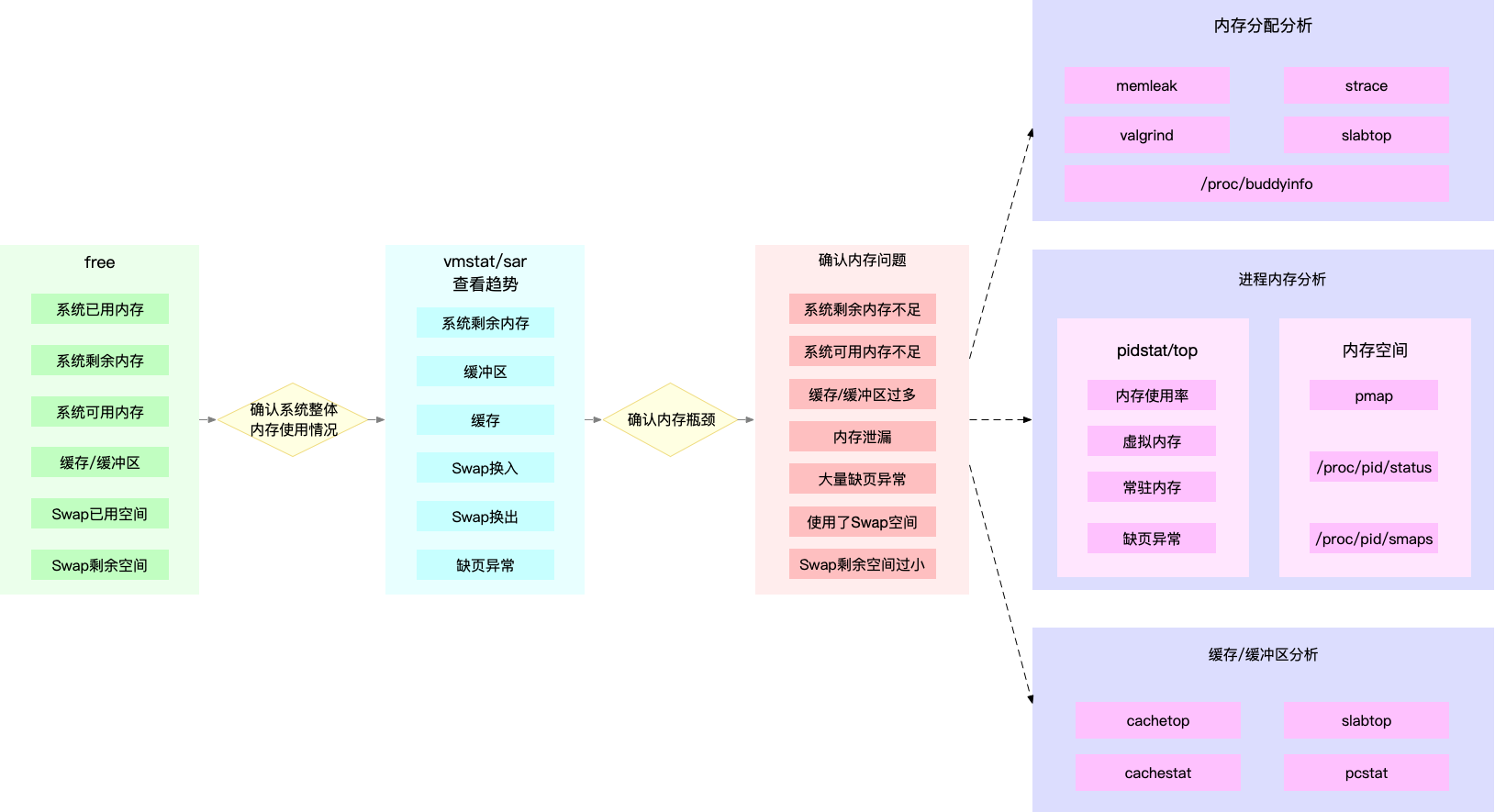
具体的分析思路主要有这几步。
- 先用 free 和 top,查看系统整体的内存使用情况。
- 再用 vmstat 和 pidstat,查看一段时间的趋势,从而判断出内存问题的类型。
- 最后进行详细分析,比如内存分配分析、缓存 / 缓冲区分析、具体进程的内存使用分析等。
内存调优优化思路
- 最好禁止 Swap。如果必须开启 Swap,降低 swappiness 的值,减少内存回收时 Swap 的使用倾向。
- 减少内存的动态分配。比如,可以使用内存池、大页(HugePage)等。
- 尽量使用缓存和缓冲区来访问数据。比如,可以使用堆栈明确声明内存空间,来存储需要缓存的数据;或者用 Redis 这类的外部缓存组件,优化数据的访问。
- 使用 cgroups 等方式限制进程的内存使用情况。这样,可以确保系统内存不会被异常进程耗尽。
- 通过 /proc/pid/oom_adj ,调整核心应用的 oom_score。这样,可以保证即使内存紧张,核心应用也不会被 OOM 杀死。
I/O 相关
df
用 df 命令,查看文件系统的磁盘空间使用情况。比如:
$ df /dev/sda1
Filesystem 1K-blocks Used Available Use% Mounted on
/dev/sda1 30308240 3167020 27124836 11% /
df 命令加上 -i 参数,查看索引节点的使用情况,如下所示:
$ df -i /dev/sda1
Filesystem Inodes IUsed IFree IUse% Mounted on
/dev/sda1 3870720 157460 3713260 5% /
/proc/slabinfo
运行下面的命令,可以得到,所有目录项和各种文件系统索引节点的缓存情况:
$ cat /proc/slabinfo | grep -E '^#|dentry|inode'
# name <active_objs> <num_objs> <objsize> <objperslab> <pagesperslab> : tunables <limit> <batchcount> <sharedfactor> : slabdata <active_slabs> <num_slabs> <sharedavail>
xfs_inode 0 0 960 17 4 : tunables 0 0 0 : slabdata 0 0 0
...
ext4_inode_cache 32104 34590 1088 15 4 : tunables 0 0 0 : slabdata 2306 2306 0hugetlbfs_inode_cache 13 13 624 13 2 : tunables 0 0 0 : slabdata 1 1 0
sock_inode_cache 1190 1242 704 23 4 : tunables 0 0 0 : slabdata 54 54 0
shmem_inode_cache 1622 2139 712 23 4 : tunables 0 0 0 : slabdata 93 93 0
proc_inode_cache 3560 4080 680 12 2 : tunables 0 0 0 : slabdata 340 340 0
inode_cache 25172 25818 608 13 2 : tunables 0 0 0 : slabdata 1986 1986 0
dentry 76050 121296 192 21 1 : tunables 0 0 0 : slabdata 5776 5776 0
slabtop 来找到占用内存最多的缓存类型。
# 按下c按照缓存大小排序,按下a按照活跃对象数排序
$ slabtop
Active / Total Objects (% used) : 277970 / 358914 (77.4%)
Active / Total Slabs (% used) : 12414 / 12414 (100.0%)
Active / Total Caches (% used) : 83 / 135 (61.5%)
Active / Total Size (% used) : 57816.88K / 73307.70K (78.9%)
Minimum / Average / Maximum Object : 0.01K / 0.20K / 22.88K
OBJS ACTIVE USE OBJ SIZE SLABS OBJ/SLAB CACHE SIZE NAME
69804 23094 0% 0.19K 3324 21 13296K dentry
16380 15854 0% 0.59K 1260 13 10080K inode_cache
58260 55397 0% 0.13K 1942 30 7768K kernfs_node_cache
485 413 0% 5.69K 97 5 3104K task_struct
1472 1397 0% 2.00K 92 16 2944K kmalloc-2048
磁盘性能指标
说到磁盘性能的衡量标准,必须要提到五个常见指标,也就是我们经常用到的,使用率、饱和度、IOPS、吞吐量以及响应时间等。这五个指标,是衡量磁盘性能的基本指标。
- 使用率,是指磁盘处理 I/O 的时间百分比。过高的使用率(比如超过 80%),通常意味着磁盘 I/O 存在性能瓶颈。
- 饱和度,是指磁盘处理 I/O 的繁忙程度。过高的饱和度,意味着磁盘存在严重的性能瓶颈。当饱和度为 100% 时,磁盘无法接受新的 I/O 请求。
- IOPS(Input/Output Per Second),是指每秒的 I/O 请求数。
- 吞吐量,是指每秒的 I/O 请求大小。
- 响应时间,是指 I/O 请求从发出到收到响应的间隔时间。
这里要注意的是,使用率只考虑有没有 I/O,而不考虑 I/O 的大小。换句话说,当使用率是 100% 的时候,磁盘依然有可能接受新的 I/O 请求。
iostat
iostat 是最常用的磁盘 I/O 性能观测工具,它提供了每个磁盘的使用率、IOPS、吞吐量等各种常见的性能指标,当然,这些指标实际上来自 /proc/diskstats。
# -d表示显示I/O性能指标,-x表示显示扩展统计(即所有I/O指标)
$ iostat -d -x 1
Device r/s w/s rkB/s wkB/s rrqm/s wrqm/s %rrqm %wrqm r_await w_await aqu-sz rareq-sz wareq-sz svctm %util
loop0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
loop1 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
sda 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
sdb 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
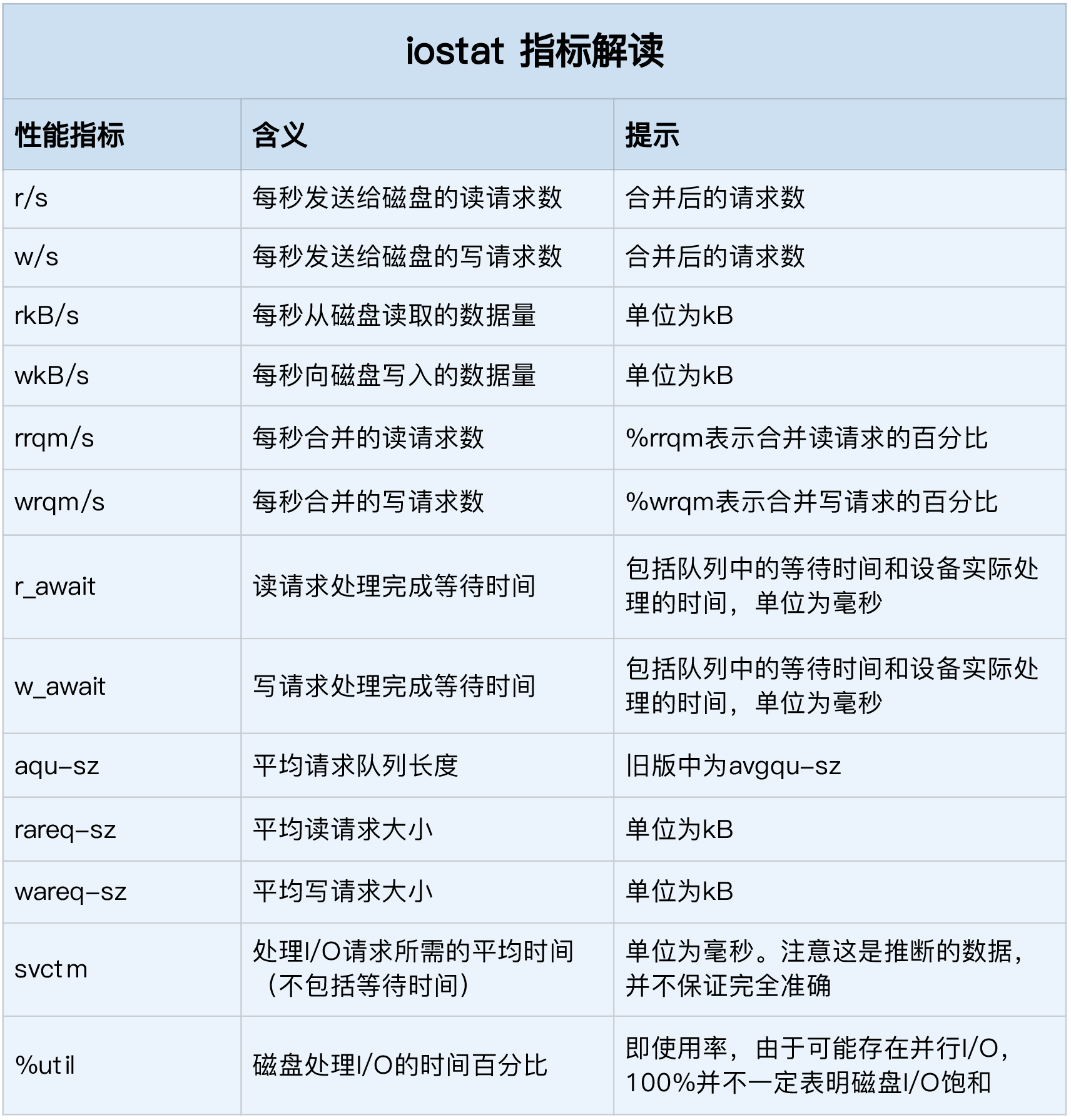
这些指标中,你要注意:
- %util ,就是我们前面提到的磁盘 I/O 使用率;
- r/s+ w/s ,就是 IOPS;
- rkB/s+wkB/s ,就是吞吐量;
- r_await+w_await ,就是响应时间。
pidstat 观察进程的 I/O 情况
给它加上 -d 参数,你就可以看到进程的 I/O 情况,如下所示:
$ pidstat -d 1
13:39:51 UID PID kB_rd/s kB_wr/s kB_ccwr/s iodelay Command
13:39:52 102 916 0.00 4.00 0.00 0 rsyslogd
从 pidstat 的输出你能看到,它可以实时查看每个进程的 I/O 情况,包括下面这些内容。
- 用户 ID(UID)和进程 ID(PID) 。
- 每秒读取的数据大小(kB_rd/s) ,单位是 KB。
- 每秒发出的写请求数据大小(kB_wr/s) ,单位是 KB。
- 每秒取消的写请求数据大小(kB_ccwr/s) ,单位是 KB。
- 块 I/O 延迟(iodelay),包括等待同步块 I/O 和换入块 I/O 结束的时间,单位是时钟周期。
iotop
它是一个类似于 top 的工具,你可以按照 I/O 大小对进程排序,然后找到 I/O 较大的那些进程。
$ iotop
Total DISK READ : 0.00 B/s | Total DISK WRITE : 7.85 K/s
Actual DISK READ: 0.00 B/s | Actual DISK WRITE: 0.00 B/s
TID PRIO USER DISK READ DISK WRITE SWAPIN IO> COMMAND
15055 be/3 root 0.00 B/s 7.85 K/s 0.00 % 0.00 % systemd-journald
从这个输出,你可以看到,前两行分别表示,进程的磁盘读写大小总数和磁盘真实的读写大小总数。因为缓存、缓冲区、I/O 合并等因素的影响,它们可能并不相等。
剩下的部分,则是从各个角度来分别表示进程的 I/O 情况,包括线程 ID、I/O 优先级、每秒读磁盘的大小、每秒写磁盘的大小、换入和等待 I/O 的时钟百分比等。
lsof
它专门用来查看进程打开文件列表,不过,这里的“文件”不只有普通文件,还包括了目录、块设备、动态库、网络套接字等。
# -p 进程ID
$ lsof -p 18940
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
python 18940 root cwd DIR 0,50 4096 1549389 /
python 18940 root rtd DIR 0,50 4096 1549389 /
…
python 18940 root 2u CHR 136,0 0t0 3 /dev/pts/0
python 18940 root 3w REG 8,1 117944320 303 /tmp/logtest.txt
- FD 表示文件描述符号
- TYPE 表示文件类型
- NAME 表示文件路径
filetop 跟踪内核中文件的读写情况,并输出线程 ID(TID)、读写大小、读写类型以及文件名称。
它是 bcc 软件包的一部分。
# 切换到工具目录
$ cd /usr/share/bcc/tools
# -C 选项表示输出新内容时不清空屏幕
$ ./filetop -C
TID COMM READS WRITES R_Kb W_Kb T FILE
514 python 0 1 0 2832 R 669.txt
514 python 0 1 0 2490 R 667.txt
514 python 0 1 0 2685 R 671.txt
514 python 0 1 0 2392 R 670.txt
514 python 0 1 0 2050 R 672.txt
...
TID COMM READS WRITES R_Kb W_Kb T FILE
514 python 2 0 5957 0 R 651.txt
514 python 2 0 5371 0 R 112.txt
514 python 2 0 4785 0 R 861.txt
514 python 2 0 4736 0 R 213.txt
514 python 2 0 4443 0 R 45.txt
opensnoop 它同属于 bcc 软件包,可以动态跟踪内核中的 open 系统调用。
$ opensnoop
12280 python 6 0 /tmp/9046db9e-fe25-11e8-b13f-0242ac110002/650.txt
12280 python 6 0 /tmp/9046db9e-fe25-11e8-b13f-0242ac110002/651.txt
12280 python 6 0 /tmp/9046db9e-fe25-11e8-b13f-0242ac110002/652.txt
I/O 的性能指标
文件系统 I/O 性能指标
首先,最容易想到的是存储空间的使用情况,包括容量、使用量以及剩余空间等。
其次,是缓存使用情况,包括页缓存、目录项缓存、索引节点缓存以及各个具体文件系统(如 ext4、XFS 等)的缓存。
磁盘 I/O 性能指标
- 使用率,是指磁盘忙处理 I/O 请求的百分比。过高的使用率(比如超过 60%)通常意味着磁盘 I/O 存在性能瓶颈。
- IOPS(Input/Output Per Second),是指每秒的 I/O 请求数。
- 吞吐量,是指每秒的 I/O 请求大小。
- 响应时间,是指从发出 I/O 请求到收到响应的间隔时间。
I/O 性能分析的“指标筛选”清单
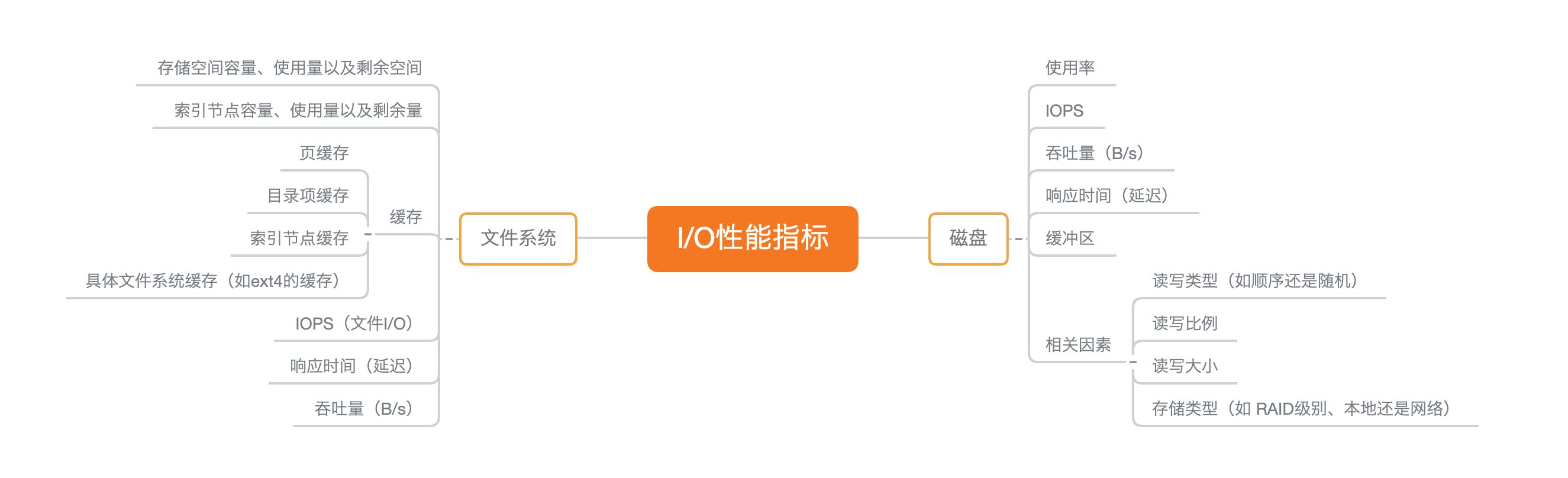
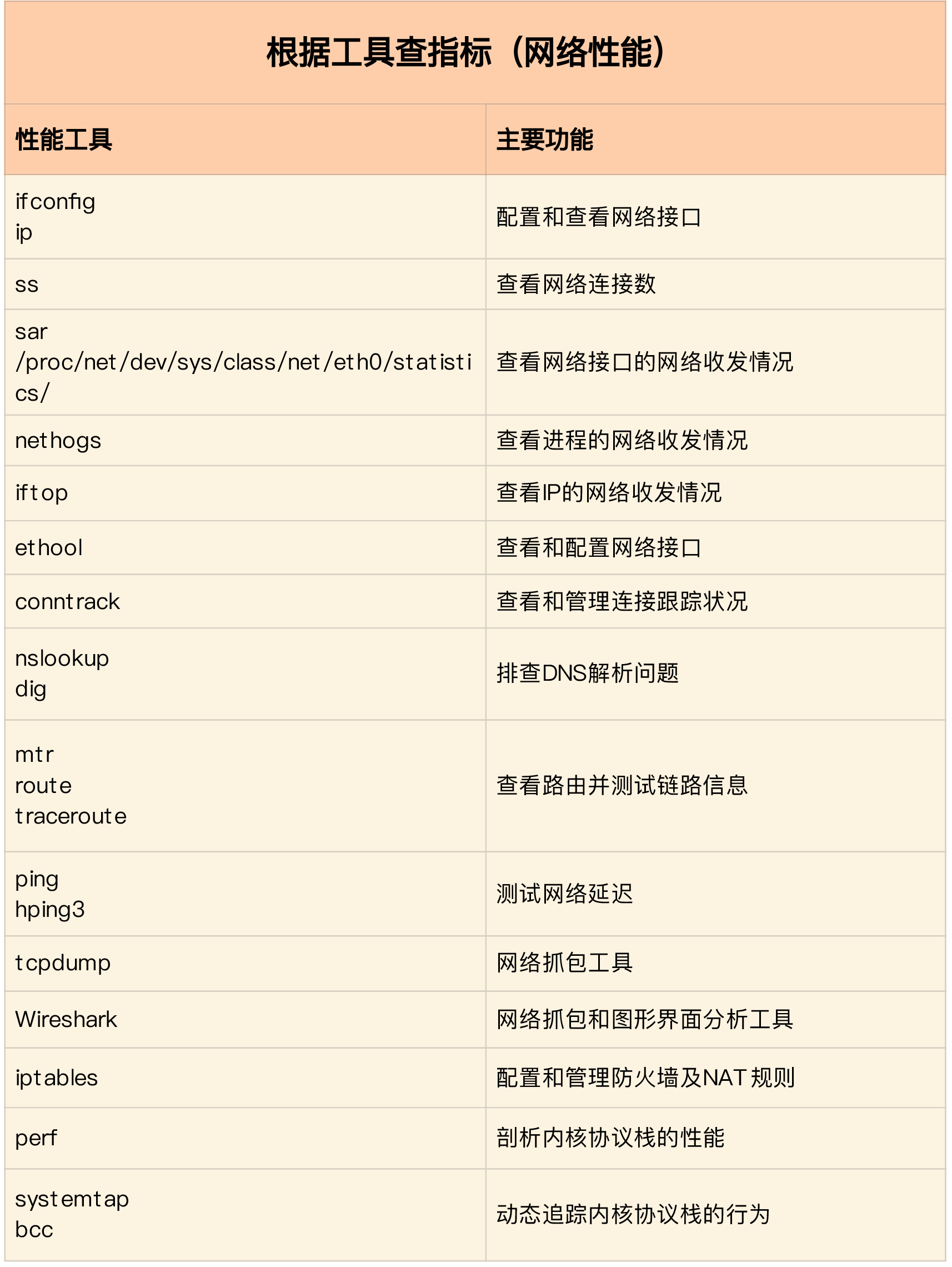
I/O 性能工具
根据指标找工具
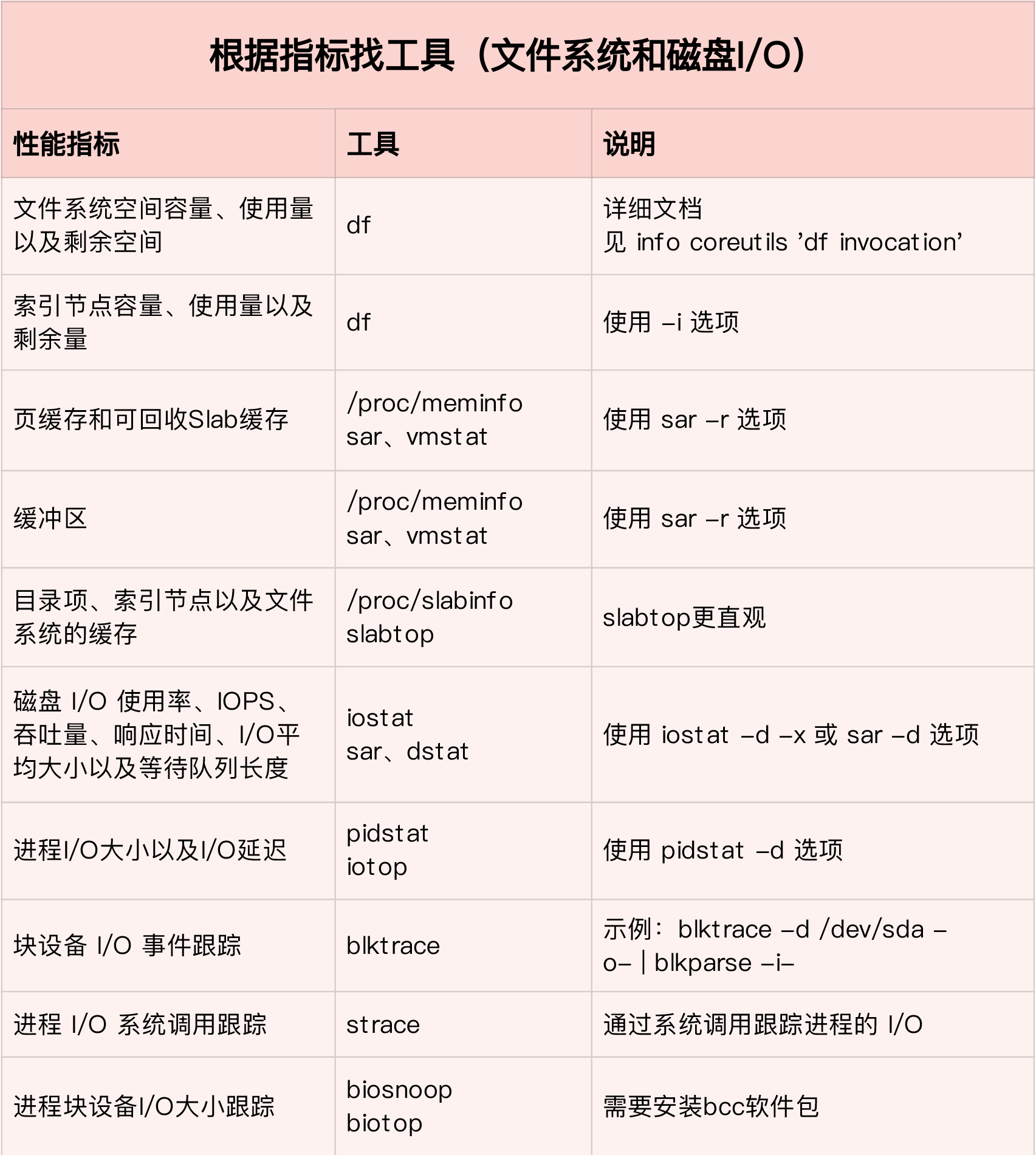
根据工具查指标
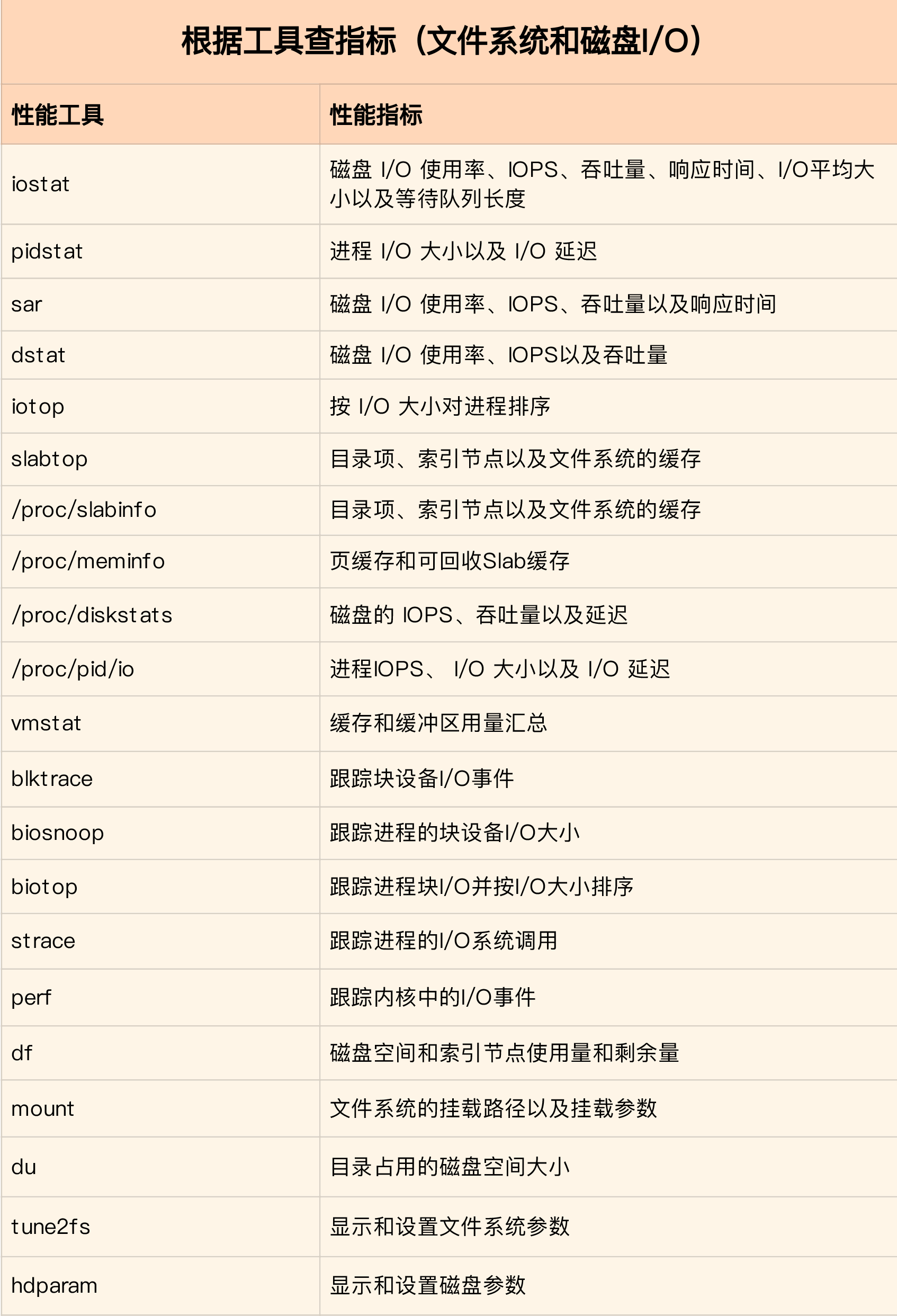
迅速分析 I/O 的性能瓶颈
最开始的分析思路基本上类似,都是:
- 先用 iostat 发现磁盘 I/O 性能瓶颈;
- 再借助 pidstat ,定位出导致瓶颈的进程;
- 随后分析进程的 I/O 行为;
- 最后,结合应用程序的原理,分析这些 I/O 的来源。
fio(Flexible I/O Tester)最常用的文件系统和磁盘 I/O 性能基准测试工具。
它提供了大量的可定制化选项,可以用来测试,裸盘或者文件系统在各种场景下的 I/O 性能,包括了不同块大小、不同 I/O 引擎以及是否使用缓存等场景。
fio 的选项非常多, 这些常见场景包括随机读、随机写、顺序读以及顺序写等,你可以执行下面这些命令来测试:
# 随机读
fio -name=randread -direct=1 -iodepth=64 -rw=randread -ioengine=libaio -bs=4k -size=1G -numjobs=1 -runtime=1000 -group_reporting -filename=/dev/sdb
# 随机写
fio -name=randwrite -direct=1 -iodepth=64 -rw=randwrite -ioengine=libaio -bs=4k -size=1G -numjobs=1 -runtime=1000 -group_reporting -filename=/dev/sdb
# 顺序读
fio -name=read -direct=1 -iodepth=64 -rw=read -ioengine=libaio -bs=4k -size=1G -numjobs=1 -runtime=1000 -group_reporting -filename=/dev/sdb
# 顺序写
fio -name=write -direct=1 -iodepth=64 -rw=write -ioengine=libaio -bs=4k -size=1G -numjobs=1 -runtime=1000 -group_reporting -filename=/dev/sdb
- direct,表示是否跳过系统缓存。上面示例中,我设置的 1 ,就表示跳过系统缓存。
- iodepth,表示使用异步 I/O(asynchronous I/O,简称 AIO)时,同时发出的 I/O 请求上限。在上面的示例中,我设置的是 64。
- rw,表示 I/O 模式。我的示例中, read/write 分别表示顺序读 / 写,而 randread/randwrite 则分别表示随机读 / 写。
- ioengine,表示 I/O 引擎,它支持同步(sync)、异步(libaio)、内存映射(mmap)、网络(net)等各种 I/O 引擎。上面示例中,我设置的 libaio 表示使用异步 I/O。
- bs,表示 I/O 的大小。示例中,我设置成了 4K(这也是默认值)。
- filename,表示文件路径,当然,它可以是磁盘路径(测试磁盘性能),也可以是文件路径(测试文件系统性能)。示例中,我把它设置成了磁盘 /dev/sdb。不过注意,用磁盘路径测试写,会破坏这个磁盘中的文件系统,所以在使用前,你一定要事先做好数据备份。
下面是使用 fio 测试顺序读的一个报告示例:
read: (g=0): rw=read, bs=(R) 4096B-4096B, (W) 4096B-4096B, (T) 4096B-4096B, ioengine=libaio, iodepth=64
fio-3.1
Starting 1 process
Jobs: 1 (f=1): [R(1)][100.0%][r=16.7MiB/s,w=0KiB/s][r=4280,w=0 IOPS][eta 00m:00s]
read: (groupid=0, jobs=1): err= 0: pid=17966: Sun Dec 30 08:31:48 2018
read: IOPS=4257, BW=16.6MiB/s (17.4MB/s)(1024MiB/61568msec)
slat (usec): min=2, max=2566, avg= 4.29, stdev=21.76
clat (usec): min=228, max=407360, avg=15024.30, stdev=20524.39
lat (usec): min=243, max=407363, avg=15029.12, stdev=20524.26
clat percentiles (usec):
| 1.00th=[ 498], 5.00th=[ 1020], 10.00th=[ 1319], 20.00th=[ 1713],
| 30.00th=[ 1991], 40.00th=[ 2212], 50.00th=[ 2540], 60.00th=[ 2933],
| 70.00th=[ 5407], 80.00th=[ 44303], 90.00th=[ 45351], 95.00th=[ 45876],
| 99.00th=[ 46924], 99.50th=[ 46924], 99.90th=[ 48497], 99.95th=[ 49021],
| 99.99th=[404751]
bw ( KiB/s): min= 8208, max=18832, per=99.85%, avg=17005.35, stdev=998.94, samples=123
iops : min= 2052, max= 4708, avg=4251.30, stdev=249.74, samples=123
lat (usec) : 250=0.01%, 500=1.03%, 750=1.69%, 1000=2.07%
lat (msec) : 2=25.64%, 4=37.58%, 10=2.08%, 20=0.02%, 50=29.86%
lat (msec) : 100=0.01%, 500=0.02%
cpu : usr=1.02%, sys=2.97%, ctx=33312, majf=0, minf=75
IO depths : 1=0.1%, 2=0.1%, 4=0.1%, 8=0.1%, 16=0.1%, 32=0.1%, >=64=100.0%
submit : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
complete : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.1%, >=64=0.0%
issued rwt: total=262144,0,0, short=0,0,0, dropped=0,0,0
latency : target=0, window=0, percentile=100.00%, depth=64
Run status group 0 (all jobs):
READ: bw=16.6MiB/s (17.4MB/s), 16.6MiB/s-16.6MiB/s (17.4MB/s-17.4MB/s), io=1024MiB (1074MB), run=61568-61568msec
Disk stats (read/write):
sdb: ios=261897/0, merge=0/0, ticks=3912108/0, in_queue=3474336, util=90.09%
这个报告中,需要我们重点关注的是, slat、clat、lat ,以及 bw 和 iops 这几行。
事实上,slat、clat、lat 都是指 I/O 延迟(latency)。不同之处在于:
- slat ,是指从 I/O 提交到实际执行 I/O 的时长(Submission latency);
- clat ,是指从 I/O 提交到 I/O 完成的时长(Completion latency);
- 而 lat ,指的是从 fio 创建 I/O 到 I/O 完成的总时长。
网络相关
OSI 七层网络模型
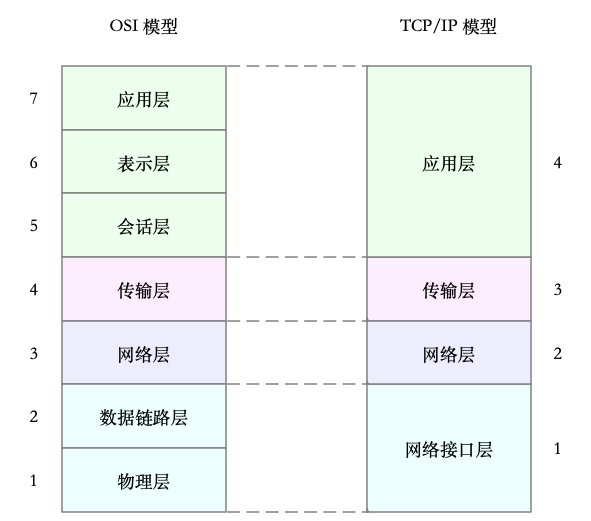
为了解决网络互联中异构设备的兼容性问题,并解耦复杂的网络包处理流程,OSI 模型把网络互联的框架分为应用层、表示层、会话层、传输层、网络层、数据链路层以及物理层等七层,每个层负责不同的功能。其中:
- 应用层,负责为应用程序提供统一的接口。
- 表示层,负责把数据转换成兼容接收系统的格式。
- 会话层,负责维护计算机之间的通信连接。
- 传输层,负责为数据加上传输表头,形成数据包。
- 网络层,负责数据的路由和转发。
- 数据链路层,负责 MAC 寻址、错误侦测和改错。
- 物理层,负责在物理网络中传输数据帧。
四层模型,即 TCP/IP 网络模型。
TCP/IP 模型,把网络互联的框架分为应用层、传输层、网络层、网络接口层等四层,其中:
- 应用层,负责向用户提供一组应用程序,比如 HTTP、FTP、DNS 等。
- 传输层,负责端到端的通信,比如 TCP、UDP 等。
- 网络层,负责网络包的封装、寻址和路由,比如 IP、ICMP 等。
- 网络接口层,负责网络包在物理网络中的传输,比如 MAC 寻址、错误侦测以及通过网卡传输网络帧等。
TCP/IP 与 OSI 模型的关系
七层和四层负载均衡
说到七层和四层负载均衡,对应的分别是 OSI 模型中的应用层和传输层(而它们对应到 TCP/IP 模型中,实际上是四层和三层)。
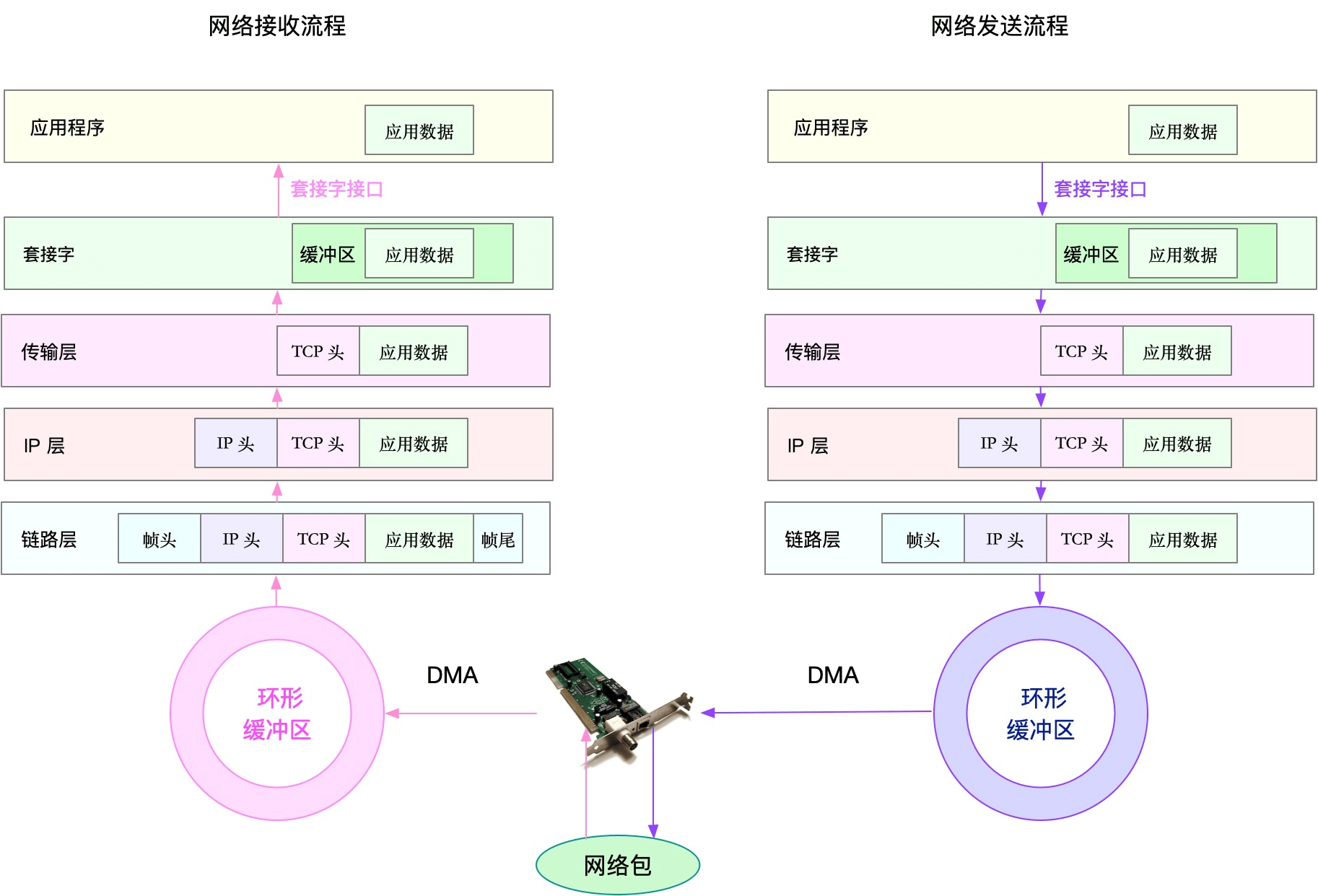
网络包的收发流程
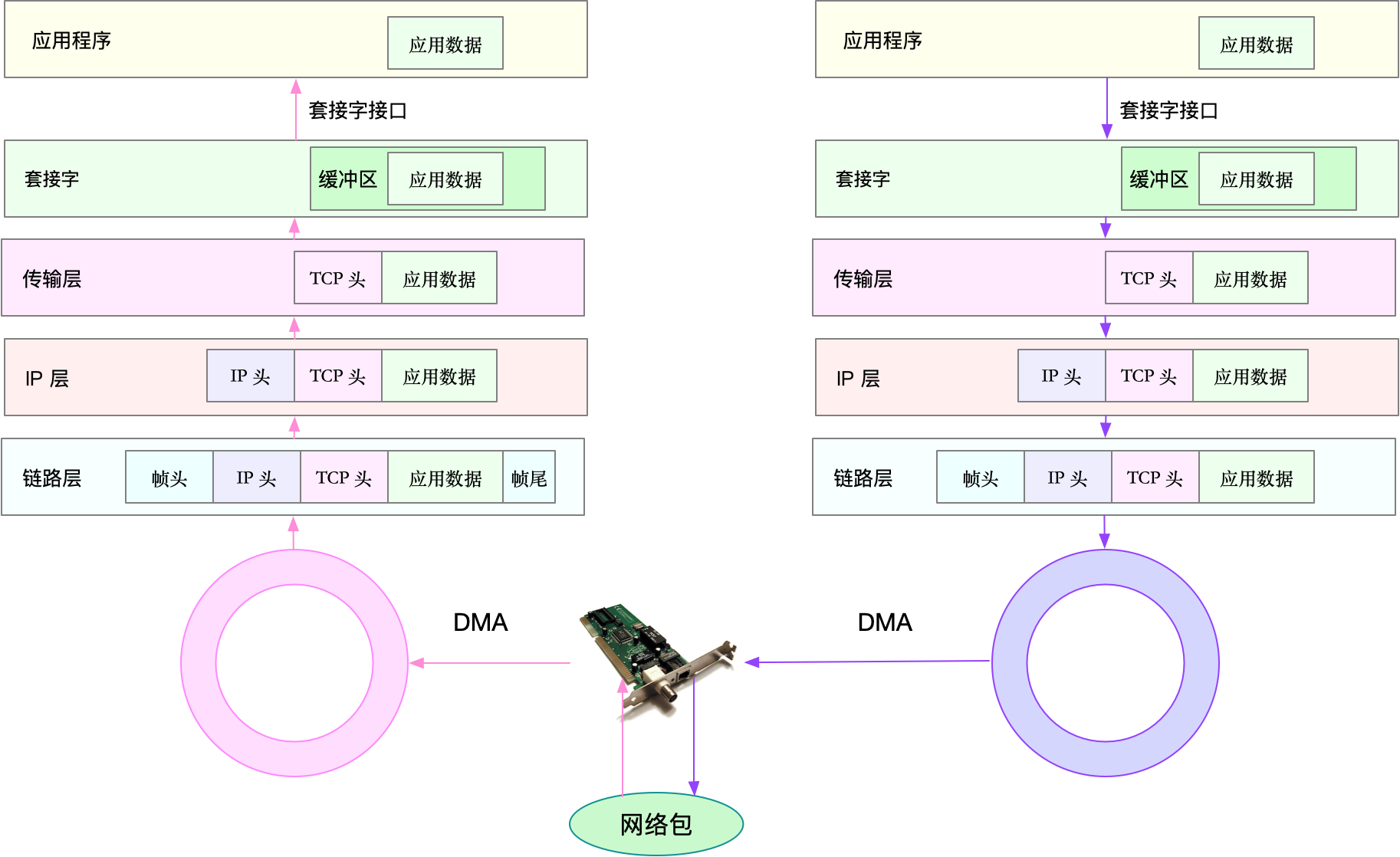
网络性能指标
实际上,我们通常用带宽、吞吐量、延时、PPS(Packet Per Second)等指标衡量网络的性能。
- 带宽,表示链路的最大传输速率,单位通常为 b/s (比特 / 秒)。
- 吞吐量,表示单位时间内成功传输的数据量,单位通常为 b/s(比特 / 秒)或者 B/s(字节 / 秒)。吞吐量受带宽限制,而吞吐量 / 带宽,也就是该网络的使用率。
- 延时,表示从网络请求发出后,一直到收到远端响应,所需要的时间延迟。在不同场景中,这一指标可能会有不同含义。比如,它可以表示,建立连接需要的时间(比如 TCP 握手延时),或一个数据包往返所需的时间(比如 RTT)。
- PPS,是 Packet Per Second(包 / 秒)的缩写,表示以网络包为单位的传输速率。PPS 通常用来评估网络的转发能力,比如硬件交换机,通常可以达到线性转发(即 PPS 可以达到或者接近理论最大值)。而基于 Linux 服务器的转发,则容易受网络包大小的影响。
除了这些指标,网络的可用性(网络能否正常通信)、并发连接数(TCP 连接数量)、丢包率(丢包百分比)、重传率(重新传输的网络包比例)等也是常用的性能指标。
ifconfig 和 ip 查看网络的配置
ifconfig 和 ip 分别属于软件包 net-tools 和 iproute2,iproute2 是 net-tools 的下一代。通常情况下它们会在发行版中默认安装。但如果你找不到 ifconfig 或者 ip 命令,可以安装这两个软件包。
以网络接口 eth0 为例,你可以运行下面的两个命令,查看它的配置和状态:
$ ifconfig eth0
eth0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 10.240.0.30 netmask 255.240.0.0 broadcast 10.255.255.255
inet6 fe80::20d:3aff:fe07:cf2a prefixlen 64 scopeid 0x20<link>
ether 78:0d:3a:07:cf:3a txqueuelen 1000 (Ethernet)
RX packets 40809142 bytes 9542369803 (9.5 GB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 32637401 bytes 4815573306 (4.8 GB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
$ ip -s addr show dev eth0
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP group default qlen 1000
link/ether 78:0d:3a:07:cf:3a brd ff:ff:ff:ff:ff:ff
inet 10.240.0.30/12 brd 10.255.255.255 scope global eth0
valid_lft forever preferred_lft forever
inet6 fe80::20d:3aff:fe07:cf2a/64 scope link
valid_lft forever preferred_lft forever
RX: bytes packets errors dropped overrun mcast
9542432350 40809397 0 0 0 193
TX: bytes packets errors dropped carrier collsns
4815625265 32637658 0 0 0 0
你可以看到,ifconfig 和 ip 命令输出的指标基本相同,只是显示格式略微不同。比如,它们都包括了网络接口的状态标志、MTU 大小、IP、子网、MAC 地址以及网络包收发的统计信息。
这些具体指标的含义,在文档中都有详细的说明,不过,这里有几个跟网络性能密切相关的指标,需要你特别关注一下。
第一,网络接口的状态标志。ifconfig 输出中的 RUNNING ,或 ip 输出中的 LOWER_UP ,都表示物理网络是连通的,即网卡已经连接到了交换机或者路由器中。如果你看不到它们,通常表示网线被拔掉了。
第二,MTU 的大小。MTU 默认大小是 1500,根据网络架构的不同(比如是否使用了 VXLAN 等叠加网络),你可能需要调大或者调小 MTU 的数值。
第三,网络接口的 IP 地址、子网以及 MAC 地址。这些都是保障网络功能正常工作所必需的,你需要确保配置正确。
第四,网络收发的字节数、包数、错误数以及丢包情况,特别是 TX 和 RX 部分的 errors、dropped、overruns、carrier 以及 collisions 等指标不为 0 时,通常表示出现了网络 I/O 问题。其中:
- errors 表示发生错误的数据包数,比如校验错误、帧同步错误等;
- dropped 表示丢弃的数据包数,即数据包已经收到了 Ring Buffer,但因为内存不足等原因丢包;
- overruns 表示超限数据包数,即网络 I/O 速度过快,导致 Ring Buffer 中的数据包来不及处理(队列满)而导致的丢包;
- carrier 表示发生 carrirer 错误的数据包数,比如双工模式不匹配、物理电缆出现问题等;
- collisions 表示碰撞数据包数。
netstat 或者 ss ,来查看套接字、网络栈、网络接口以及路由表的信息。
更推荐,使用 ss 来查询网络的连接信息,因为它比 netstat 提供了更好的性能(速度更快)。
# head -n 3 表示只显示前面3行
# -l 表示只显示监听套接字
# -n 表示显示数字地址和端口(而不是名字)
# -p 表示显示进程信息
$ netstat -nlp | head -n 3
Active Internet connections (only servers)
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name
tcp 0 0 127.0.0.53:53 0.0.0.0:* LISTEN 840/systemd-resolve
# -l 表示只显示监听套接字
# -t 表示只显示 TCP 套接字
# -n 表示显示数字地址和端口(而不是名字)
# -p 表示显示进程信息
$ ss -ltnp | head -n 3
State Recv-Q Send-Q Local Address:Port Peer Address:Port
LISTEN 0 128 127.0.0.53%lo:53 0.0.0.0:* users:(("systemd-resolve",pid=840,fd=13))
LISTEN 0 128 0.0.0.0:22 0.0.0.0:* users:(("sshd",pid=1459,fd=3))
netstat 和 ss 的输出也是类似的,都展示了套接字的状态、接收队列、发送队列、本地地址、远端地址、进程 PID 和进程名称等。
其中,接收队列(Recv-Q)和发送队列(Send-Q)需要你特别关注,它们通常应该是 0。当你发现它们不是 0 时,说明有网络包的堆积发生。当然还要注意,在不同套接字状态下,它们的含义不同。
当套接字处于连接状态(Established)时:
- Recv-Q 表示套接字缓冲还没有被应用程序取走的字节数(即接收队列长度)。
- 而 Send-Q 表示还没有被远端主机确认的字节数(即发送队列长度)。
当套接字处于监听状态(Listening)时:
- Recv-Q 表示全连接队列的长度。
- 而 Send-Q 表示全连接队列的最大长度。
所谓全连接,是指服务器收到了客户端的 ACK,完成了 TCP 三次握手,然后就会把这个连接挪到全连接队列中。这些全连接中的套接字,还需要被 accept() 系统调用取走,服务器才可以开始真正处理客户端的请求。
与全连接队列相对应的,还有一个半连接队列。所谓半连接是指还没有完成 TCP 三次握手的连接,连接只进行了一半。服务器收到了客户端的 SYN 包后,就会把这个连接放到半连接队列中,然后再向客户端发送 SYN+ACK 包。
协议栈统计信息
使用 netstat 或 ss ,也可以查看协议栈的信息:
$ netstat -s
...
Tcp:
3244906 active connection openings
23143 passive connection openings
115732 failed connection attempts
2964 connection resets received
1 connections established
13025010 segments received
17606946 segments sent out
44438 segments retransmitted
42 bad segments received
5315 resets sent
InCsumErrors: 42
...
$ ss -s
Total: 186 (kernel 1446)
TCP: 4 (estab 1, closed 0, orphaned 0, synrecv 0, timewait 0/0), ports 0
Transport Total IP IPv6
* 1446 - -
RAW 2 1 1
UDP 2 2 0
TCP 4 3 1
...
sar 查看网络吞吐和 PPS
给 sar 增加 -n 参数就可以查看网络的统计信息,比如网络接口(DEV)、网络接口错误(EDEV)、TCP、UDP、ICMP 等等。执行下面的命令,你就可以得到网络接口统计信息:
# 数字1表示每隔1秒输出一组数据
$ sar -n DEV 1
Linux 4.15.0-1035-azure (ubuntu) 01/06/19 _x86_64_ (2 CPU)
13:21:40 IFACE rxpck/s txpck/s rxkB/s txkB/s rxcmp/s txcmp/s rxmcst/s %ifutil
13:21:41 eth0 18.00 20.00 5.79 4.25 0.00 0.00 0.00 0.00
13:21:41 docker0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
13:21:41 lo 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
- rxpck/s 和 txpck/s 分别是接收和发送的 PPS,单位为包 / 秒。
- rxkB/s 和 txkB/s 分别是接收和发送的吞吐量,单位是 KB/ 秒。
- rxkB/s 和 txkB/s 分别是接收和发送的吞吐量,单位是 KB/ 秒。
- %ifutil 是网络接口的使用率,即半双工模式下为 (rxkB/s+txkB/s)/Bandwidth,而全双工模式下为 max(rxkB/s, txkB/s)/Bandwidth。
其中,Bandwidth 可以用 ethtool 来查询,它的单位通常是 Gb/s 或者 Mb/s,不过注意这里小写字母 b ,表示比特而不是字节。我们通常提到的千兆网卡、万兆网卡等,单位也都是比特。如下你可以看到,我的 eth0 网卡就是一个千兆网卡:
$ ethtool eth0 | grep Speed
Speed: 1000Mb/s
ping 测试连通性和延时,基于ICMP协议
# -c3表示发送三次ICMP包后停止
$ ping -c3 114.114.114.114
PING 114.114.114.114 (114.114.114.114) 56(84) bytes of data.
64 bytes from 114.114.114.114: icmp_seq=1 ttl=54 time=244 ms
64 bytes from 114.114.114.114: icmp_seq=2 ttl=47 time=244 ms
64 bytes from 114.114.114.114: icmp_seq=3 ttl=67 time=244 ms
--- 114.114.114.114 ping statistics ---
3 packets transmitted, 3 received, 0% packet loss, time 2001ms
rtt min/avg/max/mdev = 244.023/244.070/244.105/0.034 ms
ping 的输出,可以分为两部分。
- 第一部分,是每个 ICMP 请求的信息,包括 ICMP 序列号(icmp_seq)、TTL(生存时间,或者跳数)以及往返延时。
- 第二部分,则是三次 ICMP 请求的汇总。
比如上面的示例显示,发送了 3 个网络包,并且接收到 3 个响应,没有丢包发生,这说明测试主机到 114.114.114.114 是连通的;平均往返延时(RTT)是 244ms,也就是从发送 ICMP 开始,到接收到 114.114.114.114 回复的确认,总共经历 244ms。
网络基准测试
各协议层的性能测试
转发性能 PPS
pktgen Linux 内核自带的高性能网络测试工具
在 Linux 系统中,你并不能直接找到 pktgen 命令。因为 pktgen 作为一个内核线程来运行,需要你加载 pktgen 内核模块后,再通过 /proc 文件系统来交互。下面就是 pktgen 启动的两个内核线程和 /proc 文件系统的交互文件:
$ modprobe pktgen
$ ps -ef | grep pktgen | grep -v grep
root 26384 2 0 06:17 ? 00:00:00 [kpktgend_0]
root 26385 2 0 06:17 ? 00:00:00 [kpktgend_1]
$ ls /proc/net/pktgen/
kpktgend_0 kpktgend_1 pgctrl
pktgen 在每个 CPU 上启动一个内核线程,并可以通过 /proc/net/pktgen 下面的同名文件,跟这些线程交互;而 pgctrl 则主要用来控制这次测试的开启和停止。
如果 modprobe 命令执行失败,说明你的内核没有配置 CONFIG_NET_PKTGEN 选项。这就需要你配置 pktgen 内核模块(即 CONFIG_NET_PKTGEN=m)后,重新编译内核,才可以使用。
在使用 pktgen 测试网络性能时,需要先给每个内核线程 kpktgend_X 以及测试网卡,配置 pktgen 选项,然后再通过 pgctrl 启动测试。
以发包测试为例,假设发包机器使用的网卡是 eth0,而目标机器的 IP 地址为 192.168.0.30,MAC 地址为 11:11:11:11:11:11。
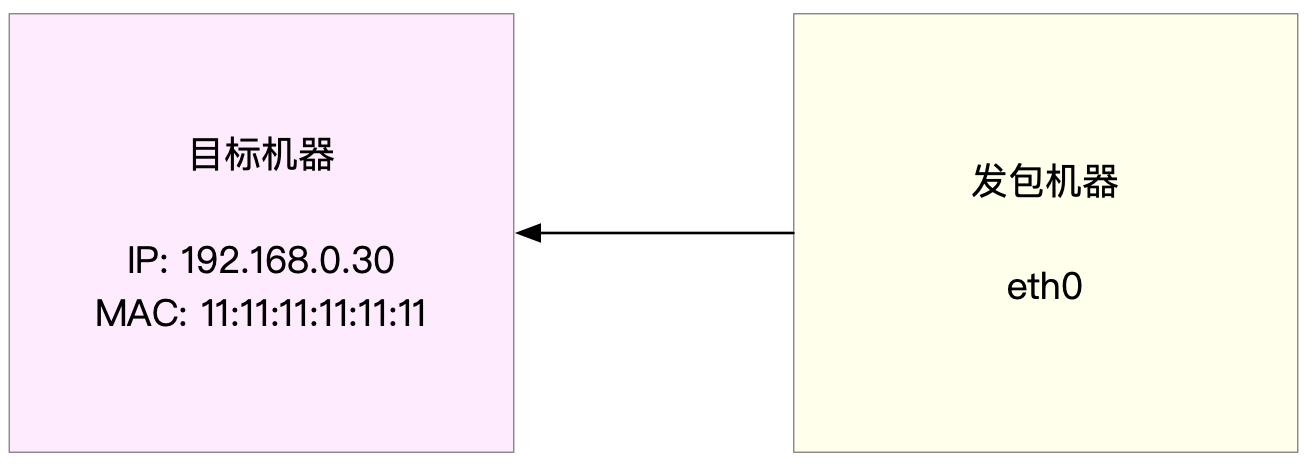
接下来,就是一个发包测试的示例。
# 定义一个工具函数,方便后面配置各种测试选项
function pgset() {
local result
echo $1 > $PGDEV
result=`cat $PGDEV | fgrep "Result: OK:"`
if [ "$result" = "" ]; then
cat $PGDEV | fgrep Result:
fi
}
# 为0号线程绑定eth0网卡
PGDEV=/proc/net/pktgen/kpktgend_0
pgset "rem_device_all" # 清空网卡绑定
pgset "add_device eth0" # 添加eth0网卡
# 配置eth0网卡的测试选项
PGDEV=/proc/net/pktgen/eth0
pgset "count 1000000" # 总发包数量
pgset "delay 5000" # 不同包之间的发送延迟(单位纳秒)
pgset "clone_skb 0" # SKB包复制
pgset "pkt_size 64" # 网络包大小
pgset "dst 192.168.0.30" # 目的IP
pgset "dst_mac 11:11:11:11:11:11" # 目的MAC
# 启动测试
PGDEV=/proc/net/pktgen/pgctrl
pgset "start"
稍等一会儿,测试完成后,结果可以从 /proc 文件系统中获取。通过下面代码段中的内容,我们可以查看刚才的测试报告:
$ cat /proc/net/pktgen/eth0
Params: count 1000000 min_pkt_size: 64 max_pkt_size: 64
frags: 0 delay: 0 clone_skb: 0 ifname: eth0
flows: 0 flowlen: 0
...
Current:
pkts-sofar: 1000000 errors: 0
started: 1534853256071us stopped: 1534861576098us idle: 70673us
...
Result: OK: 8320027(c8249354+d70673) usec, 1000000 (64byte,0frags)
120191pps 61Mb/sec (61537792bps) errors: 0
测试报告主要分为三个部分:
- 第一部分的 Params 是测试选项;
- 第二部分的 Current 是测试进度,其中, packts so far(pkts-sofar)表示已经发送了 100 万个包,也就表明测试已完成。
- 第三部分的 Result 是测试结果,包含测试所用时间、网络包数量和分片、PPS、吞吐量以及错误数。
根据上面的结果,我们发现,PPS 为 12 万,吞吐量为 61 Mb/s,没有发生错误。那么,12 万的 PPS 好不好呢?
作为对比,你可以计算一下千兆交换机的 PPS。交换机可以达到线速(满负载时,无差错转发),它的 PPS 就是 1000Mbit 除以以太网帧的大小,即 1000Mbps/((64+20)*8bit) = 1.5 Mpps(其中,20B 为以太网帧前导和帧间距的大小)。
你看,即使是千兆交换机的 PPS,也可以达到 150 万 PPS,比我们测试得到的 12 万大多了。所以,看到这个数值你并不用担心,现在的多核服务器和万兆网卡已经很普遍了,稍做优化就可以达到数百万的 PPS。
TCP/UDP 性能
iperf 和 netperf 都是最常用的网络性能测试工具,测试 TCP 和 UDP 的吞吐量。
目前,iperf 的最新版本为 iperf3,你可以运行下面的命令来安装:
# Ubuntu
apt-get install iperf3
# CentOS
yum install iperf3
然后,在目标机器上启动 iperf 服务端:
# -s表示启动服务端,-i表示汇报间隔,-p表示监听端口
$ iperf3 -s -i 1 -p 10000
接着,在另一台机器上运行 iperf 客户端,运行测试:
# -c表示启动客户端,192.168.0.30为目标服务器的IP
# -b表示目标带宽(单位是bits/s)
# -t表示测试时间
# -P表示并发数,-p表示目标服务器监听端口
$ iperf3 -c 192.168.0.30 -b 1G -t 15 -P 2 -p 10000
稍等一会儿(15 秒)测试结束后,回到目标服务器,查看 iperf 的报告:
[ ID] Interval Transfer Bandwidth
...
[SUM] 0.00-15.04 sec 0.00 Bytes 0.00 bits/sec sender
[SUM] 0.00-15.04 sec 1.51 GBytes 860 Mbits/sec receiver
最后的 SUM 行就是测试的汇总结果,包括测试时间、数据传输量以及带宽等。按照发送和接收,这一部分又分为了 sender 和 receiver 两行。
从测试结果你可以看到,这台机器 TCP 接收的带宽(吞吐量)为 860 Mb/s, 跟目标的 1Gb/s 相比,还是有些差距的。
HTTP 性能
要测试 HTTP 的性能,也有大量的工具可以使用,比如 ab、webbench 等,都是常用的 HTTP 压力测试工具。其中,ab 是 Apache 自带的 HTTP 压测工具,主要测试 HTTP 服务的每秒请求数、请求延迟、吞吐量以及请求延迟的分布情况等。
运行下面的命令,你就可以安装 ab 工具:
# Ubuntu
$ apt-get install -y apache2-utils
# CentOS
$ yum install -y httpd-tools
接下来,在目标机器上,使用 Docker 启动一个 Nginx 服务,然后用 ab 来测试它的性能。首先,在目标机器上运行下面的命令:
$ docker run -p 80:80 -itd nginx
而在另一台机器上,运行 ab 命令,测试 Nginx 的性能:
# -c表示并发请求数为1000,-n表示总的请求数为10000
$ ab -c 1000 -n 10000 http://192.168.0.30/
...
Server Software: nginx/1.15.8
Server Hostname: 192.168.0.30
Server Port: 80
...
Requests per second: 1078.54 [#/sec] (mean)
Time per request: 927.183 [ms] (mean)
Time per request: 0.927 [ms] (mean, across all concurrent requests)
Transfer rate: 890.00 [Kbytes/sec] received
Connection Times (ms)
min mean[+/-sd] median max
Connect: 0 27 152.1 1 1038
Processing: 9 207 843.0 22 9242
Waiting: 8 207 843.0 22 9242
Total: 15 233 857.7 23 9268
Percentage of the requests served within a certain time (ms)
50% 23
66% 24
75% 24
80% 26
90% 274
95% 1195
98% 2335
99% 4663
100% 9268 (longest request)
可以看到,ab 的测试结果分为三个部分,分别是请求汇总、连接时间汇总还有请求延迟汇总。以上面的结果为例,我们具体来看。
在请求汇总部分,你可以看到:
- Requests per second 为 1074;
- 每个请求的延迟(Time per request)分为两行,第一行的 927 ms 表示平均延迟,包括了线程运行的调度时间和网络请求响应时间,而下一行的 0.927ms ,则表示实际请求的响应时间;
- Transfer rate 表示吞吐量(BPS)为 890 KB/s。
连接时间汇总部分,则是分别展示了建立连接、请求、等待以及汇总等的各类时间,包括最小、最大、平均以及中值处理时间。
最后的请求延迟汇总部分,则给出了不同时间段内处理请求的百分比,比如, 90% 的请求,都可以在 274ms 内完成。
应用负载性能
为了得到应用程序的实际性能,就要求性能工具本身可以模拟用户的请求负载,而 iperf、ab 这类工具就无能为力了。幸运的是,我们还可以用 wrk、TCPCopy、Jmeter 或者 LoadRunner 等实现这个目标。
wrk
以 wrk 为例,它是一个 HTTP 性能测试工具,内置了 LuaJIT,方便你根据实际需求,生成所需的请求负载,或者自定义响应的处理方法。
wrk 工具本身不提供 yum 或 apt 的安装方法,需要通过源码编译来安装。比如,你可以运行下面的命令,来编译和安装 wrk:
$ https://github.com/wg/wrk
$ cd wrk
$ apt-get install build-essential -y
$ make
$ sudo cp wrk /usr/local/bin/
wrk 的命令行参数比较简单。比如,我们可以用 wrk ,来重新测一下前面已经启动的 Nginx 的性能。
# -c表示并发连接数1000,-t表示线程数为2
$ wrk -c 1000 -t 2 http://192.168.0.30/
Running 10s test @ http://192.168.0.30/
2 threads and 1000 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 65.83ms 174.06ms 1.99s 95.85%
Req/Sec 4.87k 628.73 6.78k 69.00%
96954 requests in 10.06s, 78.59MB read
Socket errors: connect 0, read 0, write 0, timeout 179
Requests/sec: 9641.31
Transfer/sec: 7.82MB
这里使用 2 个线程、并发 1000 连接,重新测试了 Nginx 的性能。你可以看到,每秒请求数为 9641,吞吐量为 7.82MB,平均延迟为 65ms,比前面 ab 的测试结果要好很多。
这也说明,性能工具本身的性能,对性能测试也是至关重要的。不合适的性能工具,并不能准确测出应用程序的最佳性能。
当然,wrk 最大的优势,是其内置的 LuaJIT,可以用来实现复杂场景的性能测试。wrk 在调用 Lua 脚本时,可以将 HTTP 请求分为三个阶段,即 setup、running、done,如下图所示:
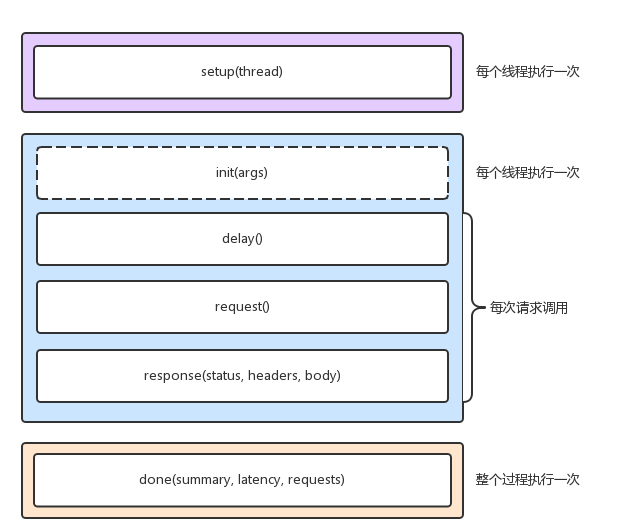
比如,你可以在 setup 阶段,为请求设置认证参数(来自于 wrk 官方示例):
-- example script that demonstrates response handling and
-- retrieving an authentication token to set on all future
-- requests
token = nil
path = "/authenticate"
request = function()
return wrk.format("GET", path)
end
response = function(status, headers, body)
if not token and status 200 then
token = headers["X-Token"]
path = "/resource"
wrk.headers["X-Token"] = token
end
end
而在执行测试时,通过 -s 选项,执行脚本的路径:
$ wrk -c 1000 -t 2 -s auth.lua http://192.168.0.30/
wrk 需要你用 Lua 脚本,来构造请求负载。这对于大部分场景来说,可能已经足够了 。不过,它的缺点也正是,所有东西都需要代码来构造,并且工具本身不提供 GUI 环境。
像 Jmeter 或者 LoadRunner(商业产品),则针对复杂场景提供了脚本录制、回放、GUI 等更丰富的功能,使用起来也更加方便。
域名与 DNS 解析
系统DNS配置
$ cat /etc/resolv.conf
nameserver 114.114.114.114
DNS 服务通过资源记录的方式,来管理所有数据,它支持 A、CNAME、MX、NS、PTR 等多种类型的记录。比如:
- A 记录,用来把域名转换成 IP 地址;
- CNAME 记录,用来创建别名;
- 而 NS 记录,则表示该域名对应的域名服务器地址。
简单来说,当我们访问某个网址时,就需要通过 DNS 的 A 记录,查询该域名对应的 IP 地址,然后再通过该 IP 来访问 Web 服务。
dig 常用的 DNS 解析工具
# +trace表示开启跟踪查询
# +nodnssec表示禁止DNS安全扩展
$ dig +trace +nodnssec time.geekbang.org
; <<>> DiG 9.11.3-1ubuntu1.3-Ubuntu <<>> +trace +nodnssec time.geekbang.org
;; global options: +cmd
. 322086 IN NS m.root-servers.net.
. 322086 IN NS a.root-servers.net.
. 322086 IN NS i.root-servers.net.
. 322086 IN NS d.root-servers.net.
. 322086 IN NS g.root-servers.net.
. 322086 IN NS l.root-servers.net.
. 322086 IN NS c.root-servers.net.
. 322086 IN NS b.root-servers.net.
. 322086 IN NS h.root-servers.net.
. 322086 IN NS e.root-servers.net.
. 322086 IN NS k.root-servers.net.
. 322086 IN NS j.root-servers.net.
. 322086 IN NS f.root-servers.net.
;; Received 239 bytes from 114.114.114.114#53(114.114.114.114) in 1340 ms
org. 172800 IN NS a0.org.afilias-nst.info.
org. 172800 IN NS a2.org.afilias-nst.info.
org. 172800 IN NS b0.org.afilias-nst.org.
org. 172800 IN NS b2.org.afilias-nst.org.
org. 172800 IN NS c0.org.afilias-nst.info.
org. 172800 IN NS d0.org.afilias-nst.org.
;; Received 448 bytes from 198.97.190.53#53(h.root-servers.net) in 708 ms
geekbang.org. 86400 IN NS dns9.hichina.com.
geekbang.org. 86400 IN NS dns10.hichina.com.
;; Received 96 bytes from 199.19.54.1#53(b0.org.afilias-nst.org) in 1833 ms
time.geekbang.org. 600 IN A 39.106.233.176
;; Received 62 bytes from 140.205.41.16#53(dns10.hichina.com) in 4 ms
dig trace 的输出,主要包括四部分:
- 第一部分,是从 114.114.114.114 查到的一些根域名服务器(.)的 NS 记录。
- 第二部分,是从 NS 记录结果中选一个(h.root-servers.net),并查询顶级域名 org. 的 NS 记录。
- 第三部分,是从 org. 的 NS 记录中选择一个(b0.org.afilias-nst.org),并查询二级域名 geekbang.org. 的 NS 服务器。
- 最后一部分,就是从 geekbang.org. 的 NS 服务器(dns10.hichina.com)查询最终主机 time.geekbang.org. 的 A 记录。
这个输出里展示的各级域名的 NS 记录,其实就是各级域名服务器的地址。
nslookup
/# time nslookup time.geekbang.org
Server: 8.8.8.8
Address: 8.8.8.8#53
Non-authoritative answer:
Name: time.geekbang.org
Address: 39.106.233.176
real 0m10.349s
user 0m0.004s
sys 0m0.0
常用的网络抓包和分析工具 tcpdump 和 Wireshark
- tcpdump 仅支持命令行格式使用,常用在服务器中抓取和分析网络包。
- Wireshark 除了可以抓包外,还提供了强大的图形界面和汇总分析工具,在分析复杂的网络情景时,尤为简单和实用。
因而,在实际分析网络性能时,先用 tcpdump 抓包,后用 Wireshark 分析,也是一种常用的方法。
tcpdump
使用 tcpdump ,解决一个最常见的 ping 工作缓慢的问题
$ tcpdump -nn udp port 53 or host 35.190.27.188
当然,你可以直接用 tcpdump 不加任何参数来抓包,但那样的话,就可能抓取到很多不相干的包。由于我们已经执行过 ping 命令,知道了 geekbang.org 的 IP 地址是 35.190.27.188,也知道 ping 命令会执行 DNS 查询。所以,上面这条命令,就是基于这个规则进行过滤。
- -nn ,表示不解析抓包中的域名(即不反向解析)、协议以及端口号。
- udp port 53 ,表示只显示 UDP 协议的端口号(包括源端口和目的端口)为 53 的包。
- host 35.190.27.188 ,表示只显示 IP 地址(包括源地址和目的地址)为 35.190.27.188 的包。
- 这两个过滤条件中间的“ or ”,表示或的关系,也就是说,只要满足上面两个条件中的任一个,就可以展示出来。
打开另一个终端:
$ ping -c3 geektime.org
...
--- geektime.org ping statistics ---
3 packets transmitted, 3 received, 0% packet loss, time 11095ms
rtt min/avg/max/mdev = 81.473/81.572/81.757/0.130 ms
回到tcpdump的终端查看输出:
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on eth0, link-type EN10MB (Ethernet), capture size 262144 bytes
14:02:31.100564 IP 172.16.3.4.56669 > 114.114.114.114.53: 36909+ A? geektime.org. (30)
14:02:31.507699 IP 114.114.114.114.53 > 172.16.3.4.56669: 36909 1/0/0 A 35.190.27.188 (46)
14:02:31.508164 IP 172.16.3.4 > 35.190.27.188: ICMP echo request, id 4356, seq 1, length 64
14:02:31.539667 IP 35.190.27.188 > 172.16.3.4: ICMP echo reply, id 4356, seq 1, length 64
14:02:31.539995 IP 172.16.3.4.60254 > 114.114.114.114.53: 49932+ PTR? 188.27.190.35.in-addr.arpa. (44)
14:02:36.545104 IP 172.16.3.4.60254 > 114.114.114.114.53: 49932+ PTR? 188.27.190.35.in-addr.arpa. (44)
14:02:41.551284 IP 172.16.3.4 > 35.190.27.188: ICMP echo request, id 4356, seq 2, length 64
14:02:41.582363 IP 35.190.27.188 > 172.16.3.4: ICMP echo reply, id 4356, seq 2, length 64
14:02:42.552506 IP 172.16.3.4 > 35.190.27.188: ICMP echo request, id 4356, seq 3, length 64
14:02:42.583646 IP 35.190.27.188 > 172.16.3.4: ICMP echo reply, id 4356, seq 3, length 64
前两行,表示 tcpdump 的选项以及接口的基本信息;从第三行开始,就是抓取到的网络包的输出。这些输出的格式,都是 时间戳 协议 源地址.源端口 > 目的地址.目的端口 网络包详细信息(这是最基本的格式,可以通过选项增加其他字段)。
详细含义:
第一条就表示,从本地 IP 发送到 114.114.114.114 的 A 记录查询请求,它的报文格式记录在 RFC1035 中,在这个 tcpdump 的输出中:
- 6909+ 表示查询标识值,它也会出现在响应中,加号表示启用递归查询。
- A? 表示查询 A 记录。
- geektime.org. 表示待查询的域名。
- 30 表示报文长度。
接下来的一条,则是从 114.114.114.114 发送回来的 DNS 响应——域名 geektime.org. 的 A 记录值为 35.190.27.188。
第三条和第四条,是 ICMP echo request 和 ICMP echo reply,响应包的时间戳 14:02:31.539667,减去请求包的时间戳 14:02:31.508164 ,就可以得到,这次 ICMP 所用时间为 30ms。这看起来并没有问题。
但随后的两条反向地址解析 PTR 请求,就比较可疑了。因为我们只看到了请求包,却没有应答包。仔细观察它们的时间,你会发现,这两条记录都是发出后 5s 才出现下一个网络包,两条 PTR 记录就消耗了 10s。
再往下看,最后的四个包,则是两次正常的 ICMP 请求和响应,根据时间戳计算其延迟,也是 30ms。
到这里,其实我们也就找到了 ping 缓慢的根源,正是两次 PTR 请求没有得到响应而超时导致的。PTR 反向地址解析的目的,是从 IP 地址反查出域名,但事实上,并非所有 IP 地址都会定义 PTR 记录,所以 PTR 查询很可能会失败。
所以,在你使用 ping 时,如果发现结果中的延迟并不大,而 ping 命令本身却很慢,不要慌,有可能是背后的 PTR 在搞鬼。
tcpdump 的使用
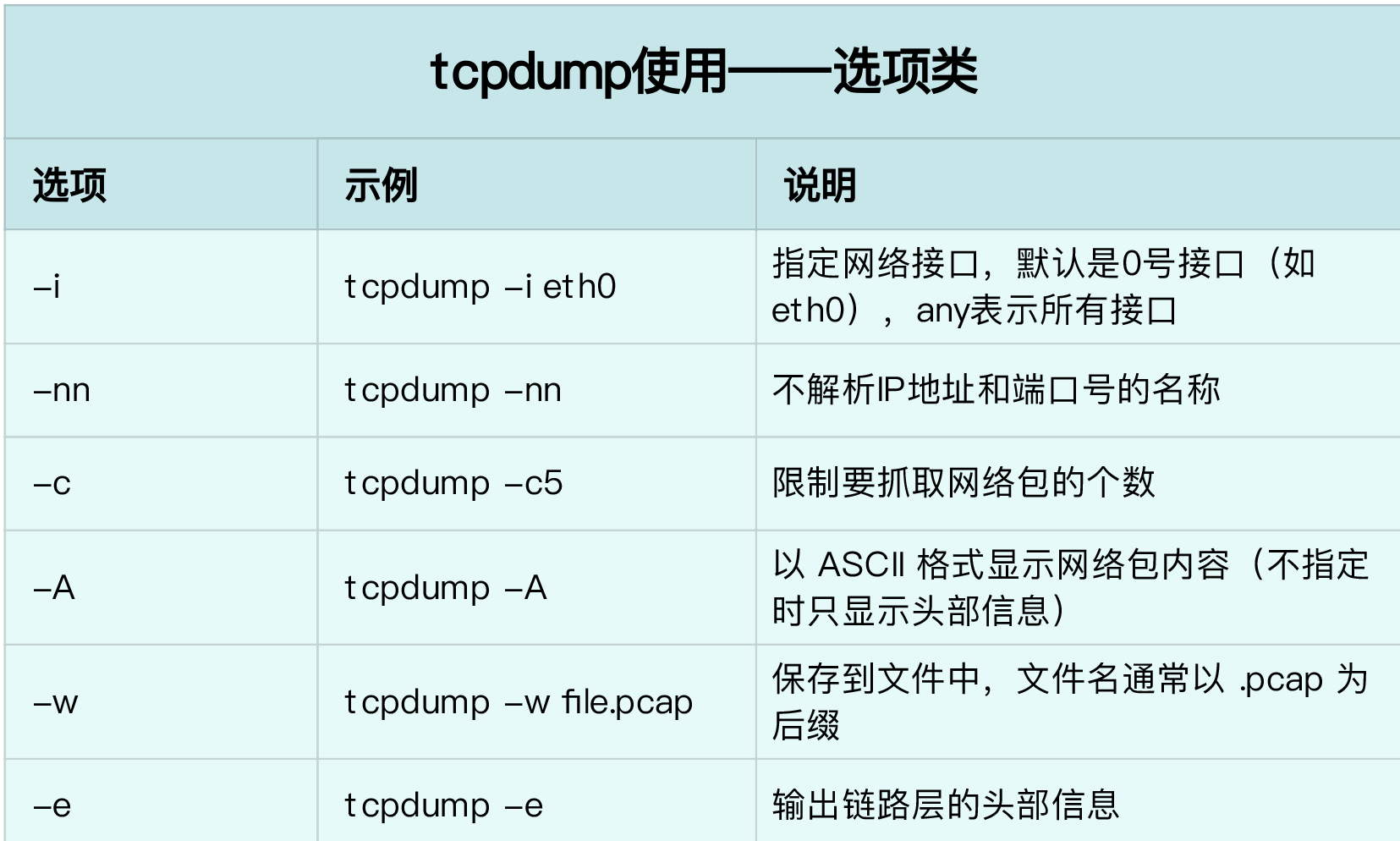
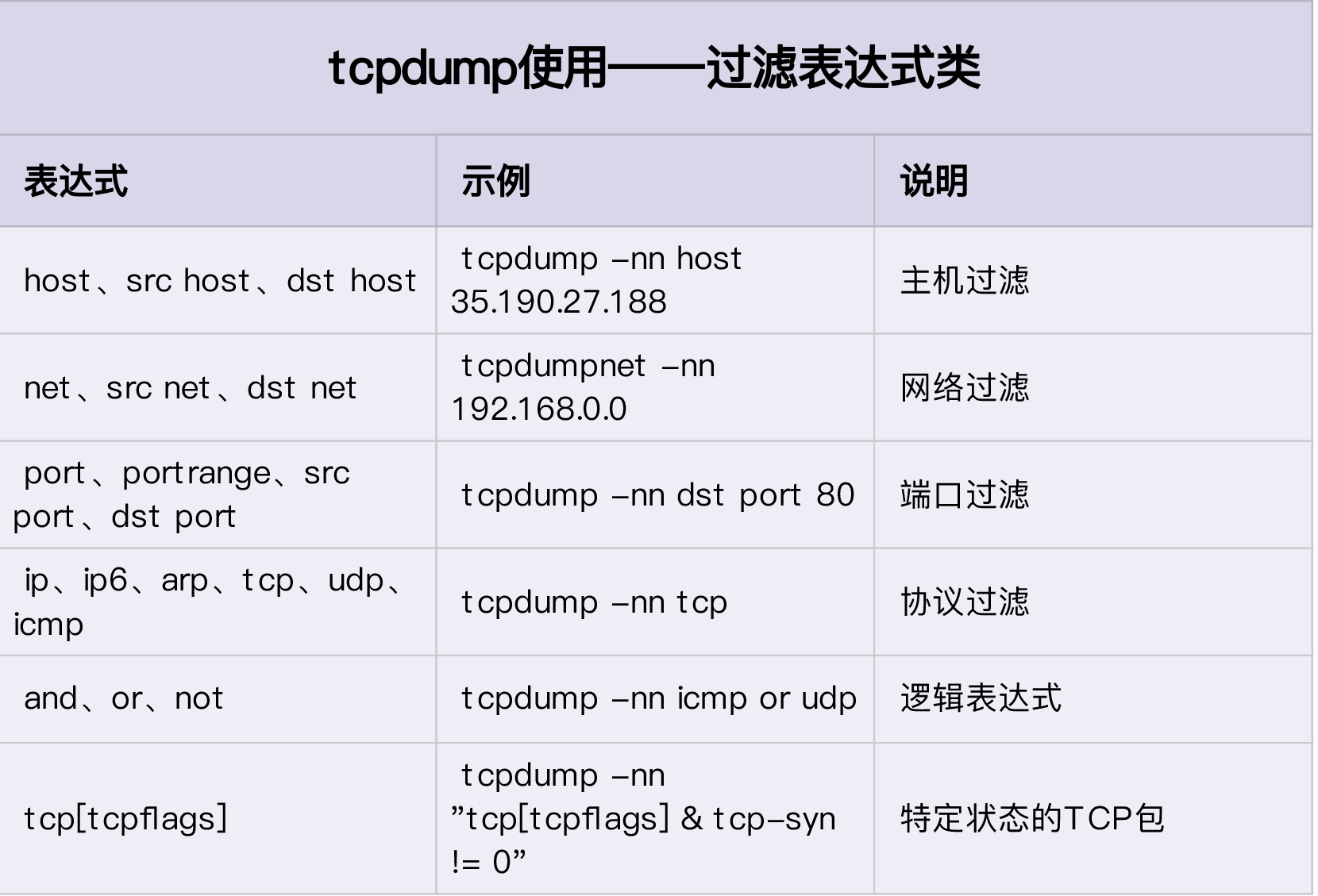
tcpdump 的基本输出格式:
时间戳 协议 源地址.源端口 > 目的地址.目的端口 网络包详细信息
Wireshark
Wireshark 也是最流行的一个网络分析工具,它最大的好处就是提供了跨平台的图形界面。跟 tcpdump 类似,Wireshark 也提供了强大的过滤规则表达式,同时,还内置了一系列的汇总分析工具。
你可以执行下面的命令,把抓取的网络包保存到 ping.pcap 文件中:
$ tcpdump -nn udp port 53 or host 35.190.27.188 -w ping.pcap
接着,把它拷贝到你安装有 Wireshark 的机器中,比如你可以用 scp 把它拷贝到本地来:
$ scp host-ip/path/ping.pcap .
然后,再用 Wireshark 打开它。打开后,你就可以看到下面这个界面:

从 Wireshark 的界面里,你可以发现,它不仅以更规整的格式,展示了各个网络包的头部信息;还用了不同颜色,展示 DNS 和 ICMP 这两种不同的协议。你也可以一眼看出,中间的两条 PTR 查询并没有响应包。
接着,在网络包列表中选择某一个网络包后,在其下方的网络包详情中,你还可以看到,这个包在协议栈各层的详细信息。比如,以编号为 5 的 PTR 包为例:
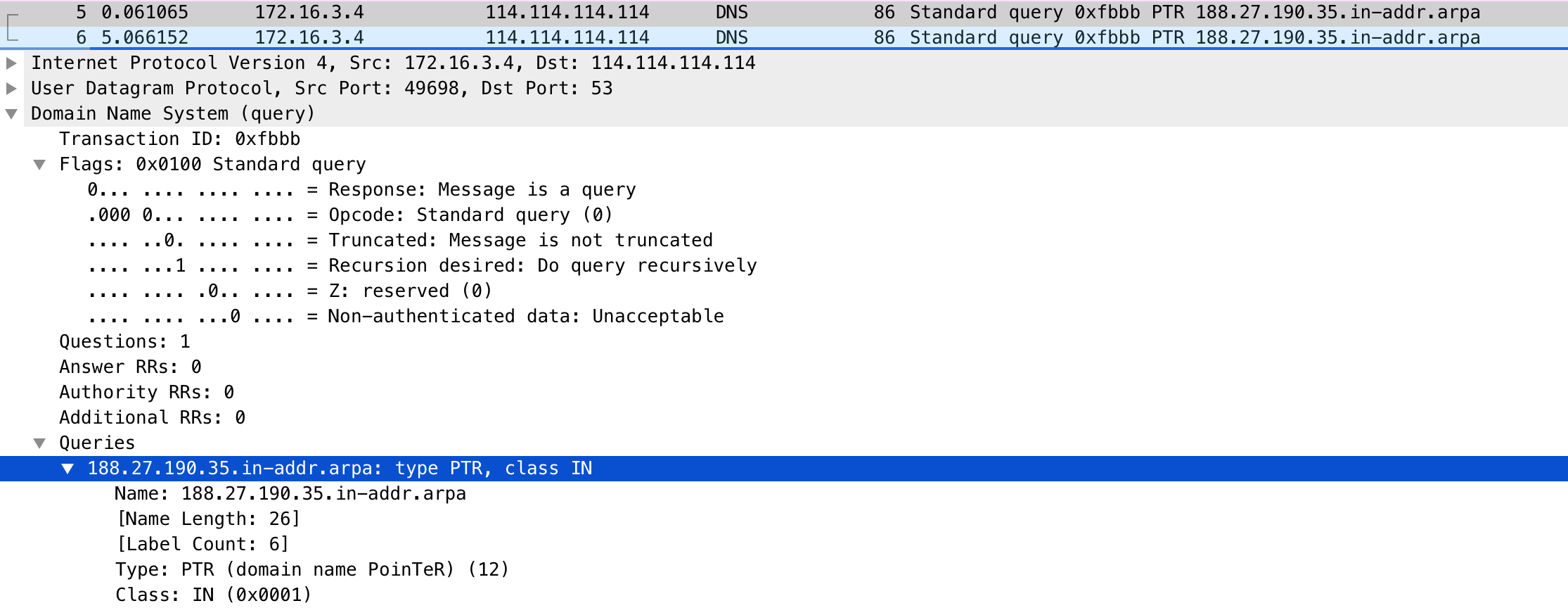
你可以看到,IP 层(Internet Protocol)的源地址和目的地址、传输层的 UDP 协议(Uder Datagram Protocol)、应用层的 DNS 协议(Domain Name System)的概要信息。
继续点击每层左边的箭头,就可以看到该层协议头的所有信息。比如点击 DNS 后,就可以看到 Transaction ID、Flags、Queries 等 DNS 协议各个字段的数值以及含义。
DDoS 简介
DDoS 的前身是 DoS(Denail of Service),即拒绝服务攻击,指利用大量的合理请求,来占用过多的目标资源,从而使目标服务无法响应正常请求。
DDoS(Distributed Denial of Service) 则是在 DoS 的基础上,采用了分布式架构,利用多台主机同时攻击目标主机。这样,即使目标服务部署了网络防御设备,面对大量网络请求时,还是无力应对。
从攻击的原理上来看,DDoS 可以分为下面几种类型:
第一种,耗尽带宽。无论是服务器还是路由器、交换机等网络设备,带宽都有固定的上限。带宽耗尽后,就会发生网络拥堵,从而无法传输其他正常的网络报文。
第二种,耗尽操作系统的资源。网络服务的正常运行,都需要一定的系统资源,像是 CPU、内存等物理资源,以及连接表等软件资源。一旦资源耗尽,系统就不能处理其他正常的网络连接。
第三种,消耗应用程序的运行资源。应用程序的运行,通常还需要跟其他的资源或系统交互。如果应用程序一直忙于处理无效请求,也会导致正常请求的处理变慢,甚至得不到响应。
由于 DDoS 的分布式、大流量、难追踪等特点,目前还没有方法可以完全防御 DDoS 带来的问题,只能设法缓解这个影响。
比如,你可以购买专业的流量清洗设备和网络防火墙,在网络入口处阻断恶意流量,只保留正常流量进入数据中心的服务器中。
在 Linux 服务器中,你可以通过内核调优、DPDK、XDP 等多种方法,来增大服务器的抗攻击能力,降低 DDoS 对正常服务的影响。而在应用程序中,你可以利用各级缓存、 WAF、CDN 等方式,缓解 DDoS 对应用程序的影响。
NAT 原理
NAT 技术可以重写 IP 数据包的源 IP 或者目的 IP,被普遍地用来解决公网 IP 地址短缺的问题。它的主要原理就是,网络中的多台主机,通过共享同一个公网 IP 地址,来访问外网资源。同时,由于 NAT 屏蔽了内网网络,自然也就为局域网中的机器提供了安全隔离。
你既可以在支持网络地址转换的路由器(称为 NAT 网关)中配置 NAT,也可以在 Linux 服务器中配置 NAT。如果采用第二种方式,Linux 服务器实际上充当的是“软”路由器的角色。
NAT 的主要目的,是实现地址转换。根据实现方式的不同,NAT 可以分为三类:
- 静态 NAT,即内网 IP 与公网 IP 是一对一的永久映射关系;
- 动态 NAT,即内网 IP 从公网 IP 池中,动态选择一个进行映射;
- 网络地址端口转换 NAPT(Network Address and Port Translation),即把内网 IP 映射到公网 IP 的不同端口上,让多个内网 IP 可以共享同一个公网 IP 地址。
NAPT 是目前最流行的 NAT 类型,我们在 Linux 中配置的 NAT 也是这种类型。而根据转换方式的不同,我们又可以把 NAPT 分为三类。
第一类是源地址转换 SNAT,即目的地址不变,只替换源 IP 或源端口。SNAT 主要用于,多个内网 IP 共享同一个公网 IP ,来访问外网资源的场景。
第二类是目的地址转换 DNAT,即源 IP 保持不变,只替换目的 IP 或者目的端口。DNAT 主要通过公网 IP 的不同端口号,来访问内网的多种服务,同时会隐藏后端服务器的真实 IP 地址。
第三类是双向地址转换,即同时使用 SNAT 和 DNAT。当接收到网络包时,执行 DNAT,把目的 IP 转换为内网 IP;而在发送网络包时,执行 SNAT,把源 IP 替换为外部 IP。
双向地址转换,其实就是外网 IP 与内网 IP 的一对一映射关系,所以常用在虚拟化环境中,为虚拟机分配浮动的公网 IP 地址。
我们假设:
- 本地服务器的内网 IP 地址为 192.168.0.2;
- NAT 网关中的公网 IP 地址为 100.100.100.100;
- 要访问的目的服务器 baidu.com 的地址为 123.125.115.110。
那么 SNAT 和 DNAT 的过程,就如下图所示:
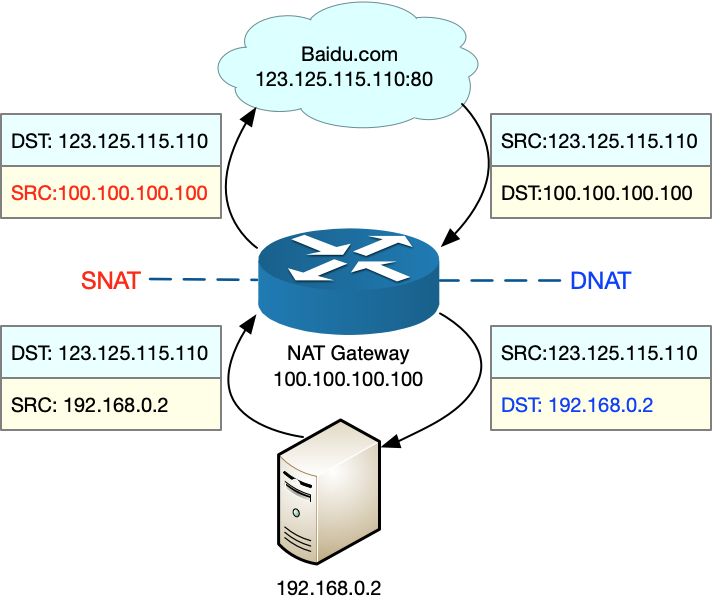
从图中,你可以发现:
- 当服务器访问 baidu.com 时,NAT 网关会把源地址,从服务器的内网 IP 192.168.0.2 替换成公网 IP 地址 100.100.100.100,然后才发送给 baidu.com;
- 当 baidu.com 发回响应包时,NAT 网关又会把目的地址,从公网 IP 地址 100.100.100.100 替换成服务器内网 IP 192.168.0.2,然后再发送给内网中的服务器。
iptables 与 NAT
Linux 内核提供的 Netfilter 框架,允许对网络数据包进行修改(比如 NAT)和过滤(比如防火墙)。在这个基础上,iptables、ip6tables、ebtables 等工具,又提供了更易用的命令行接口,以便系统管理员配置和管理 NAT、防火墙的规则。
其中,iptables 就是最常用的一种配置工具。要掌握 iptables 的原理和使用方法,最核心的就是弄清楚,网络数据包通过 Netfilter 时的工作流向,下面这张图就展示了这一过程。
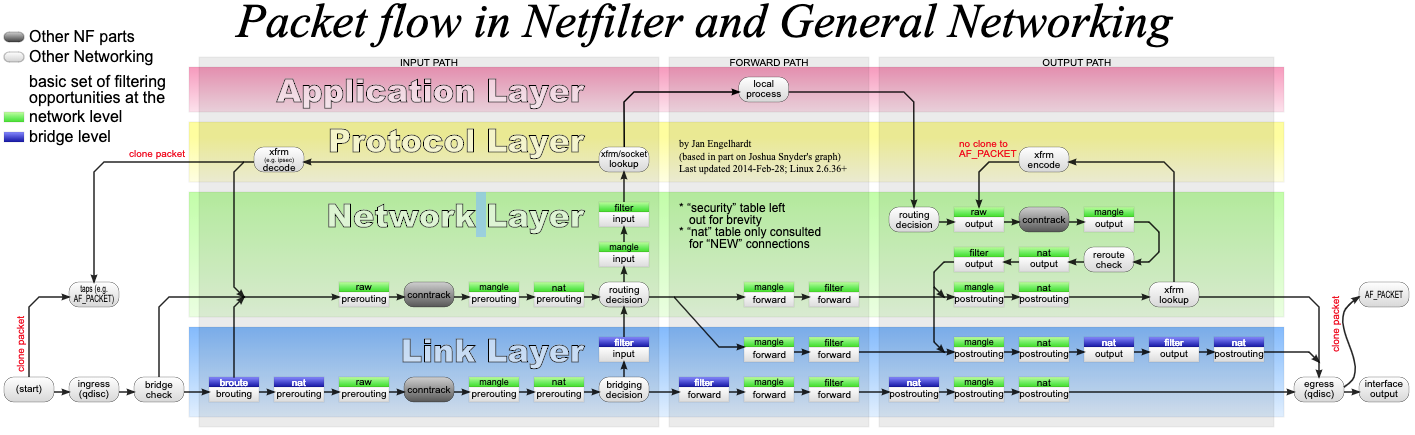
在这张图中,绿色背景的方框,表示表(table),用来管理链。Linux 支持 4 种表,包括 filter(用于过滤)、nat(用于 NAT)、mangle(用于修改分组数据) 和 raw(用于原始数据包)等。
跟 table 一起的白色背景方框,则表示链(chain),用来管理具体的 iptables 规则。每个表中可以包含多条链,比如:
- filter 表中,内置 INPUT、OUTPUT 和 FORWARD 链;
- nat 表中,内置 PREROUTING、POSTROUTING、OUTPUT 等。
当然,你也可以根据需要,创建你自己的链。
灰色的 conntrack,表示连接跟踪模块。它通过内核中的连接跟踪表(也就是哈希表),记录网络连接的状态,是 iptables 状态过滤(-m state)和 NAT 的实现基础。
iptables 的所有规则,就会放到这些表和链中,并按照图中顺序和规则的优先级顺序来执行。
针对要实现 NAT 功能,主要是在 nat 表进行操作。而 nat 表内置了三个链:
- PREROUTING,用于路由判断前所执行的规则,比如,对接收到的数据包进行 DNAT。
- POSTROUTING,用于路由判断后所执行的规则,比如,对发送或转发的数据包进行 SNAT 或 MASQUERADE。
- OUTPUT,类似于 PREROUTING,但只处理从本机发送出去的包。
熟悉 iptables 中的表和链后,相应的 NAT 规则就比较简单了。以 NAPT 的三个分类为例,来具体解读一下:
SNAT
SNAT 需要在 nat 表的 POSTROUTING 链中配置。我们常用两种方式来配置它:
第一种方法,是为一个子网统一配置 SNAT,并由 Linux 选择默认的出口 IP。这实际上就是经常说的 MASQUERADE:
$ iptables -t nat -A POSTROUTING -s 192.168.0.0/16 -j MASQUERADE
第二种方法,是为具体的 IP 地址配置 SNAT,并指定转换后的源地址:
$ iptables -t nat -A POSTROUTING -s 192.168.0.2 -j SNAT --to-source 100.100.100.100
DNAT
DNAT 需要在 nat 表的 PREROUTING 或者 OUTPUT 链中配置,其中, PREROUTING 链更常用一些(因为它还可以用于转发的包)。
$ iptables -t nat -A PREROUTING -d 100.100.100.100 -j DNAT --to-destination 192.168.0.2
双向地址转换
双向地址转换,就是同时添加 SNAT 和 DNAT 规则,为公网 IP 和内网 IP 实现一对一的映射关系,即:
$ iptables -t nat -A POSTROUTING -s 192.168.0.2 -j SNAT --to-source 100.100.100.100
$ iptables -t nat -A PREROUTING -d 100.100.100.100 -j DNAT --to-destination 192.168.0.2
在使用 iptables 配置 NAT 规则时,Linux 需要转发来自其他 IP 的网络包,所以你千万不要忘记开启 Linux 的 IP 转发功能。
你可以执行下面的命令,查看这一功能是否开启。如果输出的结果是 1,就表示已经开启了 IP 转发:
$ sysctl net.ipv4.ip_forward
net.ipv4.ip_forward = 1
如果还没开启,你可以执行下面的命令,手动开启:
$ sysctl -w net.ipv4.ip_forward=1
net.ipv4.ip_forward = 1
当然,为了避免重启后配置丢失,不要忘记将配置写入 /etc/sysctl.conf 文件中:
$ cat /etc/sysctl.conf | grep ip_forward
net.ipv4.ip_forward=1
SystemTap
SystemTap 是 Linux 的一种动态追踪框架,它把用户提供的脚本,转换为内核模块来执行,用来监测和跟踪内核的行为。
# Ubuntu
apt-get install -y systemtap-runtime systemtap
# Configure ddebs source
echo "deb http://ddebs.ubuntu.com $(lsb_release -cs) main restricted universe multiverse
deb http://ddebs.ubuntu.com $(lsb_release -cs)-updates main restricted universe multiverse
deb http://ddebs.ubuntu.com $(lsb_release -cs)-proposed main restricted universe multiverse" | \
sudo tee -a /etc/apt/sources.list.d/ddebs.list
# Install dbgsym
apt-key adv --keyserver keyserver.ubuntu.com --recv-keys F2EDC64DC5AEE1F6B9C621F0C8CAB6595FDFF622
apt-get update
apt install ubuntu-dbgsym-keyring
stap-prep
apt-get install linux-image-`uname -r`-dbgsym
# CentOS
yum install systemtap kernel-devel yum-utils kernel
stab-prep
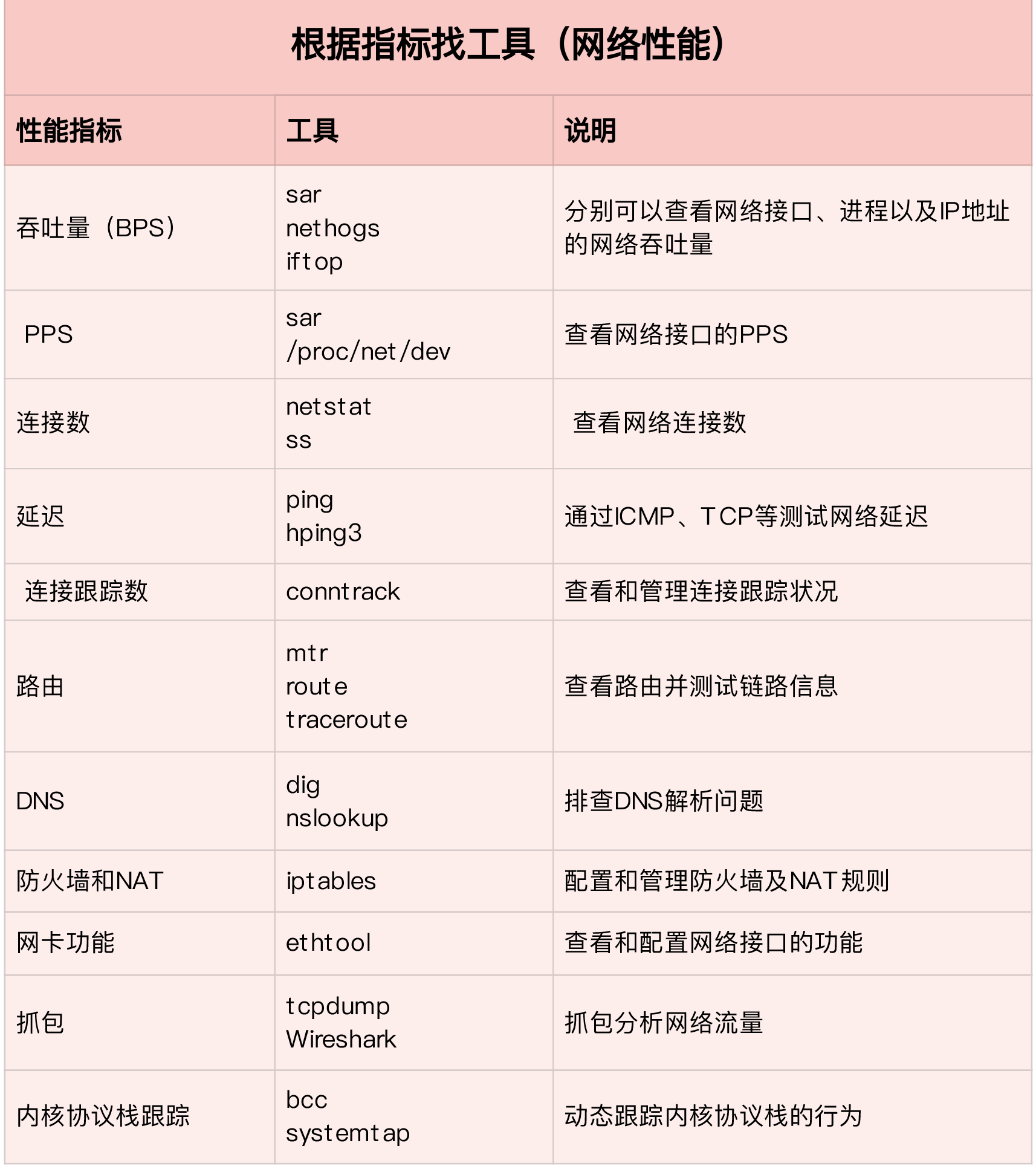
网络性能工具
网络性能优化
OOM案例分析
当 OOM 发生时,系统会把相关的 OOM 信息,记录到日志中。所以,接下来,我们可以在终端中执行 dmesg 命令,查看系统日志,并定位 OOM 相关的日志:
$ dmesg
[193038.106393] java invoked oom-killer: gfp_mask=0x14000c0(GFP_KERNEL), nodemask=(null), order=0, oom_score_adj=0
[193038.106396] java cpuset=0f2b3fcdd2578165ea77266cdc7b1ad43e75877b0ac1889ecda30a78cb78bd53 mems_allowed=0
[193038.106402] CPU: 0 PID: 27424 Comm: java Tainted: G OE 4.15.0-1037 #39-Ubuntu
[193038.106404] Hardware name: Microsoft Corporation Virtual Machine/Virtual Machine, BIOS 090007 06/02/2017
[193038.106405] Call Trace:
[193038.106414] dump_stack+0x63/0x89
[193038.106419] dump_header+0x71/0x285
[193038.106422] oom_kill_process+0x220/0x440
[193038.106424] out_of_memory+0x2d1/0x4f0
[193038.106429] mem_cgroup_out_of_memory+0x4b/0x80
[193038.106432] mem_cgroup_oom_synchronize+0x2e8/0x320
[193038.106435] ? mem_cgroup_css_online+0x40/0x40
[193038.106437] pagefault_out_of_memory+0x36/0x7b
[193038.106443] mm_fault_error+0x90/0x180
[193038.106445] __do_page_fault+0x4a5/0x4d0
[193038.106448] do_page_fault+0x2e/0xe0
[193038.106454] ? page_fault+0x2f/0x50
[193038.106456] page_fault+0x45/0x50
[193038.106459] RIP: 0033:0x7fa053e5a20d
[193038.106460] RSP: 002b:00007fa0060159e8 EFLAGS: 00010206
[193038.106462] RAX: 0000000000000000 RBX: 00007fa04c4b3000 RCX: 0000000009187440
[193038.106463] RDX: 00000000943aa440 RSI: 0000000000000000 RDI: 000000009b223000
[193038.106464] RBP: 00007fa006015a60 R08: 0000000002000002 R09: 00007fa053d0a8a1
[193038.106465] R10: 00007fa04c018b80 R11: 0000000000000206 R12: 0000000100000768
[193038.106466] R13: 00007fa04c4b3000 R14: 0000000100000768 R15: 0000000010000000
[193038.106468] Task in /docker/0f2b3fcdd2578165ea77266cdc7b1ad43e75877b0ac1889ecda30a78cb78bd53 killed as a result of limit of /docker/0f2b3fcdd2578165ea77266cdc7b1ad43e75877b0ac1889ecda30a78cb78bd53
[193038.106478] memory: usage 524288kB, limit 524288kB, failcnt 77
[193038.106480] memory+swap: usage 0kB, limit 9007199254740988kB, failcnt 0
[193038.106481] kmem: usage 3708kB, limit 9007199254740988kB, failcnt 0
[193038.106481] Memory cgroup stats for /docker/0f2b3fcdd2578165ea77266cdc7b1ad43e75877b0ac1889ecda30a78cb78bd53: cache:0KB rss:520580KB rss_huge:450560KB shmem:0KB mapped_file:0KB dirty:0KB writeback:0KB inactive_anon:0KB active_anon:520580KB inactive_file:0KB active_file:0KB unevictable:0KB
[193038.106494] [ pid ] uid tgid total_vm rss pgtables_bytes swapents oom_score_adj name
[193038.106571] [27281] 0 27281 1153302 134371 1466368 0 0 java
[193038.106574] Memory cgroup out of memory: Kill process 27281 (java) score 1027 or sacrifice child
[193038.148334] Killed process 27281 (java) total-vm:4613208kB, anon-rss:517316kB, file-rss:20168kB, shmem-rss:0kB
[193039.607503] oom_reaper: reaped process 27281 (java), now anon-rss:0kB, file-rss:0kB, shmem-rss:0kB
从 dmesg 的输出,你就可以看到很详细的 OOM 记录了。你应该可以看到下面几个关键点。
- 第一,被杀死的是一个 java 进程。从内核调用栈上的 mem_cgroup_out_of_memory 可以看出,它是因为超过 cgroup 的内存限制,而被 OOM 杀死的。
- 第二,java 进程是在容器内运行的,而容器内存的使用量和限制都是 512M(524288kB)。目前使用量已经达到了限制,所以会导致 OOM。
- 第三,被杀死的进程,PID 为 27281,虚拟内存为 4.3G(total-vm:4613208kB),匿名内存为 505M(anon-rss:517316kB),页内存为 19M(20168kB)。换句话说,匿名内存是主要的内存占用。而且,匿名内存加上页内存,总共是 524M,已经超过了 512M 的限制。
综合这几点,可以看出,Tomcat 容器的内存主要用在了匿名内存中,而匿名内存,其实就是主动申请分配的堆内存。
不过,为什么 Tomcat 会申请这么多的堆内存呢?要知道,Tomcat 是基于 Java 开发的,所以应该不难想到,这很可能是 JVM 堆内存配置的问题。
我们知道,JVM 根据系统的内存总量,来自动管理堆内存,不明确配置的话,堆内存的默认限制是物理内存的四分之一。不过,前面我们已经限制了容器内存为 512 M,java 的堆内存到底是多少呢?
执行下面的命令,启动 tomcat 容器,并调用 java 命令行来查看堆内存大小:
# 启动容器
$ docker run --name tomcat --cpus 0.1 -m 512M -p 8080:8080 -itd feisky/tomcat:8
# 查看堆内存,注意单位是字节
$ docker exec tomcat java -XX:+PrintFlagsFinal -version | grep HeapSize
uintx ErgoHeapSizeLimit = 0 {product}
uintx HeapSizePerGCThread = 87241520 {product}
uintx InitialHeapSize := 132120576 {product}
uintx LargePageHeapSizeThreshold = 134217728 {product}
uintx MaxHeapSize := 2092957696 {product}
你可以看到,初始堆内存的大小(InitialHeapSize)是 126MB,而最大堆内存则是 1.95GB,这可比容器限制的 512 MB 大多了。
之所以会这么大,其实是因为,容器内部看不到 Docker 为它设置的内存限制。虽然在启动容器时,我们通过 -m 512M 选项,给容器设置了 512M 的内存限制。但实际上,从容器内部看到的限制,却并不是 512M。
我们在终端中,继续执行下面的命令:
$ docker exec tomcat free -m
total used free shared buff/cache available
Mem: 7977 521 1941 0 5514 7148
Swap: 0 0 0
果然,容器内部看到的内存,仍是主机内存。
知道了问题根源,解决方法就很简单了,给 JVM 正确配置内存限制为 512M 就可以了。
比如,你可以执行下面的命令,通过环境变量 JAVA_OPTS=’-Xmx512m -Xms512m’ ,把 JVM 的初始内存和最大内存都设为 512MB:
# 删除问题容器
$ docker rm -f tomcat
# 运行新的容器
$ docker run --name tomcat --cpus 0.1 -m 512M -e JAVA_OPTS='-Xmx512m -Xms512m' -p 8080:8080 -itd feisky/tomcat:8