Docker与K8s学习笔记
问:什么是容器编排?
“编排”显然就是对 Docker 容器的一系列定义、配置和创建动作的管理。
问:Linux 容器最基本的实现原理?
Docker 容器这个听起来玄而又玄的概念,实际上是在创建容器进程时,指定了这个进程所需要启用的一组 Namespace 参数。这样,容器就只能“看”到当前 Namespace 所限定的资源、文件、设备、状态,或者配置。而对于宿主机以及其他不相关的程序,它就完全看不到了。所以说,容器,其实是一种特殊的进程而已。
一个正在运行的 Docker 容器,其实就是一个启用了多个 Linux Namespace 的应用进程,而这个进程能够使用的资源量,则受 Cgroups 配置的限制。这也是容器技术中一个非常重要的概念,即:容器是一个“单进程”模型。
问:Docker 项目默认会为容器启用哪些 Namespace?
cgroup uts pid net mount ipc user
独立的hostname、domain name:uts namespace
问:容器与虚拟机的优劣
敏捷”和“高性能”是容器相较于虚拟机最大的优势,也是它能够在 PaaS 这种更细粒度的资源管理平台上大行其道的重要原因。
基于 Linux Namespace 的隔离机制相比于虚拟化技术也有很多不足之处,其中最主要的问题就是:隔离得不彻底。
首先,既然容器只是运行在宿主机上的一种特殊的进程,那么多个容器之间使用的就还是同一个宿主机的操作系统内核。
其次,在 Linux 内核中,有很多资源和对象是不能被 Namespace 化的,最典型的例子就是:时间。
Linux Cgroups 就是 Linux 内核中用来为进程设置资源限制的一个重要功能。
Linux Cgroups 的全称是 Linux Control Group。它最主要的作用,就是限制一个进程组能够使用的资源上限,包括 CPU、内存、磁盘、网络带宽等等。
在 Linux 中,Cgroups 给用户暴露出来的操作接口是文件系统,即它以文件和目录的方式组织在操作系统的 /sys/fs/cgroup 路径下。
你是否知道如何修复容器中的 top 指令以及 /proc 文件系统中的信息呢?(提示:lxcfs)
top 是从 /prof/stats 目录下获取数据,所以道理上来讲,容器不挂载宿主机的该目录就可以了。
lxcfs就是来实现这个功能的,做法是把宿主机的 /var/lib/lxcfs/proc/memoinfo 文件挂载到Docker容器的/proc/meminfo位置后。
容器中进程读取相应文件内容时,LXCFS的FUSE实现会从容器对应的Cgroup中读取正确的内存限制。从而使得应用获得正确的资源约束设定。kubernetes环境下,也能用,以ds 方式运行 lxcfs ,自动给容器注入争取的 proc 信息。
Mount Namespace 跟其他 Namespace 的使用略有不同的地方:
它对容器进程视图的改变,一定是伴随着挂载操作(mount)才能生效。
Docker 最核心的原理?
为待创建的用户进程:
- 启用 Linux Namespace 配置;
- 设置指定的 Cgroups 参数;
- 切换进程的根目录(Change Root)。
- 这样,一个完整的容器就诞生了。不过,Docker 项目在最后一步的切换上会优先使用 pivot_root 系统调用,如果系统不支持,才会使用 chroot。
另外,需要明确的是,rootfs 只是一个操作系统所包含的文件、配置和目录,并不包括操作系统内核。在 Linux 操作系统中,这两部分是分开存放的,操作系统只有在开机启动时才会加载指定版本的内核镜像。
所以说,rootfs 只包括了操作系统的“躯壳”,并没有包括操作系统的“灵魂”。同一台机器上的所有容器,都共享宿主机操作系统的内核。
容器镜像
容器镜像(即 rootfs)Docker 在镜像的设计中,引入了层(layer)的概念。也就是说,用户制作镜像的每一步操作,都会生成一个层,也就是一个增量 rootfs。
联合文件系统(Union File System) 也叫 UnionFS,最主要的功能是将多个不同位置的目录联合挂载(union mount)到同一个目录下。
容器的 rootfs 由三部分组成
第一部分,只读层。
它们的挂载方式都是只读的(ro+wh,即 readonly+whiteout,至于什么是 whiteout,我下面马上会讲到)。
第二部分,可读写层。
它是这个容器的 rootfs 最上面的一层,它的挂载方式为:rw,即 read write。在没有写入文件之前,这个目录是空的。而一旦在容器里做了写操作,你修改产生的内容就会以增量的方式出现在这个层中。
为了删除操作,AuFS 会在可读写层创建一个 whiteout 文件,把只读层里的文件“遮挡”起来。比如,你要删除只读层里一个名叫 foo 的文件,那么这个删除操作实际上是在可读写层创建了一个名叫.wh.foo 的文件。这样,当这两个层被联合挂载之后,foo 文件就会被.wh.foo 文件“遮挡”起来,“消失”了。这个功能,就是“ro+wh”的挂载方式,即只读 +whiteout 的含义。我喜欢把 whiteout 形象地翻译为:“白障”。
第三部分,Init 层。
它是一个以“-init”结尾的层,夹在只读层和读写层之间。Init 层是 Docker 项目单独生成的一个内部层,专门用来存放 /etc/hosts、/etc/resolv.conf 等信息。
容器的 rootfs(比如,Ubuntu 镜像),是以只读方式挂载的,那么又如何在容器里修改 Ubuntu 镜像的内容呢?(提示:Copy-on-Write)
上面的读写层通常也称为容器层,下面的只读层称为镜像层,所有的增删查改操作都只会作用在容器层,相同的文件上层会覆盖掉下层。知道这一点,就不难理解镜像文件的修改,比如修改一个文件的时候,首先会从上到下查找有没有这个文件,找到,就复制到容器层中,修改,修改的结果就会作用到下层的文件,这种方式也被称为copy-on-write。
Centos与Ubuntu默认使用哪种UnionFS? 还有哪些UnionFs
Centos与Ubuntu默认使用 overlay2
包括但不限于以下这几种:aufs, device mapper, btrfs, overlayfs, vfs, zfs。aufs是ubuntu 常用的,device mapper 是 centos,btrfs 是 SUSE,overlayfs ubuntu 和 centos 都会使用
docker exec 的实现原理
一个进程,可以选择加入到某个进程已有的 Namespace 当中,从而达到“进入”这个进程所在容器的目的,这正是 docker exec 的实现原理。而这个操作所依赖的,乃是一个名叫 setns() 的 Linux 系统调用。
cgroup 的 Namespace
你在查看 Docker 容器的 Namespace 时,是否注意到有一个叫 cgroup 的 Namespace?它是 Linux 4.6 之后新增加的一个 Namespace,你知道它的作用吗?
Linux 内核从 4.6 开始,支持了一个新的 Namespace 叫作:Cgroup Namespace。 我们知道,正常情况下,在一个容器里查看 /proc/$PID/cgroup,是会看到整个宿主机的 cgroup 信息的。而有了 Cgroup Namespace 后,每个容器里的进程都会有自己 Cgroup Namespace,从而获得一个属于自己的 Cgroups 文件目录视图。也就是说,Cgroups 文件系统也可以被 Namespace 隔离起来了。
容器的本质
一个“容器”,实际上是一个由 Linux Namespace、Linux Cgroups 和 rootfs 三种技术构建出来的进程的隔离环境。
从这个结构中我们不难看出,一个正在运行的 Linux 容器,其实可以被“一分为二”地看待:
-
一组联合挂载在 /var/lib/docker/aufs/mnt 上的 rootfs,这一部分我们称为“容器镜像”(Container Image),是容器的静态视图;
-
一个由 Namespace+Cgroups 构成的隔离环境,这一部分我们称为“容器运行时”(Container Runtime),是容器的动态视图。
容器的“单进程模型”
容器的“单进程模型”,并不是指容器里只能运行“一个”进程,而是指容器没有管理多个进程的能力。
这是因为容器里 PID=1 的进程就是应用本身,其他的进程都是这个 PID=1 进程的子进程。
可是,用户编写的应用,并不能够像正常操作系统里的 init 进程或者 systemd 那样拥有进程管理的功能。
比如,你的应用是一个 Java Web 程序(PID=1),然后你执行 docker exec 在后台启动了一个 Nginx 进程(PID=3)。
可是,当这个 Nginx 进程异常退出的时候,你该怎么知道呢?这个进程退出后的垃圾收集工作,又应该由谁去做呢?
Kubernetes架构
由 Master 和 Node 两种节点组成,而这两种角色分别对应着控制节点和计算节点。
其中,控制节点,即 Master 节点,由三个紧密协作的独立组件组合而成,它们分别是负责 API 服务的 kube-apiserver、负责调度的 kube-scheduler,以及负责容器编排的 kube-controller-manager。整个集群的持久化数据,则由 kube-apiserver 处理后保存在 Etcd 中。
kubelet
在 Kubernetes 项目中,kubelet 主要负责同容器运行时(比如 Docker 项目)打交道。
而这个交互所依赖的,是一个称作 CRI(Container Runtime Interface) 的远程调用接口,这个接口定义了容器运行时的各项核心操作,比如:启动一个容器需要的所有参数。
Kubernetes 项目并不关心你部署的是什么容器运行时、使用的什么技术实现,只要你的这个容器运行时能够运行标准的容器镜像,它就可以通过实现 CRI 接入到 Kubernetes 项目当中。
此外,kubelet 还通过 gRPC 协议同一个叫作 Device Plugin 的插件进行交互。这个插件,是 Kubernetes 项目用来管理 GPU 等宿主机物理设备的主要组件,也是基于 Kubernetes 项目进行机器学习训练、高性能作业支持等工作必须关注的功能。
kubelet 的另一个重要功能,则是调用网络插件和存储插件为容器配置网络和持久化存储。这两个插件与 kubelet 进行交互的接口,分别是 CNI(Container Networking Interface) 和 CSI(Container Storage Interface) 。
声明式 API
首先,通过一个“编排对象”,比如 Pod、Job、CronJob 等,来描述你试图管理的应用;
然后,再为它定义一些“服务对象”,比如 Service、Secret、Horizontal Pod Autoscaler(自动水平扩展器)等。这些对象,会负责具体的平台级功能。
这种使用方法,就是所谓的“声明式 API”。这种 API 对应的“编排对象”和“服务对象”,都是 Kubernetes 项目中的 API 对象(API Object)。
在 Kubernetes 之前,很多项目都没办法管理“有状态”的容器,即,不能从一台宿主机“迁移”到另一台宿主机上的容器。你是否能列举出,阻止这种“迁移”的原因都有哪些呢?
因为迁移的是容器的rootfs,但是一些动态视图是没有办法伴随迁移一同进行迁移的。对于缓存,临时存储的数据就不太好迁移。
kubeadm init 的工作流程
当你执行 kubeadm init 指令后,kubeadm 首先要做的,是一系列的检查工作,以确定这台机器可以用来部署 Kubernetes。这一步检查,我们称为“Preflight Checks”,它可以为你省掉很多后续的麻烦。
其实,Preflight Checks 包括了很多方面,比如:
- Linux 内核的版本必须是否是 3.10 以上?
- Linux Cgroups 模块是否可用?
- 机器的 hostname 是否标准?在 Kubernetes 项目里,机器的名字以及一切存储在 Etcd 中的 API 对象,都必须使用标准的 DNS 命名(RFC 1123)。
- 用户安装的 kubeadm 和 kubelet 的版本是否匹配?
- 机器上是不是已经安装了 Kubernetes 的二进制文件?
- Kubernetes 的工作端口 10250/10251/10252 端口是不是已经被占用?
- ip、mount 等 Linux 指令是否存在?Docker 是否已经安装?
- ……
在通过了 Preflight Checks 之后,kubeadm 要为你做的,是生成 Kubernetes 对外提供服务所需的各种证书和对应的目录。
Kubernetes各个端口对应的服务6443;10250;10251;10252;10255;10256;30000-32767;
- 6443* Kubernetes API server
- 10250 Kubelet API
- 10251 kube-scheduler
- 10252 kube-controller-manager
- 10255 Read-only Kubelet API
- 10256 kube-proxy
- 30000-32767 NodePort Services**
在实际使用 Kubernetes 的过程中,相比于编写一个单独的 Pod 的 YAML 文件,我一定会推荐你使用一个 replicas=1 的 Deployment。请问,这两者有什么区别呢?
单独的pod只能在节点健康的情况下由kubelet保证pod的健康状况
推荐使用replica=1而不使用单独pod的主要原因是pod所在的节点出故障的时候 pod可以调度到健康的节点上
Pod 的实现原理
首先,关于 Pod 最重要的一个事实是:它只是一个逻辑概念。
也就是说,Kubernetes 真正处理的,还是宿主机操作系统上 Linux 容器的 Namespace 和 Cgroups,而并不存在一个所谓的 Pod 的边界或者隔离环境。那么,Pod 又是怎么被“创建”出来的呢?答案是:Pod,其实是一组共享了某些资源的容器。
具体的说:Pod 里的所有容器,共享的是同一个 Network Namespace,并且可以声明共享同一个 Volume。
那这么来看的话,一个有 A、B 两个容器的 Pod,不就是等同于一个容器(容器 A)共享另外一个容器(容器 B)的网络和 Volume 的玩儿法么
这好像通过 docker run --net --volumes-from 这样的命令就能实现嘛,比如:
$ docker run --net=B --volumes-from=B --name=A image-A ...
但是,你有没有考虑过,如果真这样做的话,容器 B 就必须比容器 A 先启动,这样一个 Pod 里的多个容器就不是对等关系,而是拓扑关系了。
所以,在 Kubernetes 项目里,Pod 的实现需要使用一个中间容器,这个容器叫作 Infra 容器。在这个 Pod 中,Infra 容器永远都是第一个被创建的容器,而其他用户定义的容器,则通过 Join Network Namespace 的方式,与 Infra 容器关联在一起。这样的组织关系,可以用下面这样一个示意图来表达:
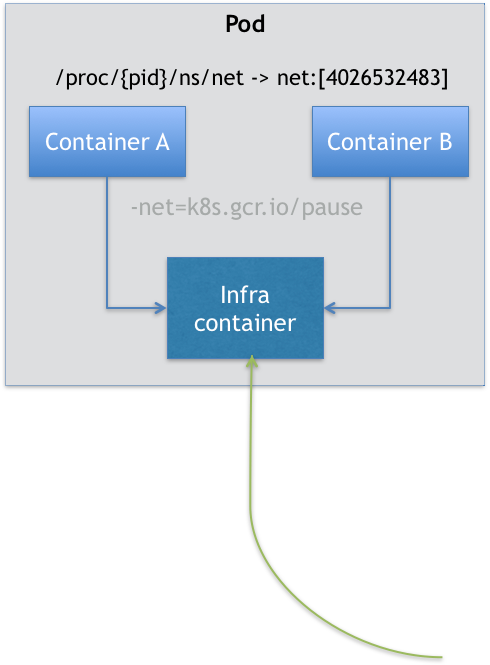
如上图所示,这个 Pod 里有两个用户容器 A 和 B,还有一个 Infra 容器。很容易理解,在 Kubernetes 项目里,Infra 容器一定要占用极少的资源,所以它使用的是一个非常特殊的镜像,叫作:k8s.gcr.io/pause。这个镜像是一个用汇编语言编写的、永远处于“暂停”状态的容器,解压后的大小也只有 100~200 KB 左右。
而在 Infra 容器“Hold 住”Network Namespace 后,用户容器就可以加入到 Infra 容器的 Network Namespace 当中了。所以,如果你查看这些容器在宿主机上的 Namespace 文件(这个 Namespace 文件的路径,我已经在前面的内容中介绍过),它们指向的值一定是完全一样的。这也就意味着,对于 Pod 里的容器 A 和容器 B 来说:
- 它们可以直接使用 localhost 进行通信;
- 它们看到的网络设备跟 Infra 容器看到的完全一样;
- 一个 Pod 只有一个 IP 地址,也就是这个 Pod 的 Network Namespace 对应的 IP 地址;
- 当然,其他的所有网络资源,都是一个 Pod 一份,并且被该 Pod 中的所有容器共享;
- Pod 的生命周期只跟 Infra 容器一致,而与容器 A 和 B 无关。
Pod 这种“超亲密关系”容器的设计思想,实际上就是希望,当用户想在一个容器里跑多个功能并不相关的应用时,应该优先考虑它们是不是更应该被描述成一个 Pod 里的多个容器。
为了能够掌握这种思考方式,你就应该尽量尝试使用它来描述一些用单个容器难以解决的问题。
第一个最典型的例子是:WAR 包与 Web 服务器。
我们现在有一个 Java Web 应用的 WAR 包,它需要被放在 Tomcat 的 webapps 目录下运行起来。
假如,你现在只能用 Docker 来做这件事情,那该如何处理这个组合关系呢?
- 一种方法是,把 WAR 包直接放在 Tomcat 镜像的 webapps 目录下,做成一个新的镜像运行起来。可是,这时候,如果你要更新 WAR 包的内容,或者要升级 Tomcat 镜像,就要重新制作一个新的发布镜像,非常麻烦。
- 另一种方法是,你压根儿不管 WAR 包,永远只发布一个 Tomcat 容器。不过,这个容器的 webapps 目录,就必须声明一个 hostPath 类型的 Volume,从而把宿主机上的 WAR 包挂载进 Tomcat 容器当中运行起来。不过,这样你就必须要解决一个问题,即:如何让每一台宿主机,都预先准备好这个存储有 WAR 包的目录呢?这样来看,你只能独立维护一套分布式存储系统了。
实际上,有了 Pod 之后,这样的问题就很容易解决了。我们可以把 WAR 包和 Tomcat 分别做成镜像,然后把它们作为一个 Pod 里的两个容器“组合”在一起。这个 Pod 的配置文件如下所示:
apiVersion: v1
kind: Pod
metadata:
name: javaweb-2
spec:
initContainers:
- image: geektime/sample:v2
name: war
command: ["cp", "/sample.war", "/app"]
volumeMounts:
- mountPath: /app
name: app-volume
containers:
- image: geektime/tomcat:7.0
name: tomcat
command: ["sh","-c","/root/apache-tomcat-7.0.42-v2/bin/start.sh"]
volumeMounts:
- mountPath: /root/apache-tomcat-7.0.42-v2/webapps
name: app-volume
ports:
- containerPort: 8080
hostPort: 8001
volumes:
- name: app-volume
emptyDir: {}
在这个 Pod 中,我们定义了两个容器,第一个容器使用的镜像是 geektime/sample:v2,这个镜像里只有一个 WAR 包(sample.war)放在根目录下。而第二个容器则使用的是一个标准的 Tomcat 镜像。不过,你可能已经注意到,WAR 包容器的类型不再是一个普通容器,而是一个 Init Container 类型的容器
在 Pod 中,所有 Init Container 定义的容器,都会比 spec.containers 定义的用户容器先启动。并且,Init Container 容器会按顺序逐一启动,而直到它们都启动并且退出了,用户容器才会启动。
所以,这个 Init Container 类型的 WAR 包容器启动后,我执行了一句"cp /sample.war /app",把应用的 WAR 包拷贝到 /app 目录下,然后退出。
而后这个 /app 目录,就挂载了一个名叫 app-volume 的 Volume。
接下来就很关键了。Tomcat 容器,同样声明了挂载 app-volume 到自己的 webapps 目录下。
所以,等 Tomcat 容器启动时,它的 webapps 目录下就一定会存在 sample.war 文件:这个文件正是 WAR 包容器启动时拷贝到这个 Volume 里面的,而这个 Volume 是被这两个容器共享的。
像这样,我们就用一种“组合”方式,解决了 WAR 包与 Tomcat 容器之间耦合关系的问题。
实际上,这个所谓的“组合”操作,正是容器设计模式里最常用的一种模式,它的名字叫:sidecar。
顾名思义,sidecar 指的就是我们可以在一个 Pod 中,启动一个辅助容器,来完成一些独立于主进程(主容器)之外的工作。
比如,在我们的这个应用 Pod 中,Tomcat 容器是我们要使用的主容器,而 WAR 包容器的存在,只是为了给它提供一个 WAR 包而已。所以,我们用 Init Container 的方式优先运行 WAR 包容器,扮演了一个 sidecar 的角色。
关于部署 war 包和 tomcat,在升级 war 的时候,先修改 yaml,然后 Kubernetes 会重启整个 pod,然后按照定义好的容器启动顺序流程走下去?
实际上,当一个 Pod 里的容器镜像被更新后,kubelet 本身就能够判断究竟是哪个容器需要更新,而不会“无脑”地重建整个 Pod。当然,你的 Tomcat 需要配置好 reloadable=“true”,这样就不需要重启 Tomcat 服务器了,这是一个非常常见的做法。
理解 Pod 的本质
Pod,实际上是在扮演传统基础设施里“虚拟机”的角色;而容器,则是这个虚拟机里运行的用户程序。
所以当你需要把一个运行在虚拟机里的应用迁移到 Docker 容器中时,一定要仔细分析到底有哪些进程(组件)运行在这个虚拟机里。
然后,你就可以把整个虚拟机想象成为一个 Pod,把这些进程分别做成容器镜像,把有顺序关系的容器,定义为 Init Container。这才是更加合理的、松耦合的容器编排诀窍,也是从传统应用架构,到“微服务架构”最自然的过渡方式。
Pod 中几个重要字段的含义和用法
NodeSelector:是一个供用户将 Pod 与 Node 进行绑定的字段
NodeName:一旦 Pod 的这个字段被赋值,Kubernetes 项目就会被认为这个 Pod 已经经过了调度,调度的结果就是赋值的节点名字。所以,这个字段一般由调度器负责设置,但用户也可以设置它来“骗过”调度器,当然这个做法一般是在测试或者调试的时候才会用到。
HostAliases:定义了 Pod 的 hosts 文件(比如 /etc/hosts)里的内容
在 Kubernetes 项目中,如果要设置 hosts 文件里的内容,一定要通过这种方法。否则,如果直接修改了 hosts 文件的话,在 Pod 被删除重建之后,kubelet 会自动覆盖掉被修改的内容。
init Containers和 Containers
这两个字段都属于 Pod 对容器的定义,内容也完全相同,只是 Init Containers 的生命周期,会先于所有的 Containers,并且严格按照定义的顺序执行。几个属性值得额外关注:
- 首先,是 ImagePullPolicy 字段。它定义了镜像拉取的策略。而它之所以是一个 Container 级别的属性,是因为容器镜像本来就是 Container 定义中的一部分。ImagePullPolicy 的值默认是 Always,即每次创建 Pod 都重新拉取一次镜像。另外,当容器的镜像是类似于 nginx 或者 nginx:latest 这样的名字时,ImagePullPolicy 也会被认为 Always。而如果它的值被定义为 Never 或者 IfNotPresent,则意味着 Pod 永远不会主动拉取这个镜像,或者只在宿主机上不存在这个镜像时才拉取。
- 其次,是 Lifecycle 字段。它定义的是 Container Lifecycle Hooks。顾名思义,Container Lifecycle Hooks 的作用,是在容器状态发生变化时触发一系列“钩子”。
Pod 对象在 Kubernetes 中的生命周期。
Pod 生命周期的变化,主要体现在 Pod API 对象的 Status 部分,这是它除了 Metadata 和 Spec 之外的第三个重要字段。
其中,pod.status.phase,就是 Pod 的当前状态,它有如下几种可能的情况:
- Pending。这个状态意味着,Pod 的 YAML 文件已经提交给了 Kubernetes,API 对象已经被创建并保存在 Etcd 当中。但是,这个 Pod 里有些容器因为某种原因而不能被顺利创建。比如,调度不成功。
- Running。这个状态下,Pod 已经调度成功,跟一个具体的节点绑定。它包含的容器都已经创建成功,并且至少有一个正在运行中。
- Succeeded。这个状态意味着,Pod 里的所有容器都正常运行完毕,并且已经退出了。这种情况在运行一次性任务时最为常见。
- Failed。这个状态下,Pod 里至少有一个容器以不正常的状态(非 0 的返回码)退出。这个状态的出现,意味着你得想办法 Debug 这个容器的应用,比如查看 Pod 的 Events 和日志。
- Unknown。这是一个异常状态,意味着 Pod 的状态不能持续地被 kubelet 汇报给 kube-apiserver,这很有可能是主从节点(Master 和 Kubelet)间的通信出现了问题。
更进一步地,Pod 对象的 Status 字段,还可以再细分出一组 Conditions。这些细分状态的值包括:PodScheduled、Ready、Initialized,以及 Unschedulable。它们主要用于描述造成当前 Status 的具体原因是什么。
比如,Pod 当前的 Status 是 Pending,对应的 Condition 是 Unschedulable,这就意味着它的调度出现了问题。
而其中,Ready 这个细分状态非常值得我们关注:它意味着 Pod 不仅已经正常启动(Running 状态),而且已经可以对外提供服务了。这两者之间(Running 和 Ready)是有区别的,你不妨仔细思考一下。
Pod 的这些状态信息,是我们判断应用运行情况的重要标准,尤其是 Pod 进入了非“Running”状态后,你一定要能迅速做出反应,根据它所代表的异常情况开始跟踪和定位,而不是去手忙脚乱地查阅文档。
对于 Pod 状态是 Ready,实际上不能提供服务的情况能想到几个例子:
- 程序本身有 bug,本来应该返回 200,但因为代码问题,返回的是500;
- 程序因为内存问题,已经僵死,但进程还在,但无响应;
- Dockerfile 写的不规范,应用程序不是主进程,那么主进程出了什么问题都无法发现;
- 程序出现死循环。
Projected Volume 投射数据卷
备注:Projected Volume 是 Kubernetes v1.11 之后的新特性
在 Kubernetes 中,有几种特殊的 Volume,它们存在的意义不是为了存放容器里的数据,也不是用来进行容器和宿主机之间的数据交换。这些特殊 Volume 的作用,是为容器提供预先定义好的数据。
所以,从容器的角度来看,这些 Volume 里的信息就是仿佛是被 Kubernetes“投射”(Project)进入容器当中的。这正是 Projected Volume 的含义。
Projected Volume的四种类型
到目前为止,Kubernetes 支持的 Projected Volume 一共有四种:
- Secret;
- ConfigMap;
- Downward API;
- ServiceAccountToken。
一. Secret
它的作用,是帮你把 Pod 想要访问的加密数据,存放到 Etcd 中。然后,你就可以通过在 Pod 的容器里挂载 Volume 的方式,访问到这些 Secret 里保存的信息了。
Secret 最典型的使用场景,莫过于存放数据库的 Credential 信息,比如下面这个例子:
apiVersion: v1
kind: Pod
metadata:
name: test-projected-volume
spec:
containers:
- name: test-secret-volume
image: busybox
args:
- sleep
- "86400"
volumeMounts:
- name: mysql-cred
mountPath: "/projected-volume"
readOnly: true
volumes:
- name: mysql-cred
projected:
sources:
- secret:
name: user
- secret:
name: pass
在这个 Pod 中,我定义了一个简单的容器。它声明挂载的 Volume,并不是常见的 emptyDir 或者 hostPath 类型,而是 projected 类型。而这个 Volume 的数据来源(sources),则是名为 user 和 pass 的 Secret 对象,分别对应的是数据库的用户名和密码。
这里用到的数据库的用户名、密码,正是以 Secret 对象的方式交给 Kubernetes 保存的。完成这个操作的指令,如下所示:
$ cat ./username.txt
admin
$ cat ./password.txt
c1oudc0w!
$ kubectl create secret generic user --from-file=./username.txt
$ kubectl create secret generic pass --from-file=./password.txt
其中,username.txt 和 password.txt 文件里,存放的就是用户名和密码;而 user 和 pass,则是我为 Secret 对象指定的名字。而我想要查看这些 Secret 对象的话,只要执行一条 kubectl get 命令就可以了:
$ kubectl get secrets
NAME TYPE DATA AGE
user Opaque 1 51s
pass Opaque 1 51s
当然,除了使用 kubectl create secret 指令外,我也可以直接通过编写 YAML 文件的方式来创建这个 Secret 对象,比如:
apiVersion: v1
kind: Secret
metadata:
name: mysecret
type: Opaque
data:
user: YWRtaW4=
pass: MWYyZDFlMmU2N2Rm
可以看到,通过编写 YAML 文件创建出来的 Secret 对象只有一个。但它的 data 字段,却以 Key-Value 的格式保存了两份 Secret 数据。其中,“user”就是第一份数据的 Key,“pass”是第二份数据的 Key。
需要注意的是,Secret 对象要求这些数据必须是经过 Base64 转码的,以免出现明文密码的安全隐患。这个转码操作也很简单,比如:
$ echo -n 'admin' | base64
YWRtaW4=
$ echo -n '1f2d1e2e67df' | base64
MWYyZDFlMmU2N2Rm
这里需要注意的是,像这样创建的 Secret 对象,它里面的内容仅仅是经过了转码,而并没有被加密。在真正的生产环境中,你需要在 Kubernetes 中开启 Secret 的加密插件,增强数据的安全性。
接下来,我们尝试一下创建这个 Pod:
$ kubectl create -f test-projected-volume.yaml
当 Pod 变成 Running 状态之后,我们再验证一下这些 Secret 对象是不是已经在容器里了:
$ kubectl exec -it test-projected-volume -- /bin/sh
$ ls /projected-volume/
user
pass
$ cat /projected-volume/user
root
$ cat /projected-volume/pass
1f2d1e2e67df
从返回结果中,我们可以看到,保存在 Etcd 里的用户名和密码信息,已经以文件的形式出现在了容器的 Volume 目录里。而这个文件的名字,就是 kubectl create secret 指定的 Key,或者说是 Secret 对象的 data 字段指定的 Key。
更重要的是,像这样通过挂载方式进入到容器里的 Secret,一旦其对应的 Etcd 里的数据被更新,这些 Volume 里的文件内容,同样也会被更新。其实,这是 kubelet 组件在定时维护这些 Volume。
需要注意的是,这个更新可能会有一定的延时。所以在编写应用程序时,在发起数据库连接的代码处写好重试和超时的逻辑,绝对是个好习惯。
二. ConfigMap
ConfigMap与 Secret 类似,它与 Secret 的区别在于,ConfigMap 保存的是不需要加密的、应用所需的配置信息。而 ConfigMap 的用法几乎与 Secret 完全相同:你可以使用 kubectl create configmap 从文件或者目录创建 ConfigMap,也可以直接编写 ConfigMap 对象的 YAML 文件。
比如,一个 Java 应用所需的配置文件(.properties 文件),就可以通过下面这样的方式保存在 ConfigMap 里:
# .properties文件的内容
$ cat example/ui.properties
color.good=purple
color.bad=yellow
allow.textmode=true
how.nice.to.look=fairlyNice
# 从.properties文件创建ConfigMap
$ kubectl create configmap ui-config --from-file=example/ui.properties
# 查看这个ConfigMap里保存的信息(data)
$ kubectl get configmaps ui-config -o yaml
apiVersion: v1
data:
ui.properties: |
color.good=purple
color.bad=yellow
allow.textmode=true
how.nice.to.look=fairlyNice
kind: ConfigMap
metadata:
name: ui-config
...
三. Downward API
它的作用是:让 Pod 里的容器能够直接获取到这个 Pod API 对象本身的信息。
apiVersion: v1
kind: Pod
metadata:
name: test-downwardapi-volume
labels:
zone: us-est-coast
cluster: test-cluster1
rack: rack-22
spec:
containers:
- name: client-container
image: k8s.gcr.io/busybox
command: ["sh", "-c"]
args:
- while true; do
if [[ -e /etc/podinfo/labels ]]; then
echo -en '\n\n'; cat /etc/podinfo/labels; fi;
sleep 5;
done;
volumeMounts:
- name: podinfo
mountPath: /etc/podinfo
readOnly: false
volumes:
- name: podinfo
projected:
sources:
- downwardAPI:
items:
- path: "labels"
fieldRef:
fieldPath: metadata.labels
在这个 Pod 的 YAML 文件中,我定义了一个简单的容器,声明了一个 projected 类型的 Volume。只不过这次 Volume 的数据来源,变成了 Downward API。而这个 Downward API Volume,则声明了要暴露 Pod 的 metadata.labels 信息给容器。
通过这样的声明方式,当前 Pod 的 Labels 字段的值,就会被 Kubernetes 自动挂载成为容器里的 /etc/podinfo/labels 文件。
而这个容器的启动命令,则是不断打印出 /etc/podinfo/labels 里的内容。所以,当我创建了这个 Pod 之后,就可以通过 kubectl logs 指令,查看到这些 Labels 字段被打印出来,如下所示:
$ kubectl create -f dapi-volume.yaml
$ kubectl logs test-downwardapi-volume
cluster="test-cluster1"
rack="rack-22"
zone="us-est-coast"
目前,Downward API 支持的字段已经非常丰富了,比如:
1. 使用fieldRef可以声明使用:
spec.nodeName - 宿主机名字
status.hostIP - 宿主机IP
metadata.name - Pod的名字
metadata.namespace - Pod的Namespace
status.podIP - Pod的IP
spec.serviceAccountName - Pod的Service Account的名字
metadata.uid - Pod的UID
metadata.labels['<KEY>'] - 指定<KEY>的Label值
metadata.annotations['<KEY>'] - 指定<KEY>的Annotation值
metadata.labels - Pod的所有Label
metadata.annotations - Pod的所有Annotation
2. 使用resourceFieldRef可以声明使用:
容器的CPU limit
容器的CPU request
容器的memory limit
容器的memory request
上面这个列表的内容,随着 Kubernetes 项目的发展肯定还会不断增加。所以这里列出来的信息仅供参考,你在使用 Downward API 时,还是要记得去查阅一下官方文档。
不过,需要注意的是,Downward API 能够获取到的信息,一定是 Pod 里的容器进程启动之前就能够确定下来的信息。而如果你想要获取 Pod 容器运行后才会出现的信息,比如,容器进程的 PID,那就肯定不能使用 Downward API 了,而应该考虑在 Pod 里定义一个 sidecar 容器。
其实,Secret、ConfigMap,以及 Downward API 这三种 Projected Volume 定义的信息,大多还可以通过环境变量的方式出现在容器里。但是,通过环境变量获取这些信息的方式,不具备自动更新的能力。所以,一般情况下,建议使用 Volume 文件的方式获取这些信息。
四.Service Account。
Service Account 对象的作用,就是 Kubernetes 系统内置的一种“服务账户”,它是 Kubernetes 进行权限分配的对象。比如,Service Account A,可以只被允许对 Kubernetes API 进行 GET 操作,而 Service Account B,则可以有 Kubernetes API 的所有操作的权限。
像这样的 Service Account 的授权信息和文件,实际上保存在它所绑定的一个特殊的 Secret 对象里的。这个特殊的 Secret 对象,就叫作 ServiceAccountToken。任何运行在 Kubernetes 集群上的应用,都必须使用这个 ServiceAccountToken 里保存的授权信息,也就是 Token,才可以合法地访问 API Server。
所以说,Kubernetes 项目的 Projected Volume 其实只有三种,因为第四种 ServiceAccountToken,只是一种特殊的 Secret 而已。
另外,为了方便使用,Kubernetes 已经为你提供了一个的默认“服务账户”(default Service Account)。并且,任何一个运行在 Kubernetes 里的 Pod,都可以直接使用这个默认的 Service Account,而无需显示地声明挂载它。
这是如何做到的呢?
当然还是靠 Projected Volume 机制。
如果你查看一下任意一个运行在 Kubernetes 集群里的 Pod,就会发现,每一个 Pod,都已经自动声明一个类型是 Secret、名为 default-token-xxxx 的 Volume,然后 自动挂载在每个容器的一个固定目录上。比如:
$ kubectl describe pod nginx-deployment-5c678cfb6d-lg9lw
Containers:
...
Mounts:
/var/run/secrets/kubernetes.io/serviceaccount from default-token-s8rbq (ro)
Volumes:
default-token-s8rbq:
Type: Secret (a volume populated by a Secret)
SecretName: default-token-s8rbq
Optional: false
这个 Secret 类型的 Volume,正是默认 Service Account 对应的 ServiceAccountToken。所以说,Kubernetes 其实在每个 Pod 创建的时候,自动在它的 spec.volumes 部分添加上了默认 ServiceAccountToken 的定义,然后自动给每个容器加上了对应的 volumeMounts 字段。这个过程对于用户来说是完全透明的。
这样,一旦 Pod 创建完成,容器里的应用就可以直接从这个默认 ServiceAccountToken 的挂载目录里访问到授权信息和文件。这个容器内的路径在 Kubernetes 里是固定的,即:/var/run/secrets/kubernetes.io/serviceaccount ,而这个 Secret 类型的 Volume 里面的内容如下所示:
$ ls /var/run/secrets/kubernetes.io/serviceaccount
ca.crt namespace token
所以,你的应用程序只要直接加载这些授权文件,就可以访问并操作 Kubernetes API 了。而且,如果你使用的是 Kubernetes 官方的 Client 包(k8s.io/client-go)的话,它还可以自动加载这个目录下的文件,你不需要做任何配置或者编码操作。
这种把 Kubernetes 客户端以容器的方式运行在集群里,然后使用 default Service Account 自动授权的方式,被称作“InClusterConfig”,也是最推荐的进行 Kubernetes API 编程的授权方式。
Pod 的另一个重要的配置:容器健康检查和恢复机制。
在 Kubernetes 中,你可以为 Pod 里的容器定义一个健康检查“探针”(Probe)。
这样,kubelet 就会根据这个 Probe 的返回值决定这个容器的状态,而不是直接以容器进行是否运行(来自 Docker 返回的信息)作为依据。
这种机制,是生产环境中保证应用健康存活的重要手段。
Kubernetes 文档中的例子。
apiVersion: v1
kind: Pod
metadata:
labels:
test: liveness
name: test-liveness-exec
spec:
containers:
- name: liveness
image: busybox
args:
- /bin/sh
- -c
- touch /tmp/healthy; sleep 30; rm -rf /tmp/healthy; sleep 600
livenessProbe:
exec:
command:
- cat
- /tmp/healthy
initialDelaySeconds: 5
periodSeconds: 5
在这个 Pod 中,我们定义了一个有趣的容器。它在启动之后做的第一件事,就是在 /tmp 目录下创建了一个 healthy 文件,以此作为自己已经正常运行的标志。而 30 s 过后,它会把这个文件删除掉。
与此同时,我们定义了一个这样的 livenessProbe(健康检查)。它的类型是 exec,这意味着,它会在容器启动后,在容器里面执行一句我们指定的命令,比如:“cat /tmp/healthy”。
这时,如果这个文件存在,这条命令的返回值就是 0,Pod 就会认为这个容器不仅已经启动,而且是健康的。这个健康检查,在容器启动 5 s 后开始执行(initialDelaySeconds: 5),每 5 s 执行一次(periodSeconds: 5)。
现在,让我们来具体实践一下这个过程。
首先,创建这个 Pod:
$ kubectl create -f test-liveness-exec.yaml
然后,查看这个 Pod 的状态:
$ kubectl get pod
NAME READY STATUS RESTARTS AGE
test-liveness-exec 1/1 Running 0 10s
可以看到,由于已经通过了健康检查,这个 Pod 就进入了 Running 状态。
而 30 s 之后,我们再查看一下 Pod 的 Events:
$ kubectl describe pod test-liveness-exec
你会发现,这个 Pod 在 Events 报告了一个异常:
FirstSeen LastSeen Count From SubobjectPath Type Reason Message
--------- -------- ----- ---- ------------- -------- ------ -------
2s 2s 1 {kubelet worker0} spec.containers{liveness} Warning Unhealthy Liveness probe failed: cat: can't open '/tmp/healthy': No such file or directory
显然,这个健康检查探查到 /tmp/healthy 已经不存在了,所以它报告容器是不健康的。那么接下来会发生什么呢?
我们不妨再次查看一下这个 Pod 的状态:
$ kubectl get pod test-liveness-exec
NAME READY STATUS RESTARTS AGE
liveness-exec 1/1 Running 1 1m
这时我们发现,Pod 并没有进入 Failed 状态,而是保持了 Running 状态。这是为什么呢?
其实,如果你注意到 RESTARTS 字段从 0 到 1 的变化,就明白原因了:这个异常的容器已经被 Kubernetes 重启了。在这个过程中,Pod 保持 Running 状态不变。
需要注意的是:Kubernetes 中并没有 Docker 的 Stop 语义。所以虽然是 Restart(重启),但实际却是重新创建了容器。
这个功能就是 Kubernetes 里的 Pod 恢复机制,也叫 restartPolicy。它是 Pod 的 Spec 部分的一个标准字段(pod.spec.restartPolicy),默认值是 Always,即:任何时候这个容器发生了异常,它一定会被重新创建。
但一定要强调的是,Pod 的恢复过程,永远都是发生在当前节点上,而不会跑到别的节点上去。事实上,一旦一个 Pod 与一个节点(Node)绑定,除非这个绑定发生了变化(pod.spec.node 字段被修改),否则它永远都不会离开这个节点。这也就意味着,如果这个宿主机宕机了,这个 Pod 也不会主动迁移到其他节点上去。
而如果你想让 Pod 出现在其他的可用节点上,就必须使用 Deployment 这样的“控制器”来管理 Pod,哪怕你只需要一个 Pod 副本。
而作为用户,你还可以通过设置 restartPolicy,改变 Pod 的恢复策略。除了 Always,它还有 OnFailure 和 Never 两种情况:
- Always:在任何情况下,只要容器不在运行状态,就自动重启容器;
- OnFailure: 只在容器 异常时才自动重启容器;
- Never: 从来不重启容器。
在实际使用时,我们需要根据应用运行的特性,合理设置这三种恢复策略。
现在,我们一起回到前面提到的 livenessProbe 上来。
除了在容器中执行命令外,livenessProbe 也可以定义为发起 HTTP 或者 TCP 请求的方式,定义格式如下:
...
livenessProbe:
httpGet:
path: /healthz
port: 8080
httpHeaders:
- name: X-Custom-Header
value: Awesome
initialDelaySeconds: 3
periodSeconds: 3
...
livenessProbe:
tcpSocket:
port: 8080
initialDelaySeconds: 15
periodSeconds: 20
所以,你的 Pod 其实可以暴露一个健康检查 URL(比如 /healthz),或者直接让健康检查去检测应用的监听端口。这两种配置方法,在 Web 服务类的应用中非常常用。
在 Kubernetes 的 Pod 中,还有一个叫 readinessProbe 的字段。虽然它的用法与 livenessProbe 类似,但作用却大不一样。readinessProbe 检查结果的成功与否,决定的这个 Pod 是不是能被通过 Service 的方式访问到,而并不影响 Pod 的生命周期。
以 Deployment 为例,简单描述它对控制器模型的实现?
- Deployment 控制器从 Etcd 中获取到所有携带了“app: nginx”标签的 Pod,然后统计它们的数量,这就是实际状态;
- Deployment 对象的 Replicas 字段的值就是期望状态;
- Deployment 控制器将两个状态做比较,然后根据比较结果,确定是创建 Pod,还是删除已有的 Pod.
一个 Kubernetes 对象的主要编排逻辑,实际上是在第三步的“对比”阶段完成的。
ownerReference
在所有 API 对象的 Metadata 里,都有一个字段叫作 ownerReference,用于保存当前这个 API 对象的拥有者(Owner)的信息。
对于一个 Deployment 所管理的 Pod,它的 ownerReference 是谁?
ReplicaSet
Kubernetes 使用的“控制器模式”,跟我们平常所说的“事件驱动”,有什么区别和联系吗?
这里“控制器模式”和“事件驱动”最关键的区别在于:
- 对于控制器来说,被监听对象的变化是一个持续的信号,比如变成 ADD 状态。只要这个状态没变化,那么此后无论任何时候控制器再去查询对象的状态,都应该是 ADD。
- 而对于事件驱动来说,它只会在 ADD 事件发生的时候发出一个事件。如果控制器错过了这个事件,那么它就有可能再也没办法知道 ADD 这个事件的发生了。
- 事件往往是一次性的,如果操作失败比较难处理,但是控制器是循环一直在尝试的,更符合kubernetes申明式API,最终达到与申明一致。
Deployment 控制器
Deployment 实现了 Kubernetes 项目中一个非常重要的功能:Pod 的“水平扩展 / 收缩”(horizontal scaling out/in)
Deployment 更新Pod,需要遵循一种叫作“滚动更新”(rolling update)的方式,来升级现有的容器。而这个能力的实现,依赖的是 Kubernetes 项目中的一个非常重要的概念(API 对象):ReplicaSet。
Deployment 控制器实际操纵的,是 ReplicaSet 对象,而不是 Pod 对象。
- ReplicaSet 负责通过“控制器模式”,保证系统中 Pod 的个数永远等于指定的个数(比如,3 个)。这也正是 Deployment 只允许容器的 restartPolicy=Always 的主要原因:只有在容器能保证自己始终是 Running 状态的前提下,ReplicaSet 调整 Pod 的个数才有意义。
- Deployment 同样通过“控制器模式”,来操作 ReplicaSet 的个数和属性,进而实现“水平扩展 / 收缩”和“滚动更新”这两个编排动作。
水平扩展 / 收缩
“水平扩展 / 收缩”非常容易实现,Deployment Controller 只需要修改它所控制的 ReplicaSet 的 Pod 副本个数就可以了。
比如,把这个值从 3 改成 4,那么 Deployment 所对应的 ReplicaSet,就会根据修改后的值自动创建一个新的 Pod。这就是“水平扩展”了;“水平收缩”则反之。
而用户想要执行这个操作的指令也非常简单,就是 kubectl scale
滚动更新
$ kubectl get deployments
NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE
nginx-deployment 3 0 0 0 1s
通过以上返回结果可以看到四个状态字段,它们的含义如下所示:
- DESIRED:用户期望的 Pod 副本个数(spec.replicas 的值);
- CURRENT:当前处于 Running 状态的 Pod 的个数;
- UP-TO-DATE:当前处于最新版本的 Pod 的个数,所谓最新版本指的是 Pod 的 Spec 部分与 Deployment 里 Pod 模板里定义的完全一致;
- AVAILABLE:当前已经可用的 Pod 的个数,即:既是 Running 状态,又是最新版本,并且已经处于 Ready(健康检查正确)状态的 Pod 的个数。
只有这个 AVAILABLE 字段,描述的才是用户所期望的最终状态。
kubectl rollout status指令可以实时查看 Deployment 对象的状态变化。
$ kubectl rollout status deployment/nginx-deployment
Waiting for rollout to finish: 2 out of 3 new replicas have been updated...
deployment.apps/nginx-deployment successfully rolled out
尝试查看一下这个 Deployment 所控制的 ReplicaSet:
$ kubectl get rs
NAME DESIRED CURRENT READY AGE
nginx-deployment-3167673210 3 3 3 20s
在用户提交了一个 Deployment 对象后,Deployment Controller 就会立即创建一个 Pod 副本个数为 3 的 ReplicaSet。这个 ReplicaSet 的名字,则是由 Deployment 的名字和一个随机字符串共同组成。
这个随机字符串叫作 pod-template-hash,在我们这个例子里就是:3167673210。ReplicaSet 会把这个随机字符串加在它所控制的所有 Pod 的标签里,从而保证这些 Pod 不会与集群里的其他 Pod 混淆。
而 ReplicaSet 的 DESIRED、CURRENT 和 READY 字段的含义,和 Deployment 中是一致的。所以,相比之下,Deployment 只是在 ReplicaSet 的基础上,添加了 UP-TO-DATE 这个跟版本有关的状态字段。
这个时候,如果我们修改了 Deployment 的 Pod 模板,“滚动更新”就会被自动触发。
可以通过查看 Deployment 的 Events,看到这个“滚动更新”的流程:
$ kubectl describe deployment nginx-deployment
...
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
...
Normal ScalingReplicaSet 24s deployment-controller Scaled up replica set nginx-deployment-1764197365 to 1
Normal ScalingReplicaSet 22s deployment-controller Scaled down replica set nginx-deployment-3167673210 to 2
Normal ScalingReplicaSet 22s deployment-controller Scaled up replica set nginx-deployment-1764197365 to 2
Normal ScalingReplicaSet 19s deployment-controller Scaled down replica set nginx-deployment-3167673210 to 1
Normal ScalingReplicaSet 19s deployment-controller Scaled up replica set nginx-deployment-1764197365 to 3
Normal ScalingReplicaSet 14s deployment-controller Scaled down replica set nginx-deployment-3167673210 to 0
可以看到,首先,当你修改了 Deployment 里的 Pod 定义之后,Deployment Controller 会使用这个修改后的 Pod 模板,创建一个新的 ReplicaSet(hash=1764197365),这个新的 ReplicaSet 的初始 Pod 副本数是:0。
然后,在 Age=24 s 的位置,Deployment Controller 开始将这个新的 ReplicaSet 所控制的 Pod 副本数从 0 个变成 1 个,即:“水平扩展”出一个副本。
紧接着,在 Age=22 s 的位置,Deployment Controller 又将旧的 ReplicaSet(hash=3167673210)所控制的旧 Pod 副本数减少一个,即:“水平收缩”成两个副本。
如此交替进行,新 ReplicaSet 管理的 Pod 副本数,从 0 个变成 1 个,再变成 2 个,最后变成 3 个。而旧的 ReplicaSet 管理的 Pod 副本数则从 3 个变成 2 个,再变成 1 个,最后变成 0 个。这样,就完成了这一组 Pod 的版本升级过程。
像这样,将一个集群中正在运行的多个 Pod 版本,交替地逐一升级的过程,就是“滚动更新”。
在这个“滚动更新”过程完成之后,你可以查看一下新、旧两个 ReplicaSet 的最终状态:
$ kubectl get rs
NAME DESIRED CURRENT READY AGE
nginx-deployment-1764197365 3 3 3 6s
nginx-deployment-3167673210 0 0 0 30s
其中,旧 ReplicaSet(hash=3167673210)已经被“水平收缩”成了 0 个副本。
Deployment 的控制器,实际上控制的是 ReplicaSet 的数目,以及每个 ReplicaSet 的属性。而一个应用的版本,对应的正是一个 ReplicaSet;这个版本应用的 Pod 数量,则由 ReplicaSet 通过它自己的控制器(ReplicaSet Controller)来保证。通过这样的多个 ReplicaSet 对象,Kubernetes 项目就实现了对多个“应用版本”的描述。
Deployment 对应用进行版本控制的具体原理:
首先,需要使用 kubectl rollout history 命令,查看每次 Deployment 变更对应的版本。
然后,我们就可以在 kubectl rollout undo 命令行最后,加上要回滚到的指定版本的版本号,就可以回滚到指定版本了。
Deployment 对象有一个字段,叫作 spec.revisionHistoryLimit,就是 Kubernetes 为 Deployment 保留的“历史版本”个数。所以,如果把它设置为 0,你就再也不能做回滚操作了。
Deployment 实际上是一个两层控制器。首先,它通过 ReplicaSet 的个数来描述应用的版本;然后,它再通过 ReplicaSet 的属性(比如 replicas 的值),来保证 Pod 的副本数量。
备注:Deployment 控制 ReplicaSet(版本),ReplicaSet 控制 Pod(副本数)。这个两层控制关系一定要牢记。
Kubernetes 项目对 Deployment 的设计,实际上是代替我们完成了对“应用”的抽象,使得我们可以使用这个 Deployment 对象来描述应用,使用 kubectl rollout 命令控制应用的版本。
StatefulSet 之拓扑状态
StatefulSet 的设计其实非常容易理解。它把真实世界里的应用状态,抽象为了两种情况:
- 拓扑状态。这种情况意味着,应用的多个实例之间不是完全对等的关系。这些应用实例,必须按照某些顺序启动,比如应用的主节点 A 要先于从节点 B 启动。而如果你把 A 和 B 两个 Pod 删除掉,它们再次被创建出来时也必须严格按照这个顺序才行。并且,新创建出来的 Pod,必须和原来 Pod 的网络标识一样,这样原先的访问者才能使用同样的方法,访问到这个新 Pod。
- 存储状态。这种情况意味着,应用的多个实例分别绑定了不同的存储数据。对于这些应用实例来说,Pod A 第一次读取到的数据,和隔了十分钟之后再次读取到的数据,应该是同一份,哪怕在此期间 Pod A 被重新创建过。这种情况最典型的例子,就是一个数据库应用的多个存储实例。
所以,StatefulSet 的核心功能,就是通过某种方式记录这些状态,然后在 Pod 被重新创建时,能够为新 Pod 恢复这些状态。
StatefulSet 如何使用Headless Service DNS 记录来维持 Pod 的拓扑状态?
Headless Service 不需要分配一个 VIP,而是可以直接以 DNS 记录的方式解析出被代理 Pod 的 IP 地址。
所谓的 Headless Service,其实仍是一个标准 Service 的 YAML 文件。只不过,它的 clusterIP 字段的值是:None,即:这个 Service,没有一个 VIP 作为“头”。这也就是 Headless 的含义。所以,这个 Service 被创建后并不会被分配一个 VIP,而是会以 DNS 记录的方式暴露出它所代理的 Pod。
而它所代理的 Pod,通过Label Selector 机制选择出来的,即:所有携带了 app=nginx 标签的 Pod,都会被这个 Service 代理起来。
StatefulSet 通过 YAML 文件指定 serviceName=nginx 字段来告诉 StatefulSet 控制器,在执行控制循环(Control Loop)的时候,请使用 nginx 这个 Headless Service 来保证 Pod 的“可解析身份”。
StatefulSet 这个控制器的主要作用之一,就是使用 Pod 模板创建 Pod 的时候,对它们进行编号,并且按照编号顺序逐一完成创建工作。而当 StatefulSet 的“控制循环”发现 Pod 的“实际状态”与“期望状态”不一致,需要新建或者删除 Pod 进行“调谐”的时候,它会严格按照这些 Pod 编号的顺序,逐一完成这些操作。
这样,Kubernetes 就成功地将 Pod 的拓扑状态(比如:哪个节点先启动,哪个节点后启动),按照 Pod 的“名字 + 编号”的方式固定了下来。
StatefulSet 对存储状态的管理机制 Persistent Volume Claim
Kubernetes 项目引入了一组叫作 Persistent Volume Claim(PVC)和 Persistent Volume(PV)的 API 对象,大大降低了用户声明和使用持久化 Volume 的门槛。
举个例子,有了 PVC 之后,一个开发人员想要使用一个 Volume,只需要简单的两步即可。
第一步:定义一个 PVC,声明想要的 Volume 的属性:
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: pv-claim
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 1Gi
可以看到,在这个 PVC 对象里,不需要任何关于 Volume 细节的字段,只有描述性的属性和定义。比如,storage: 1Gi,表示我想要的 Volume 大小至少是 1 GiB;accessModes: ReadWriteOnce,表示这个 Volume 的挂载方式是可读写,并且只能被挂载在一个节点上而非被多个节点共享。
第二步:在应用的 Pod 中,声明使用这个 PVC:
apiVersion: v1
kind: Pod
metadata:
name: pv-pod
spec:
containers:
- name: pv-container
image: nginx
ports:
- containerPort: 80
name: "http-server"
volumeMounts:
- mountPath: "/usr/share/nginx/html"
name: pv-storage
volumes:
- name: pv-storage
persistentVolumeClaim:
claimName: pv-claim
可以看到,在这个 Pod 的 Volumes 定义中,我们只需要声明它的类型是 persistentVolumeClaim,然后指定 PVC 的名字,而完全不必关心 Volume 本身的定义。
这时候,只要我们创建这个 PVC 对象,Kubernetes 就会自动为它绑定一个符合条件的 Volume。可是,这些符合条件的 Volume 又是从哪里来的呢?
答案是,它们来自于由运维人员维护的 PV(Persistent Volume)对象。接下来,我们一起看一个常见的 PV 对象的 YAML 文件:
kind: PersistentVolume
apiVersion: v1
metadata:
name: pv-volume
labels:
type: local
spec:
capacity:
storage: 10Gi
rbd:
monitors:
- '10.16.154.78:6789'
- '10.16.154.82:6789'
- '10.16.154.83:6789'
pool: kube
image: foo
fsType: ext4
readOnly: true
user: admin
keyring: /etc/ceph/keyring
imageformat: "2"
imagefeatures: "layering"
可以看到,这个 PV 对象的 spec.rbd 字段,正是我们前面介绍过的 Ceph RBD Volume 的详细定义。而且,它还声明了这个 PV 的容量是 10 GiB。这样,Kubernetes 就会为我们刚刚创建的 PVC 对象绑定这个 PV。
所以,Kubernetes 中 PVC 和 PV 的设计,实际上类似于“接口”和“实现”的思想。开发者只要知道并会使用“接口”,即:PVC;而运维人员则负责给“接口”绑定具体的实现,即:PV。
这种解耦,就避免了因为向开发者暴露过多的存储系统细节而带来的隐患。此外,这种职责的分离,往往也意味着出现事故时可以更容易定位问题和明确责任,从而避免“扯皮”现象的出现。
通过 StatefulSet YAML 定义额外添加一个 volumeClaimTemplates 字段。
...
volumeClaimTemplates:
- metadata:
name: www
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 1Gi
从名字就可以看出来,它跟 Deployment 里 Pod 模板(PodTemplate)的作用类似。也就是说,凡是被这个 StatefulSet 管理的 Pod,都会声明一个对应的 PVC;而这个 PVC 的定义,就来自于 volumeClaimTemplates 这个模板字段。更重要的是,这个 PVC 的名字,会被分配一个与这个 Pod 完全一致的编号
这个自动创建的 PVC,与 PV 绑定成功后,就会进入 Bound 状态,这就意味着这个 Pod 可以挂载并使用这个 PV 了。
当然,PVC 与 PV 的绑定得以实现的前提是,运维人员已经在系统里创建好了符合条件的 PV(比如,我们在前面用到的 pv-volume);或者,你的 Kubernetes 集群运行在公有云上,这样 Kubernetes 就会通过 Dynamic Provisioning 的方式,自动为你创建与 PVC 匹配的 PV。
StatefulSet 的工作原理
首先,StatefulSet 的控制器直接管理的是 Pod。
这是因为,StatefulSet 里的不同 Pod 实例,不再像 ReplicaSet 中那样都是完全一样的,而是有了细微区别的。比如,每个 Pod 的 hostname、名字等都是不同的、携带了编号的。而 StatefulSet 区分这些实例的方式,就是通过在 Pod 的名字里加上事先约定好的编号。
其次,Kubernetes 通过 Headless Service,为这些有编号的 Pod,在 DNS 服务器中生成带有同样编号的 DNS 记录。
只要 StatefulSet 能够保证这些 Pod 名字里的编号不变,那么 Service 里类似于 web-0.nginx.default.svc.cluster.local 这样的 DNS 记录也就不会变,而这条记录解析出来的 Pod 的 IP 地址,则会随着后端 Pod 的删除和再创建而自动更新。这当然是 Service 机制本身的能力,不需要 StatefulSet 操心。
最后,StatefulSet 还为每一个 Pod 分配并创建一个同样编号的 PVC。
这样,Kubernetes 就可以通过 Persistent Volume 机制为这个 PVC 绑定上对应的 PV,从而保证了每一个 Pod 都拥有一个独立的 Volume。
在这种情况下,即使 Pod 被删除,它所对应的 PVC 和 PV 依然会保留下来。所以当这个 Pod 被重新创建出来之后,Kubernetes 会为它找到同样编号的 PVC,挂载这个 PVC 对应的 Volume,从而获取到以前保存在 Volume 里的数据。
StatefulSet 的设计思想
StatefulSet 其实就是一种特殊的 Deployment,而其独特之处在于,它的每个 Pod 都被编号了。而且,这个编号会体现在 Pod 的名字和 hostname 等标识信息上,这不仅代表了 Pod 的创建顺序,也是 Pod 的重要网络标识(即:在整个集群里唯一的、可被的访问身份)
有了这个编号后,StatefulSet 就使用 Kubernetes 里的两个标准功能:Headless Service 和 PV/PVC,实现了对 Pod 的拓扑状态和存储状态的维护。
StatefulSet 的“滚动更新”
你只要修改 StatefulSet 的 Pod 模板,就会自动触发“滚动更新”:
$ kubectl patch statefulset mysql --type='json' -p='[{"op": "replace", "path": "/spec/template/spec/containers/0/image", "value":"mysql:5.7.23"}]'
statefulset.apps/mysql patched
在这里,我使用了 kubectl patch 命令。它的意思是,以“补丁”的方式(JSON 格式的)修改一个 API 对象的指定字段,也就是我在后面指定的“spec/template/spec/containers/0/image”。
这样,StatefulSet Controller 就会按照与 Pod 编号相反的顺序,从最后一个 Pod 开始,逐一更新这个 StatefulSet 管理的每个 Pod。而如果更新发生了错误,这次“滚动更新”就会停止。此外,StatefulSet 的“滚动更新”还允许我们进行更精细的控制,比如金丝雀发布(Canary Deploy)或者灰度发布,这意味着应用的多个实例中被指定的一部分不会被更新到最新的版本。
这个字段,正是 StatefulSet 的 spec.updateStrategy.rollingUpdate 的 partition 字段。
把 partition 字段修改为 2。
这样,就指定了当 Pod 模板发生变化的时候,比如 MySQL 镜像更新到 5.7.23,那么只有序号大于或者等于 2 的 Pod 会被更新到这个版本。并且,如果你删除或者重启了序号小于 2 的 Pod,等它再次启动后,也会保持原先的 5.7.2 版本,绝不会被升级到 5.7.23 版本。
DaemonSet
顾名思义,DaemonSet 的主要作用,是让你在 Kubernetes 集群里,运行一个 Daemon Pod。 所以,这个 Pod 有如下三个特征:
- 这个 Pod 运行在 Kubernetes 集群里的每一个节点(Node)上;
- 每个节点上只有一个这样的 Pod 实例;
- 当有新的节点加入 Kubernetes 集群后,该 Pod 会自动地在新节点上被创建出来;而当旧节点被删除后,它上面的 Pod 也相应地会被回收掉。
这个机制听起来很简单,但 Daemon Pod 的意义确实是非常重要的。我随便给你列举几个例子:
- 各种网络插件的 Agent 组件,都必须运行在每一个节点上,用来处理这个节点上的容器网络;
- 各种存储插件的 Agent 组件,也必须运行在每一个节点上,用来在这个节点上挂载远程存储目录,操作容器的 Volume 目录;
- 各种监控组件和日志组件,也必须运行在每一个节点上,负责这个节点上的监控信息和日志搜集。
更重要的是,跟其他编排对象不一样,DaemonSet 开始运行的时机,很多时候比整个 Kubernetes 集群出现的时机都要早。
DaemonSet 其实是一个非常简单的控制器。在它的控制循环中,只需要遍历所有节点,然后根据节点上是否有被管理 Pod 的情况,来决定是否要创建或者删除一个 Pod。
只不过,在创建每个 Pod 的时候,DaemonSet 会自动给这个 Pod 加上一个 nodeAffinity,从而保证这个 Pod 只会在指定节点上启动。同时,它还会自动给这个 Pod 加上一个 Toleration,从而忽略节点的 unschedulable“污点”。
DaemonSet 只管理 Pod 对象,然后通过 nodeAffinity 和 Toleration 这两个调度器的小功能,保证了每个节点上有且只有一个 Pod。
在 Kubernetes v1.11 之前,DaemonSet 所管理的 Pod 的调度过程,实际上都是由 DaemonSet Controller 自己而不是由调度器完成的。你能说出这其中有哪些原因吗?
这里的原因在于,默认调度器之前的功能不是很完善,比如,缺乏优先级和抢占机制。所以,它没办法保证 DaemonSet ,尤其是部署时候的系统级的、高优先级的 DaemonSet 一定会调度成功。这种情况下,就会影响到集群的部署了。
ControllerRevision 通用的版本管理对象
比如,你可以通过如下命令查看 fluentd-elasticsearch 对应的 ControllerRevision:
$ kubectl get controllerrevision -n kube-system -l name=fluentd-elasticsearch
NAME CONTROLLER REVISION AGE
fluentd-elasticsearch-64dc6799c9 daemonset.apps/fluentd-elasticsearch 2 1h
而如果你使用 kubectl describe 查看这个 ControllerRevision 对象:
$ kubectl describe controllerrevision fluentd-elasticsearch-64dc6799c9 -n kube-system
Name: fluentd-elasticsearch-64dc6799c9
Namespace: kube-system
Labels: controller-revision-hash=2087235575
name=fluentd-elasticsearch
Annotations: deprecated.daemonset.template.generation=2
kubernetes.io/change-cause=kubectl set image ds/fluentd-elasticsearch fluentd-elasticsearch=k8s.gcr.io/fluentd-elasticsearch:v2.2.0 --record=true --namespace=kube-system
API Version: apps/v1
Data:
Spec:
Template:
$ Patch: replace
Metadata:
Creation Timestamp: <nil>
Labels:
Name: fluentd-elasticsearch
Spec:
Containers:
Image: k8s.gcr.io/fluentd-elasticsearch:v2.2.0
Image Pull Policy: IfNotPresent
Name: fluentd-elasticsearch
...
Revision: 2
Events: <none>
就会看到,这个 ControllerRevision 对象,实际上是在 Data 字段保存了该版本对应的完整的 DaemonSet 的 API 对象。并且,在 Annotation 字段保存了创建这个对象所使用的 kubectl 命令。
接下来,我们可以尝试将这个 DaemonSet 回滚到 Revision=1 时的状态:
$ kubectl rollout undo daemonset fluentd-elasticsearch --to-revision=1 -n kube-system
daemonset.extensions/fluentd-elasticsearch rolled back
这个 kubectl rollout undo 操作,实际上相当于读取到了 Revision=1 的 ControllerRevision 对象保存的 Data 字段。而这个 Data 字段里保存的信息,就是 Revision=1 时这个 DaemonSet 的完整 API 对象。
所以,现在 DaemonSet Controller 就可以使用这个历史 API 对象,对现有的 DaemonSet 做一次 PATCH 操作(等价于执行一次 kubectl apply -f “旧的 DaemonSet 对象”),从而把这个 DaemonSet“更新”到一个旧版本。
这也是为什么,在执行完这次回滚完成后,你会发现,DaemonSet 的 Revision 并不会从 Revision=2 退回到 1,而是会增加成 Revision=3。这是因为,一个新的 ControllerRevision 被创建了出来。
Job 是 kubernetes v1.4 版本之后,才逐步设计出了一个用来描述离线业务的 API 对象
Job API 对象的定义非常简单,如下所示:
apiVersion: batch/v1
kind: Job
metadata:
name: pi
spec:
template:
spec:
containers:
- name: pi
image: resouer/ubuntu-bc
command: ["sh", "-c", "echo 'scale=10000; 4*a(1)' | bc -l "]
restartPolicy: Never
backoffLimit: 4
我们需要在 Pod 模板中定义 restartPolicy=Never 的原因:离线计算的 Pod 永远都不应该被重启,否则它们会再重新计算一遍。
事实上,restartPolicy 在 Job 对象里只允许被设置为 Never 和 OnFailure;而在 Deployment 对象里,restartPolicy 则只允许被设置为 Always。
如果你定义的 restartPolicy=OnFailure,那么离线作业失败后,Job Controller 就不会去尝试创建新的 Pod。但是,它会不断地尝试重启 Pod 里的容器。
Job 对象的 spec.backoffLimit 字段里定义了重试次数为 4(即,backoffLimit=4),而这个字段的默认值是 6。
需要注意的是,Job Controller 重新创建 Pod 的间隔是呈指数增加的,即下一次重新创建 Pod 的动作会分别发生在 10 s、20 s、40 s …后。
跟其他控制器不同的是,Job 对象并不要求你定义一个 spec.selector 来描述要控制哪些 Pod。
Job 对象在创建后,它的 Pod 模板,被自动加上了一个 controller-uid=< 一个随机字符串 > 这样的 Label。而这个 Job 对象本身,则被自动加上了这个 Label 对应的 Selector,从而 保证了 Job 与它所管理的 Pod 之间的匹配关系。
而 Job Controller 之所以要使用这种携带了 UID 的 Label,就是为了避免不同 Job 对象所管理的 Pod 发生重合。需要注意的是,这种自动生成的 Label 对用户来说并不友好,所以不太适合推广到 Deployment 等长作业编排对象上。
如前所述,当一个 Job 的 Pod 运行结束后,它会进入 Completed 状态。但是,如果这个 Pod 因为某种原因一直不肯结束呢?
在 Job 的 API 对象里,有一个 spec.activeDeadlineSeconds 字段可以设置最长运行时间,比如:
spec:
backoffLimit: 5
activeDeadlineSeconds: 100
一旦运行超过了 100 s,这个 Job 的所有 Pod 都会被终止。并且,你可以在 Pod 的状态里看到终止的原因是 reason: DeadlineExceeded。
Job Controller 对并行作业的控制方法。
在 Job 对象中,负责并行控制的参数有两个:
- spec.parallelism,它定义的是一个 Job 在任意时间最多可以启动多少个 Pod 同时运行;
- spec.completions,它定义的是 Job 至少要完成的 Pod 数目,即 Job 的最小完成数。
spec:
parallelism: 2
completions: 4
Job 其实也维护了两个状态字段,即 DESIRED 和 SUCCESSFUL
$ kubectl get job
NAME DESIRED SUCCESSFUL AGE
pi 4 0 3s
其中,DESIRED 的值,正是 completions 定义的最小完成数。
通过 Job 的 DESIRED 和 SUCCESSFUL 字段的关系,我们就可以很容易地理解Job Controller 的工作原理了。
- 首先,Job Controller 控制的对象,直接就是 Pod。
- 其次,Job Controller 在控制循环中进行的调谐(Reconcile)操作,是根据实际在 Running 状态 Pod 的数目、已经成功退出的 Pod 的数目,以及 parallelism、completions 参数的值共同计算出在这个周期里,应该创建或者删除的 Pod 数目,然后调用 Kubernetes API 来执行这个操作。
以创建 Pod 为例。在上面计算 Pi 值的这个例子中,当 Job 一开始创建出来时,实际处于 Running 状态的 Pod 数目 =0,已经成功退出的 Pod 数目 =0,而用户定义的 completions,也就是最终用户需要的 Pod 数目 =4
所以,在这个时刻,需要创建的 Pod 数目 = 最终需要的 Pod 数目 - 实际在 Running 状态 Pod 数目 - 已经成功退出的 Pod 数目 = 4 - 0 - 0= 4。也就是说,Job Controller 需要创建 4 个 Pod 来纠正这个不一致状态。
可是,我们又定义了这个 Job 的 parallelism=2。也就是说,我们规定了每次并发创建的 Pod 个数不能超过 2 个。所以,Job Controller 会对前面的计算结果做一个修正,修正后的期望创建的 Pod 数目应该是:2 个。
这时候,Job Controller 就会并发地向 kube-apiserver 发起两个创建 Pod 的请求。
类似地,如果在这次调谐周期里,Job Controller 发现实际在 Running 状态的 Pod 数目,比 parallelism 还大,那么它就会删除一些 Pod,使两者相等。
综上所述,Job Controller 实际上控制了,作业执行的并行度,以及总共需要完成的任务数这两个重要参数。而在实际使用时,你需要根据作业的特性,来决定并行度(parallelism)和任务数(completions)的合理取值。
CronJob 定时任务 API 对象
apiVersion: batch/v1beta1
kind: CronJob
metadata:
name: hello
spec:
schedule: "*/1 * * * *"
jobTemplate:
spec:
template:
spec:
containers:
- name: hello
image: busybox
args:
- /bin/sh
- -c
- date; echo Hello from the Kubernetes cluster
restartPolicy: OnFailure
在这个 YAML 文件中,最重要的关键词就是 jobTemplate。看到它,你一定恍然大悟,原来 CronJob 是一个 Job 对象的控制器(Controller)!
没错,CronJob 与 Job 的关系,正如同 Deployment 与 Pod 的关系一样。CronJob 是一个专门用来管理 Job 对象的控制器。只不过,它创建和删除 Job 的依据,是 schedule 字段定义的、一个标准的Unix Cron格式的表达式。
比如,"*/1 * * * *"。
这个 Cron 表达式里 */1 中的 * 表示从 0 开始,/ 表示“每”,1 表示偏移量。所以,它的意思就是:从 0 开始,每 1 个时间单位执行一次。
那么,时间单位又是什么呢?
Cron 表达式中的五个部分分别代表:分钟、小时、日、月、星期。
所以,上面这句 Cron 表达式的意思是:从当前开始,每分钟执行一次。
而这里要执行的内容,就是 jobTemplate 定义的 Job 了。
需要注意的是,由于定时任务的特殊性,很可能某个 Job 还没有执行完,另外一个新 Job 就产生了。这时候,你可以通过 spec.concurrencyPolicy 字段来定义具体的处理策略。比如:
- concurrencyPolicy=Allow,这也是默认情况,这意味着这些 Job 可以同时存在;
- concurrencyPolicy=Forbid,这意味着不会创建新的 Pod,该创建周期被跳过;
- concurrencyPolicy=Replace,这意味着新产生的 Job 会替换旧的、没有执行完的 Job。
而如果某一次 Job 创建失败,这次创建就会被标记为“miss”。当在指定的时间窗口内,miss 的数目达到 100 时,那么 CronJob 会停止再创建这个 Job。
这个时间窗口,可以由 spec.startingDeadlineSeconds 字段指定。比如 startingDeadlineSeconds=200,意味着在过去 200 s 里,如果 miss 的数目达到了 100 次,那么这个 Job 就不会被创建执行了。
根据 Job 控制器的工作原理,如果你定义的 parallelism 比 completions 还大的话,比如:
parallelism: 4
completions: 2
那么,这个 Job 最开始创建的时候,会同时启动几个 Pod 呢?原因是什么?
需要创建的 Pod 数目 = 最终需要的 Pod 数目 - 实际在 Running 状态 Pod 数目 - 已经成功退出的 Pod 数目 = 2 - 0 - 0= 2。而parallelism数量为4,2小于4,所以应该会创建2个。
声明式API与Kubernetes编程范式
基于 YAML 文件的操作方式,先 kubectl create,再 replace 的操作,我们称为命令式配置文件操作
到底什么才是“声明式 API”呢?
答案是,kubectl apply 命令。
它跟 kubectl replace 命令有什么本质区别吗?
实际上,你可以简单地理解为,kubectl replace 的执行过程,是使用新的 YAML 文件中的 API 对象,替换原有的 API 对象;而 kubectl apply,则是执行了一个对原有 API 对象的 PATCH 操作。
类似地,kubectl set image 和 kubectl edit 也是对已有 API 对象的修改。
更进一步地,这意味着 kube-apiserver 在响应命令式请求(比如,kubectl replace)的时候,一次只能处理一个写请求,否则会有产生冲突的可能。而对于声明式请求(比如,kubectl apply),一次能处理多个写操作,并且具备 Merge 能力。
以 Istio 项目为例,来讲解一下声明式 API 在实际使用时的重要意义。
在 2017 年 5 月,Google、IBM 和 Lyft 公司,共同宣布了 Istio 开源项目的诞生。很快,这个项目就在技术圈儿里,掀起了一阵名叫“微服务”的热潮,把 Service Mesh 这个新的编排概念推到了风口浪尖。而 Istio 项目,实际上就是一个基于 Kubernetes 项目的微服务治理框架。它的架构非常清晰,如下所示:
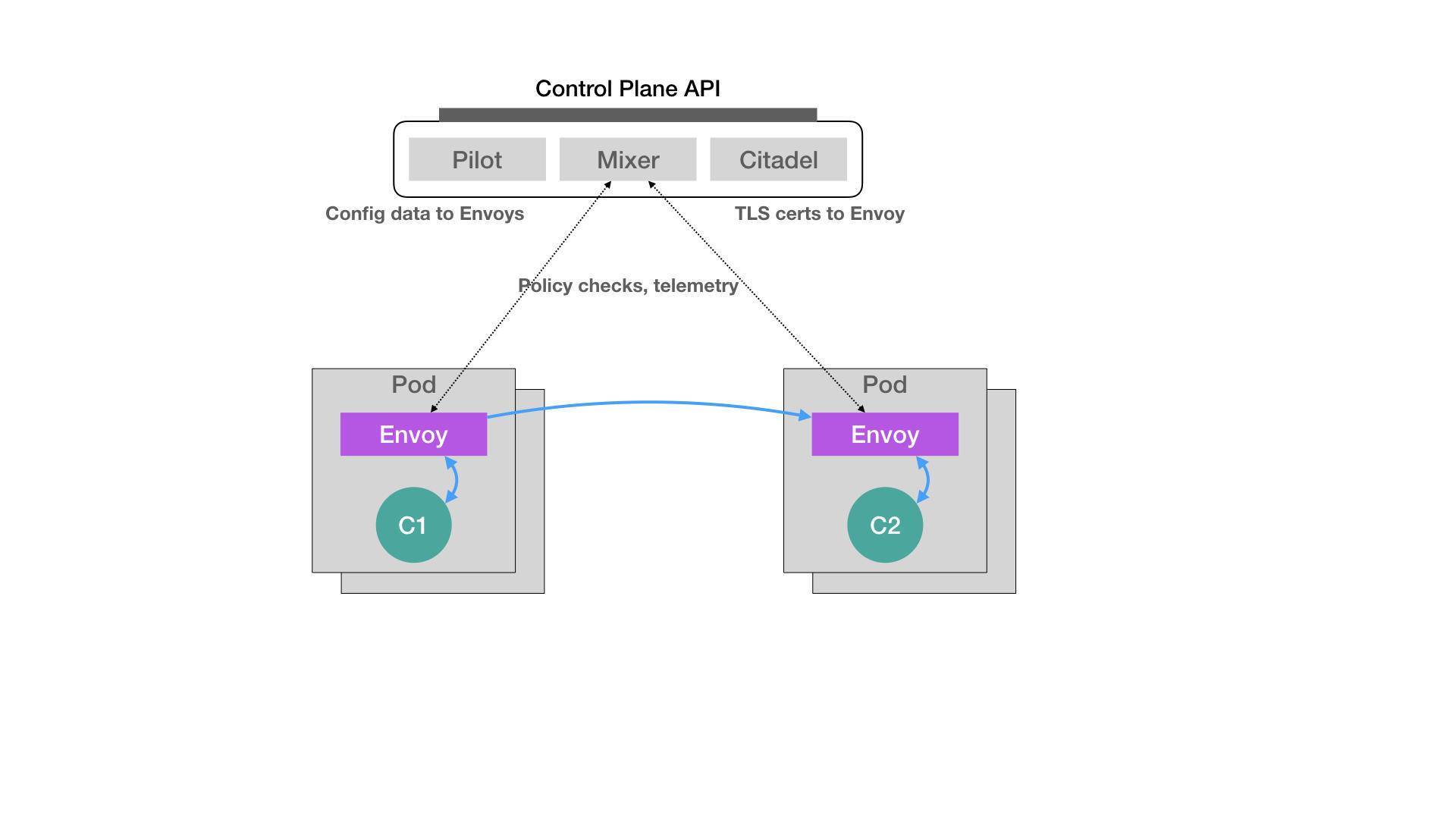
在上面这个架构图中,我们不难看到 Istio 项目架构的核心所在。Istio 最根本的组件,是运行在每一个应用 Pod 里的 Envoy 容器。
这个 Envoy 项目是 Lyft 公司推出的一个高性能 C++ 网络代理,也是 Lyft 公司对 Istio 项目的唯一贡献。
而 Istio 项目,则把这个代理服务以 sidecar 容器的方式,运行在了每一个被治理的应用 Pod 中。我们知道,Pod 里的所有容器都共享同一个 Network Namespace。所以,Envoy 容器就能够通过配置 Pod 里的 iptables 规则,把整个 Pod 的进出流量接管下来。
这时候,Istio 的控制层(Control Plane)里的 Pilot 组件,就能够通过调用每个 Envoy 容器的 API,对这个 Envoy 代理进行配置,从而实现微服务治理。
我们一起来看一个例子。
假设这个 Istio 架构图左边的 Pod 是已经在运行的应用,而右边的 Pod 则是我们刚刚上线的应用的新版本。这时候,Pilot 通过调节这两 Pod 里的 Envoy 容器的配置,从而将 90% 的流量分配给旧版本的应用,将 10% 的流量分配给新版本应用,并且,还可以在后续的过程中随时调整。这样,一个典型的“灰度发布”的场景就完成了。比如,Istio 可以调节这个流量从 90%-10%,改到 80%-20%,再到 50%-50%,最后到 0%-100%,就完成了这个灰度发布的过程。
更重要的是,在整个微服务治理的过程中,无论是对 Envoy 容器的部署,还是像上面这样对 Envoy 代理的配置,用户和应用都是完全“无感”的。
这时候,你可能会有所疑惑:Istio 项目明明需要在每个 Pod 里安装一个 Envoy 容器,又怎么能做到“无感”的呢?
实际上,Istio 项目使用的,是 Kubernetes 中的一个非常重要的功能,叫作 Dynamic Admission Control。
在 Kubernetes 项目中,当一个 Pod 或者任何一个 API 对象被提交给 APIServer 之后,总有一些“初始化”性质的工作需要在它们被 Kubernetes 项目正式处理之前进行。比如,自动为所有 Pod 加上某些标签(Labels)。
而这个“初始化”操作的实现,借助的是一个叫作 Admission 的功能。它其实是 Kubernetes 项目里一组被称为 Admission Controller 的代码,可以选择性地被编译进 APIServer 中,在 API 对象创建之后会被立刻调用到。
但这就意味着,如果你现在想要添加一些自己的规则到 Admission Controller,就会比较困难。因为,这要求重新编译并重启 APIServer。显然,这种使用方法对 Istio 来说,影响太大了。
所以,Kubernetes 项目为我们额外提供了一种“热插拔”式的 Admission 机制,它就是 Dynamic Admission Control,也叫作:Initializer。
现在,我给你举个例子。比如,我有如下所示的一个应用 Pod:
apiVersion: v1
kind: Pod
metadata:
name: myapp-pod
labels:
app: myapp
spec:
containers:
- name: myapp-container
image: busybox
command: ['sh', '-c', 'echo Hello Kubernetes! && sleep 3600']
可以看到,这个 Pod 里面只有一个用户容器,叫作:myapp-container。
接下来,Istio 项目要做的,就是在这个 Pod YAML 被提交给 Kubernetes 之后,在它对应的 API 对象里自动加上 Envoy 容器的配置,使这个对象变成如下所示的样子:
apiVersion: v1
kind: Pod
metadata:
name: myapp-pod
labels:
app: myapp
spec:
containers:
- name: myapp-container
image: busybox
command: ['sh', '-c', 'echo Hello Kubernetes! && sleep 3600']
- name: envoy
image: lyft/envoy:845747b88f102c0fd262ab234308e9e22f693a1
command: ["/usr/local/bin/envoy"]
...
可以看到,被 Istio 处理后的这个 Pod 里,除了用户自己定义的 myapp-container 容器之外,多出了一个叫作 envoy 的容器,它就是 Istio 要使用的 Envoy 代理。
那么,Istio 又是如何在用户完全不知情的前提下完成这个操作的呢?
Istio 要做的,就是编写一个用来为 Pod“自动注入”Envoy 容器的 Initializer。
首先,Istio 会将这个 Envoy 容器本身的定义,以 ConfigMap 的方式保存在 Kubernetes 当中。这个 ConfigMap(名叫:envoy-initializer)的定义如下所示:
apiVersion: v1
kind: ConfigMap
metadata:
name: envoy-initializer
data:
config: |
containers:
- name: envoy
image: lyft/envoy:845747db88f102c0fd262ab234308e9e22f693a1
command: ["/usr/local/bin/envoy"]
args:
- "--concurrency 4"
- "--config-path /etc/envoy/envoy.json"
- "--mode serve"
ports:
- containerPort: 80
protocol: TCP
resources:
limits:
cpu: "1000m"
memory: "512Mi"
requests:
cpu: "100m"
memory: "64Mi"
volumeMounts:
- name: envoy-conf
mountPath: /etc/envoy
volumes:
- name: envoy-conf
configMap:
name: envoy
相信你已经注意到了,这个 ConfigMap 的 data 部分,正是一个 Pod 对象的一部分定义。其中,我们可以看到 Envoy 容器对应的 containers 字段,以及一个用来声明 Envoy 配置文件的 volumes 字段。
不难想到,Initializer 要做的工作,就是把这部分 Envoy 相关的字段,自动添加到用户提交的 Pod 的 API 对象里。可是,用户提交的 Pod 里本来就有 containers 字段和 volumes 字段,所以 Kubernetes 在处理这样的更新请求时,就必须使用类似于 git merge 这样的操作,才能将这两部分内容合并在一起。
所以说,在 Initializer 更新用户的 Pod 对象的时候,必须使用 PATCH API 来完成。而这种 PATCH API,正是声明式 API 最主要的能力。
接下来,Istio 将一个编写好的 Initializer,作为一个 Pod 部署在 Kubernetes 中。这个 Pod 的定义非常简单,如下所示:
apiVersion: v1
kind: Pod
metadata:
labels:
app: envoy-initializer
name: envoy-initializer
spec:
containers:
- name: envoy-initializer
image: envoy-initializer:0.0.1
imagePullPolicy: Always
我们可以看到,这个 envoy-initializer 使用的 envoy-initializer:0.0.1 镜像,就是一个事先编写好的“自定义控制器”(Custom Controller)。
先为你解释一下这个控制器的主要功能。
一个 Kubernetes 的控制器,实际上就是一个“死循环”:它不断地获取“实际状态”,然后与“期望状态”作对比,并以此为依据决定下一步的操作。
而 Initializer 的控制器,不断获取到的“实际状态”,就是用户新创建的 Pod。而它的“期望状态”,则是:这个 Pod 里被添加了 Envoy 容器的定义。
我还是用一段 Go 语言风格的伪代码,来为你描述这个控制逻辑,如下所示:
for {
// 获取新创建的Pod
pod := client.GetLatestPod()
// Diff一下,检查是否已经初始化过
if !isInitialized(pod) {
// 没有?那就来初始化一下
doSomething(pod)
}
}
- 如果这个 Pod 里面已经添加过 Envoy 容器,那么就“放过”这个 Pod,进入下一个检查周期。
- 而如果还没有添加过 Envoy 容器的话,它就要进行 Initialize 操作了,即:修改该 Pod 的 API 对象(doSomething 函数)。
这时候,你应该立刻能想到,Istio 要往这个 Pod 里合并的字段,正是我们之前保存在 envoy-initializer 这个 ConfigMap 里的数据(即:它的 data 字段的值)。
所以,在 Initializer 控制器的工作逻辑里,它首先会从 APIServer 中拿到这个 ConfigMap:
func doSomething(pod) {
cm := client.Get(ConfigMap, "envoy-initializer")
}
然后,把这个 ConfigMap 里存储的 containers 和 volumes 字段,直接添加进一个空的 Pod 对象里:
func doSomething(pod) {
cm := client.Get(ConfigMap, "envoy-initializer")
newPod := Pod{}
newPod.Spec.Containers = cm.Containers
newPod.Spec.Volumes = cm.Volumes
}
现在,关键来了。
Kubernetes 的 API 库,为我们提供了一个方法,使得我们可以直接使用新旧两个 Pod 对象,生成一个 TwoWayMergePatch:
func doSomething(pod) {
cm := client.Get(ConfigMap, "envoy-initializer")
newPod := Pod{}
newPod.Spec.Containers = cm.Containers
newPod.Spec.Volumes = cm.Volumes
// 生成patch数据
patchBytes := strategicpatch.CreateTwoWayMergePatch(pod, newPod)
// 发起PATCH请求,修改这个pod对象
client.Patch(pod.Name, patchBytes)
}
有了这个 TwoWayMergePatch 之后,Initializer 的代码就可以使用这个 patch 的数据,调用 Kubernetes 的 Client,发起一个 PATCH 请求。
这样,一个用户提交的 Pod 对象里,就会被自动加上 Envoy 容器相关的字段。
当然,Kubernetes 还允许你通过配置,来指定要对什么样的资源进行这个 Initialize 操作,比如下面这个例子:
apiVersion: admissionregistration.k8s.io/v1alpha1
kind: InitializerConfiguration
metadata:
name: envoy-config
initializers:
// 这个名字必须至少包括两个 "."
- name: envoy.initializer.kubernetes.io
rules:
- apiGroups:
- "" // 前面说过, ""就是core API Group的意思
apiVersions:
- v1
resources:
- pods
这个配置,就意味着 Kubernetes 要对所有的 Pod 进行这个 Initialize 操作,并且,我们指定了负责这个操作的 Initializer,名叫:envoy-initializer。
而一旦这个 InitializerConfiguration 被创建,Kubernetes 就会把这个 Initializer 的名字,加在所有新创建的 Pod 的 Metadata 上,格式如下所示:
apiVersion: v1
kind: Pod
metadata:
initializers:
pending:
- name: envoy.initializer.kubernetes.io
name: myapp-pod
labels:
app: myapp
...
可以看到,每一个新创建的 Pod,都会自动携带了 metadata.initializers.pending 的 Metadata 信息。
这个 Metadata,正是接下来 Initializer 的控制器判断这个 Pod 有没有执行过自己所负责的初始化操作的重要依据(也就是前面伪代码中 isInitialized() 方法的含义)。
这也就意味着,当你在 Initializer 里完成了要做的操作后,一定要记得将这个 metadata.initializers.pending 标志清除掉。这一点,你在编写 Initializer 代码的时候一定要非常注意。
此外,除了上面的配置方法,你还可以在具体的 Pod 的 Annotation 里添加一个如下所示的字段,从而声明要使用某个 Initializer:
apiVersion: v1
kind: Pod
metadata
annotations:
"initializer.kubernetes.io/envoy": "true"
...
在这个 Pod 里,我们添加了一个 Annotation,写明: initializer.kubernetes.io/envoy=true。这样,就会使用到我们前面所定义的 envoy-initializer 了。
以上,就是关于 Initializer 最基本的工作原理和使用方法了。相信你此时已经明白,Istio 项目的核心,就是由无数个运行在应用 Pod 中的 Envoy 容器组成的服务代理网格。这也正是 Service Mesh 的含义。
而这个机制得以实现的原理,正是借助了 Kubernetes 能够对 API 对象进行在线更新的能力,这也正是 Kubernetes“声明式 API”的独特之处:
- 首先,所谓“声明式”,指的就是我只需要提交一个定义好的 API 对象来“声明”,我所期望的状态是什么样子。
- 其次,“声明式 API”允许有多个 API 写端,以 PATCH 的方式对 API 对象进行修改,而无需关心本地原始 YAML 文件的内容。
- 最后,也是最重要的,有了上述两个能力,Kubernetes 项目才可以基于对 API 对象的增、删、改、查,在完全无需外界干预的情况下,完成对“实际状态”和“期望状态”的调谐(Reconcile)过程。
所以说,声明式 API,才是 Kubernetes 项目编排能力“赖以生存”的核心所在。
此外,不难看到,无论是对 sidecar 容器的巧妙设计,还是对 Initializer 的合理利用,Istio 项目的设计与实现,其实都依托于 Kubernetes 的声明式 API 和它所提供的各种编排能力。可以说,Istio 是在 Kubernetes 项目使用上的一位“集大成者”。
要知道,一个 Istio 项目部署完成后,会在 Kubernetes 里创建大约 43 个 API 对象。
而在使用 Initializer 的流程中,最核心的步骤,莫过于 Initializer“自定义控制器”的编写过程。它遵循的,正是标准的“Kubernetes 编程范式”,即:
如何使用控制器模式,同 Kubernetes 里 API 对象的“增、删、改、查”进行协作,进而完成用户业务逻辑的编写过程。
Kubernetes 声明式 API 的工作原理,以及添加自定义的 API 对象。
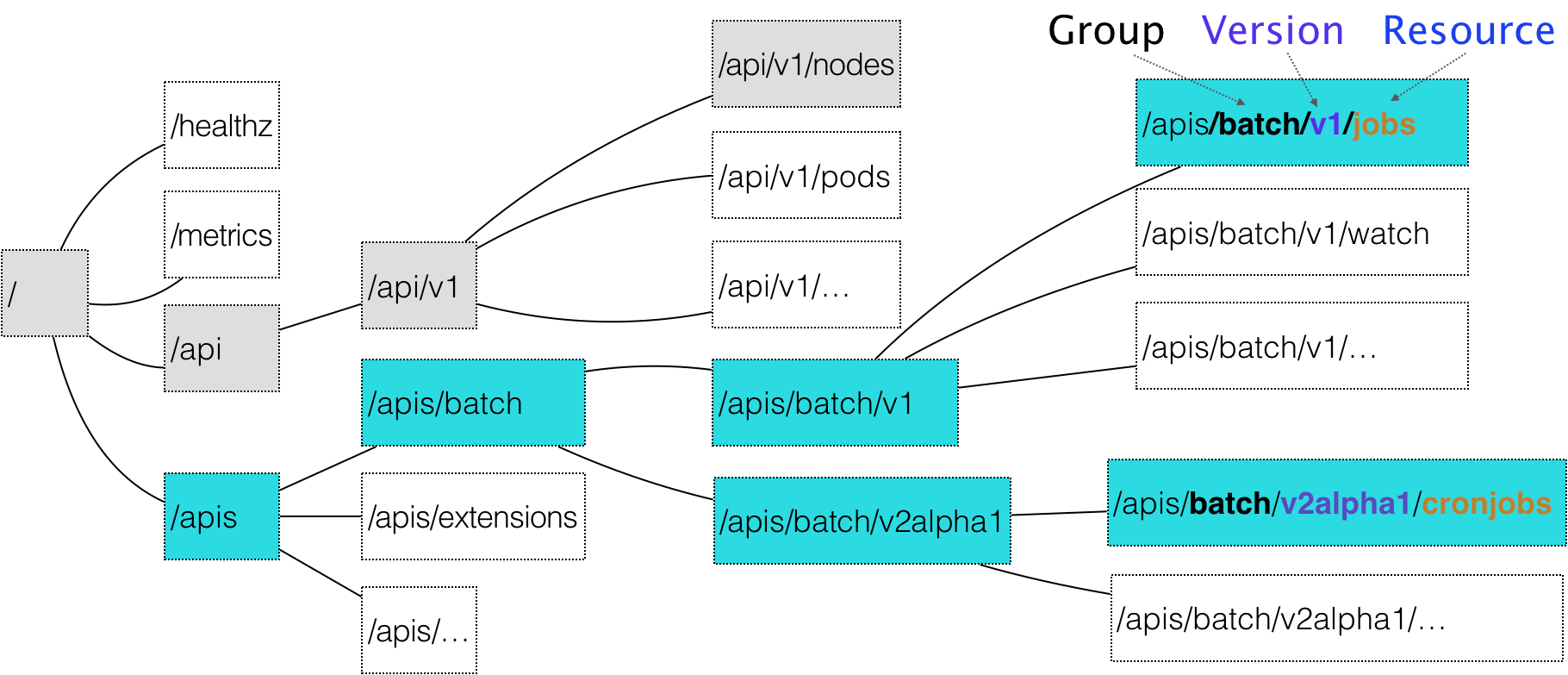
在 Kubernetes 项目中,一个 API 对象在 Etcd 里的完整资源路径,是由:Group(API 组)、Version(API 版本)和 Resource(API 资源类型)三个部分组成的。
通过这样的结构,整个 Kubernetes 里的所有 API 对象,实际上就可以用如下的树形结构表示出来:
在这幅图中,你可以很清楚地看到 Kubernetes 里 API 对象的组织方式,其实是层层递进的。
比如,现在我要声明要创建一个 CronJob 对象,那么我的 YAML 文件的开始部分会这么写:
apiVersion: batch/v2alpha1
kind: CronJob
...
在这个 YAML 文件中,“CronJob”就是这个 API 对象的资源类型(Resource),“batch”就是它的组(Group),v2alpha1 就是它的版本(Version)。
当我们提交了这个 YAML 文件之后,Kubernetes 就会把这个 YAML 文件里描述的内容,转换成 Kubernetes 里的一个 CronJob 对象。
那么,Kubernetes 是如何对 Resource、Group 和 Version 进行解析,从而在 Kubernetes 项目里找到 CronJob 对象的定义呢?
首先,Kubernetes 会匹配 API 对象的组。
需要明确的是,对于 Kubernetes 里的核心 API 对象,比如:Pod、Node 等,是不需要 Group 的(即:它们 Group 是“”)。所以,对于这些 API 对象来说,Kubernetes 会直接在 /api 这个层级进行下一步的匹配过程。
而对于 CronJob 等非核心 API 对象来说,Kubernetes 就必须在 /apis 这个层级里查找它对应的 Group,进而根据“batch”这个 Group 的名字,找到 /apis/batch。
不难发现,这些 API Group 的分类是以对象功能为依据的,比如 Job 和 CronJob 就都属于“batch” (离线业务)这个 Group。
然后,Kubernetes 会进一步匹配到 API 对象的版本号。
对于 CronJob 这个 API 对象来说,Kubernetes 在 batch 这个 Group 下,匹配到的版本号就是 v2alpha1。
在 Kubernetes 中,同一种 API 对象可以有多个版本,这正是 Kubernetes 进行 API 版本化管理的重要手段。这样,比如在 CronJob 的开发过程中,对于会影响到用户的变更就可以通过升级新版本来处理,从而保证了向后兼容。
最后,Kubernetes 会匹配 API 对象的资源类型。
在前面匹配到正确的版本之后,Kubernetes 就知道,我要创建的原来是一个 /apis/batch/v2alpha1 下的 CronJob 对象。
这时候,APIServer 就可以继续创建这个 CronJob 对象了。为了方便理解,我为你总结了一个如下所示流程图来阐述这个创建过程:
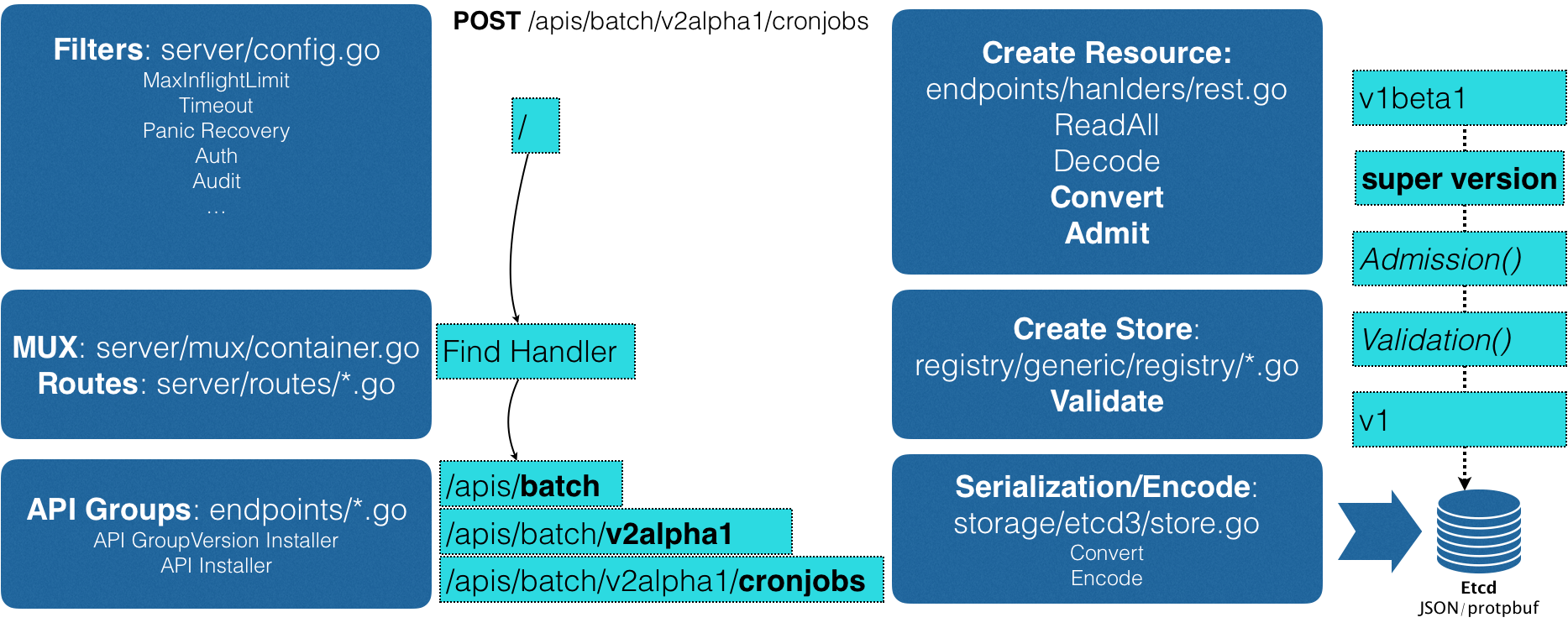
首先,当我们发起了创建 CronJob 的 POST 请求之后,我们编写的 YAML 的信息就被提交给了 APIServer。
而 APIServer 的第一个功能,就是过滤这个请求,并完成一些前置性的工作,比如授权、超时处理、审计等。
然后,请求会进入 MUX 和 Routes 流程。如果你编写过 Web Server 的话就会知道,MUX 和 Routes 是 APIServer 完成 URL 和 Handler 绑定的场所。而 APIServer 的 Handler 要做的事情,就是按照我刚刚介绍的匹配过程,找到对应的 CronJob 类型定义。
接着,APIServer 最重要的职责就来了:根据这个 CronJob 类型定义,使用用户提交的 YAML 文件里的字段,创建一个 CronJob 对象。
而在这个过程中,APIServer 会进行一个 Convert 工作,即:把用户提交的 YAML 文件,转换成一个叫作 Super Version 的对象,它正是该 API 资源类型所有版本的字段全集。这样用户提交的不同版本的 YAML 文件,就都可以用这个 Super Version 对象来进行处理了。
接下来,APIServer 会先后进行 Admission() 和 Validation() 操作。Admission Controller 和 Initializer,就都属于 Admission 的内容。
而 Validation,则负责验证这个对象里的各个字段是否合法。这个被验证过的 API 对象,都保存在了 APIServer 里一个叫作 Registry 的数据结构中。也就是说,只要一个 API 对象的定义能在 Registry 里查到,它就是一个有效的 Kubernetes API 对象。
最后,APIServer 会把验证过的 API 对象转换成用户最初提交的版本,进行序列化操作,并调用 Etcd 的 API 把它保存起来。
由于同时要兼顾性能、API 完备性、版本化、向后兼容等很多工程化指标,所以 Kubernetes 团队在 APIServer 项目里大量使用了 Go 语言的代码生成功能,来自动化诸如 Convert、DeepCopy 等与 API 资源相关的操作。
在 Kubernetes v1.7 之后,一个全新的 API 插件机制:CRD。
CRD 的全称是 Custom Resource Definition。 顾名思义,它指的就是,允许用户在 Kubernetes 中添加一个跟 Pod、Node 类似的、新的 API 资源类型,即:自定义 API 资源。
举个例子,我现在要为 Kubernetes 添加一个名叫 Network 的 API 资源类型。
它的作用是,一旦用户创建一个 Network 对象,那么 Kubernetes 就应该使用这个对象定义的网络参数,调用真实的网络插件,比如 Neutron 项目,为用户创建一个真正的“网络”。这样,将来用户创建的 Pod,就可以声明使用这个“网络”了。
这个 Network 对象的 YAML 文件,名叫 example-network.yaml,它的内容如下所示:
apiVersion: samplecrd.k8s.io/v1
kind: Network
metadata:
name: example-network
spec:
cidr: "192.168.0.0/16"
gateway: "192.168.0.1"
可以看到,我想要描述“网络”的 API 资源类型是 Network;API 组是samplecrd.k8s.io;API 版本是 v1。
那么,Kubernetes 又该如何知道这个 API(samplecrd.k8s.io/v1/network)的存在呢?
其实,上面的这个 YAML 文件,就是一个具体的“自定义 API 资源”实例,也叫 CR(Custom Resource)。而为了能够让 Kubernetes 认识这个 CR,你就需要让 Kubernetes 明白这个 CR 的宏观定义是什么,也就是 CRD(Custom Resource Definition)。
这就好比,你想让计算机认识各种兔子的照片,就得先让计算机明白,兔子的普遍定义是什么。比如,兔子“是哺乳动物”“有长耳朵,三瓣嘴”。
所以,接下来,我就先需编写一个 CRD 的 YAML 文件,它的名字叫作 network.yaml,内容如下所示:
apiVersion: apiextensions.k8s.io/v1beta1
kind: CustomResourceDefinition
metadata:
name: networks.samplecrd.k8s.io
spec:
group: samplecrd.k8s.io
version: v1
names:
kind: Network
plural: networks
scope: Namespaced
可以看到,在这个 CRD 中,我指定了“group: samplecrd.k8s.io”“version: v1”这样的 API 信息,也指定了这个 CR 的资源类型叫作 Network,复数(plural)是 networks。
然后,我还声明了它的 scope 是 Namespaced,即:我们定义的这个 Network 是一个属于 Namespace 的对象,类似于 Pod。
这就是一个 Network API 资源类型的 API 部分的宏观定义了。这就等同于告诉了计算机:“兔子是哺乳动物”。所以这时候,Kubernetes 就能够认识和处理所有声明了 API 类型是“samplecrd.k8s.io/v1/network”的 YAML 文件了。
接下来,我还需要让 Kubernetes“认识”这种 YAML 文件里描述的“网络”部分,比如“cidr”(网段),“gateway”(网关)这些字段的含义。这就相当于我要告诉计算机:“兔子有长耳朵和三瓣嘴”。
这时候呢,需要稍微做些代码工作了。
首先,我要在 GOPATH 下,创建一个结构如下的项目:
$ tree $GOPATH/src/github.com/<your-name>/k8s-controller-custom-resource
.
├── controller.go
├── crd
│ └── network.yaml
├── example
│ └── example-network.yaml
├── main.go
└── pkg
└── apis
└── samplecrd
├── register.go
└── v1
├── doc.go
├── register.go
└── types.go
其中,pkg/apis/samplecrd 就是 API 组的名字,v1 是版本,而 v1 下面的 types.go 文件里,则定义了 Network 对象的完整描述。
然后,我在 pkg/apis/samplecrd 目录下创建了一个 register.go 文件,用来放置后面要用到的全局变量。这个文件的内容如下所示:
package samplecrd
const (
GroupName = "samplecrd.k8s.io"
Version = "v1"
)
接着,我需要在 pkg/apis/samplecrd 目录下添加一个 doc.go 文件(Golang 的文档源文件)。这个文件里的内容如下所示:
// +k8s:deepcopy-gen=package
// +groupName=samplecrd.k8s.io
package v1
在这个文件中,你会看到 +[=value]格式的注释,这就是 Kubernetes 进行代码生成要用的 Annotation 风格的注释。
其中,+k8s:deepcopy-gen=package 意思是,请为整个 v1 包里的所有类型定义自动生成 DeepCopy 方法;而+groupName=samplecrd.k8s.io,则定义了这个包对应的 API 组的名字。
可以看到,这些定义在 doc.go 文件的注释,起到的是全局的代码生成控制的作用,所以也被称为 Global Tags。
接下来,我需要添加 types.go 文件。顾名思义,它的作用就是定义一个 Network 类型到底有哪些字段(比如,spec 字段里的内容)。这个文件的主要内容如下所示:
package v1
...
// +genclient
// +genclient:noStatus
// +k8s:deepcopy-gen:interfaces=k8s.io/apimachinery/pkg/runtime.Object
// Network describes a Network resource
type Network struct {
// TypeMeta is the metadata for the resource, like kind and apiversion
metav1.TypeMeta `json:",inline"`
// ObjectMeta contains the metadata for the particular object, including
// things like...
// - name
// - namespace
// - self link
// - labels
// - ... etc ...
metav1.ObjectMeta `json:"metadata,omitempty"`
Spec networkspec `json:"spec"`
}
// networkspec is the spec for a Network resource
type networkspec struct {
Cidr string `json:"cidr"`
Gateway string `json:"gateway"`
}
// +k8s:deepcopy-gen:interfaces=k8s.io/apimachinery/pkg/runtime.Object
// NetworkList is a list of Network resources
type NetworkList struct {
metav1.TypeMeta `json:",inline"`
metav1.ListMeta `json:"metadata"`
Items []Network `json:"items"`
}
在上面这部分代码里,你可以看到 Network 类型定义方法跟标准的 Kubernetes 对象一样,都包括了 TypeMeta(API 元数据)和 ObjectMeta(对象元数据)字段。
而其中的 Spec 字段,就是需要我们自己定义的部分。所以,在 networkspec 里,我定义了 Cidr 和 Gateway 两个字段。其中,每个字段最后面的部分比如json:"cidr",指的就是这个字段被转换成 JSON 格式之后的名字,也就是 YAML 文件里的字段名字。
此外,除了定义 Network 类型,你还需要定义一个 NetworkList 类型,用来描述一组 Network 对象应该包括哪些字段。之所以需要这样一个类型,是因为在 Kubernetes 中,获取所有 X 对象的 List() 方法,返回值都是List 类型,而不是 X 类型的数组。这是不一样的。
同样地,在 Network 和 NetworkList 类型上,也有代码生成注释。
其中,+genclient 的意思是:请为下面这个 API 资源类型生成对应的 Client 代码(这个 Client,我马上会讲到)。而 +genclient:noStatus 的意思是:这个 API 资源类型定义里,没有 Status 字段。否则,生成的 Client 就会自动带上 UpdateStatus 方法。
如果你的类型定义包括了 Status 字段的话,就不需要这句 +genclient:noStatus 注释了。比如下面这个例子:
// +genclient
// Network is a specification for a Network resource
type Network struct {
metav1.TypeMeta `json:",inline"`
metav1.ObjectMeta `json:"metadata,omitempty"`
Spec NetworkSpec `json:"spec"`
Status NetworkStatus `json:"status"`
}
需要注意的是,+genclient 只需要写在 Network 类型上,而不用写在 NetworkList 上。因为 NetworkList 只是一个返回值类型,Network 才是“主类型”。
而由于我在 Global Tags 里已经定义了为所有类型生成 DeepCopy 方法,所以这里就不需要再显式地加上 +k8s:deepcopy-gen=true 了。当然,这也就意味着你可以用 +k8s:deepcopy-gen=false 来阻止为某些类型生成 DeepCopy。
你可能已经注意到,在这两个类型上面还有一句+k8s:deepcopy-gen:interfaces=k8s.io/apimachinery/pkg/runtime.Object的注释。它的意思是,请在生成 DeepCopy 的时候,实现 Kubernetes 提供的 runtime.Object 接口。否则,在某些版本的 Kubernetes 里,你的这个类型定义会出现编译错误。这是一个固定的操作,记住即可。
不过,你或许会有这样的顾虑:这些代码生成注释这么灵活,我该怎么掌握呢?
其实,上面我所讲述的内容,已经足以应对 99% 的场景了。
最后,我需要再编写的一个 pkg/apis/samplecrd/v1/register.go 文件。
在前面对 APIServer 工作原理的讲解中,我已经提到,“registry”的作用就是注册一个类型(Type)给 APIServer。
其中,Network 资源类型在服务器端的注册的工作,APIServer 会自动帮我们完成。但与之对应的,我们还需要让客户端也能“知道”Network 资源类型的定义。这就需要我们在项目里添加一个 register.go 文件。它最主要的功能,就是定义了如下所示的 addKnownTypes() 方法:
package v1
...
// addKnownTypes adds our types to the API scheme by registering
// Network and NetworkList
func addKnownTypes(scheme *runtime.Scheme) error {
scheme.AddKnownTypes(
SchemeGroupVersion,
&Network{},
&NetworkList{},
)
// register the type in the scheme
metav1.AddToGroupVersion(scheme, SchemeGroupVersion)
return nil
}
有了这个方法,Kubernetes 就能够在后面生成客户端的时候,“知道”Network 以及 NetworkList 类型的定义了。
像上面这种 register.go 文件里的内容其实是非常固定的,你以后可以直接使用我提供的这部分代码做模板,然后把其中的资源类型、GroupName 和 Version 替换成你自己的定义即可。
这样,Network 对象的定义工作就全部完成了。可以看到,它其实定义了两部分内容:
- 第一部分是,自定义资源类型的 API 描述,包括:组(Group)、版本(Version)、资源类型(Resource)等。这相当于告诉了计算机:兔子是哺乳动物。
- 第二部分是,自定义资源类型的对象描述,包括:Spec、Status 等。这相当于告诉了计算机:兔子有长耳朵和三瓣嘴。
接下来,就要使用 Kubernetes 提供的代码生成工具,为上面定义的 Network 资源类型自动生成 clientset、informer 和 lister。
- 其中,clientset 就是操作 Network 对象所需要使用的客户端
- informer 是一个带有本地缓存和索引机制的、可以注册 EventHandler 的 client.
- lister 获取对应的对象
这个代码生成工具名叫k8s.io/code-generator,使用方法如下所示:
# 代码生成的工作目录,也就是我们的项目路径
$ ROOT_PACKAGE="github.com/resouer/k8s-controller-custom-resource"
# API Group
$ CUSTOM_RESOURCE_NAME="samplecrd"
# API Version
$ CUSTOM_RESOURCE_VERSION="v1"
# 安装k8s.io/code-generator
$ go get -u k8s.io/code-generator/...
$ cd $GOPATH/src/k8s.io/code-generator
# 执行代码自动生成,其中pkg/client是生成目标目录,pkg/apis是类型定义目录
$ ./generate-groups.sh all "$ROOT_PACKAGE/pkg/client" "$ROOT_PACKAGE/pkg/apis" "$CUSTOM_RESOURCE_NAME:$CUSTOM_RESOURCE_VERSION"
代码生成工作完成之后,再查看一下这个项目的目录结构:
$ tree
.
├── controller.go
├── crd
│ └── network.yaml
├── example
│ └── example-network.yaml
├── main.go
└── pkg
├── apis
│ └── samplecrd
│ ├── constants.go
│ └── v1
│ ├── doc.go
│ ├── register.go
│ ├── types.go
│ └── zz_generated.deepcopy.go
└── client
├── clientset
├── informers
└── listers
其中,pkg/apis/samplecrd/v1 下面的 zz_generated.deepcopy.go 文件,就是自动生成的 DeepCopy 代码文件。
而整个 client 目录,以及下面的三个包(clientset、informers、 listers),都是 Kubernetes 为 Network 类型生成的客户端库,这些库会在后面编写自定义控制器的时候用到。
可以看到,到目前为止的这些工作,其实并不要求你写多少代码,主要考验的是“复制、粘贴、替换”这样的“基本功”。
而有了这些内容,现在你就可以在 Kubernetes 集群里创建一个 Network 类型的 API 对象了。
首先,使用 network.yaml 文件,在 Kubernetes 中创建 Network 对象的 CRD(Custom Resource Definition):
$ kubectl apply -f crd/network.yaml
customresourcedefinition.apiextensions.k8s.io/networks.samplecrd.k8s.io created
这个操作,就告诉了 Kubernetes,我现在要添加一个自定义的 API 对象。而这个对象的 API 信息,正是 network.yaml 里定义的内容。我们可以通过 kubectl get 命令,查看这个 CRD:
$ kubectl get crd
NAME CREATED AT
networks.samplecrd.k8s.io 2018-09-15T10:57:12Z
然后,我们就可以创建一个 Network 对象了,这里用到的是 example-network.yaml:
$ kubectl apply -f example/example-network.yaml
network.samplecrd.k8s.io/example-network created
通过这个操作,你就在 Kubernetes 集群里创建了一个 Network 对象。它的 API 资源路径是samplecrd.k8s.io/v1/networks。
这时候,你就可以通过 kubectl get 命令,查看到新创建的 Network 对象:
$ kubectl get network
NAME AGE
example-network 8s
你还可以通过 kubectl describe 命令,看到这个 Network 对象的细节:
$ kubectl describe network example-network
Name: example-network
Namespace: default
Labels: <none>
...API Version: samplecrd.k8s.io/v1
Kind: Network
Metadata:
...
Generation: 1
Resource Version: 468239
...
Spec:
Cidr: 192.168.0.0/16
Gateway: 192.168.0.1
当然 ,你也可以编写更多的 YAML 文件来创建更多的 Network 对象,这和创建 Pod、Deployment 的操作,没有任何区别。
基于声明式 API 的业务功能实现,往往需要通过控制器模式来“监视”API 对象的变化(比如,创建或者删除 Network),然后以此来决定实际要执行的具体工作。
总得来说,编写自定义控制器代码的过程包括:编写 main 函数、编写自定义控制器的定义,以及编写控制器里的业务逻辑三个部分。
首先,来编写这 * 个自定义控制器的 main 函数。
main 函数的主要工作就是,定义并初始化一个自定义控制器(Custom Controller),然后启动它。这部分代码的主要内容如下所示:
func main() {
...
cfg, err := clientcmd.BuildConfigFromFlags(masterURL, kubeconfig)
...
kubeClient, err := kubernetes.NewForConfig(cfg)
...
networkClient, err := clientset.NewForConfig(cfg)
...
networkInformerFactory := informers.NewSharedInformerFactory(networkClient, ...)
controller := NewController(kubeClient, networkClient,
networkInformerFactory.Samplecrd().V1().Networks())
go networkInformerFactory.Start(stopCh)
if err = controller.Run(2, stopCh); err != nil {
glog.Fatalf("Error running controller: %s", err.Error())
}
}
可以看到,这个 main 函数主要通过三步完成了初始化并启动一个自定义控制器的工作。
- 第一步:main 函数根据我提供的 Master 配置(APIServer 的地址端口和 kubeconfig 的路径),创建一个 Kubernetes 的 client(kubeClient)和 Network 对象的 client(networkClient)。
但是,如果我没有提供 Master 配置呢?
这时,main 函数会直接使用一种名叫 InClusterConfig 的方式来创建这个 client。这个方式,会假设你的自定义控制器是以 Pod 的方式运行在 Kubernetes 集群里的。
Kubernetes 里所有的 Pod 都会以 Volume 的方式自动挂载 Kubernetes 的默认 ServiceAccount。所以,这个控制器就会直接使用默认 ServiceAccount 数据卷里的授权信息,来访问 APIServer。
- 第二步:main 函数为 Network 对象创建一个叫作 InformerFactory(即:networkInformerFactory)的工厂,并使用它生成一个 Network 对象的 Informer,传递给控制器。
- 第三步:main 函数启动上述的 Informer,然后执行 controller.Run,启动自定义控制器。
至此,main 函数就结束了.
看到这,你可能会感到非常困惑:编写自定义控制器的过程难道就这么简单吗?这个 Informer 又是个什么东西呢?
接下来,就详细解释一下这个自定义控制器的工作原理。
在 Kubernetes 项目中,一个自定义控制器的工作原理,可以用下面这样一幅流程图来表示(在后面的叙述中,我会用“示意图”来指代它):
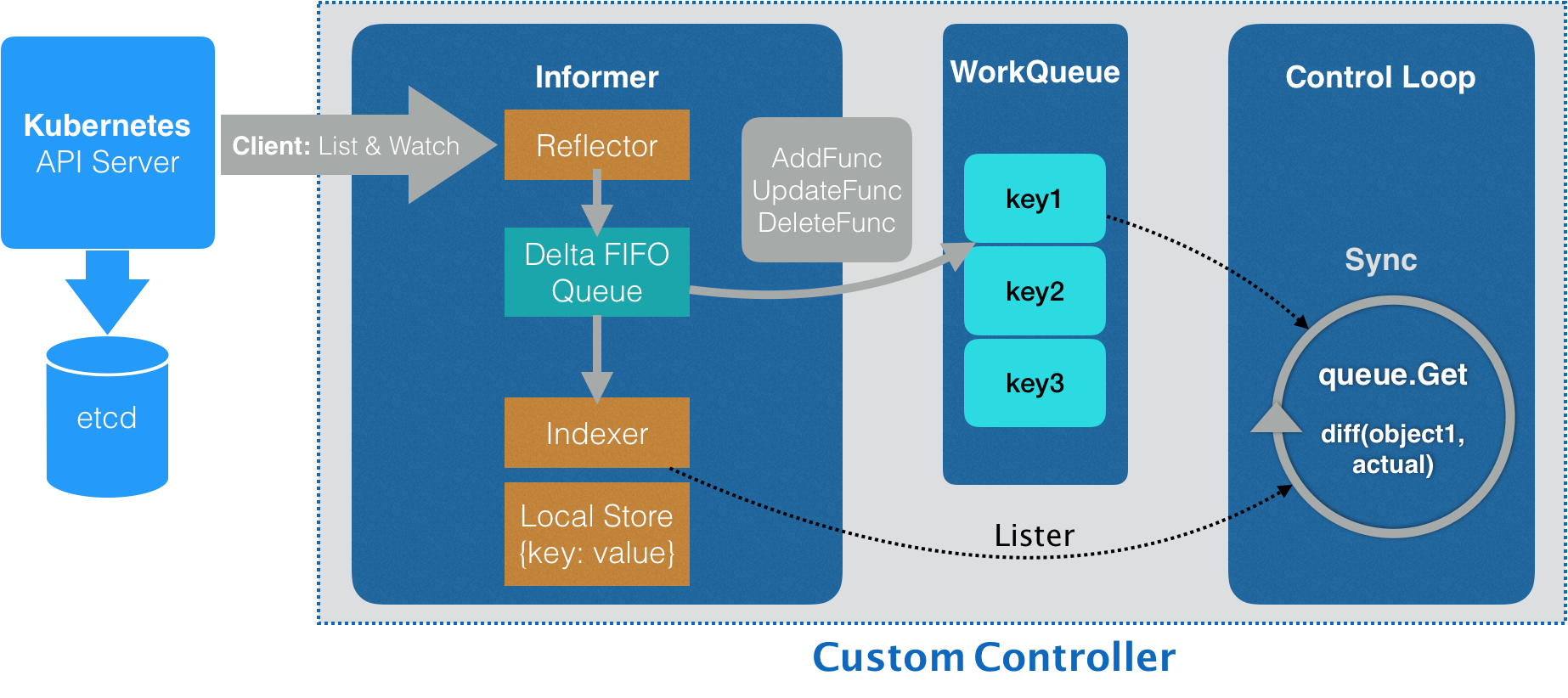
图 1 自定义控制器的工作流程示意图
我们先从这幅示意图的最左边看起。
这个控制器要做的第一件事,是从 Kubernetes 的 APIServer 里获取它所关心的对象,也就是我定义的 Network 对象。
这个操作,依靠的是一个叫作 Informer(可以翻译为:通知器)的代码库完成的。Informer 与 API 对象是一一对应的,所以我传递给自定义控制器的,正是一个 Network 对象的 Informer(Network Informer)。
不知你是否已经注意到,我在创建这个 Informer 工厂的时候,需要给它传递一个 networkClient。
事实上,Network Informer 正是使用这个 networkClient,跟 APIServer 建立了连接。不过,真正负责维护这个连接的,则是 Informer 所使用的 Reflector 包。
更具体地说,Reflector 使用的是一种叫作 ListAndWatch 的方法,来“获取”并“监听”这些 Network 对象实例的变化。
在 ListAndWatch 机制下,一旦 APIServer 端有新的 Network 实例被创建、删除或者更新,Reflector 都会收到“事件通知”。这时,该事件及它对应的 API 对象这个组合,就被称为增量(Delta),它会被放进一个 Delta FIFO Queue(即:增量先进先出队列) 中。
而另一方面,Informe 会不断地从这个 Delta FIFO Queue 里读取(Pop)增量。每拿到一个增量,Informer 就会判断这个增量里的事件类型,然后创建或者更新本地对象的缓存。这个缓存,在 Kubernetes 里一般被叫作 Store。
比如,如果事件类型是 Added(添加对象),那么 Informer 就会通过一个叫作 Indexer 的库把这个增量里的 API 对象保存在本地缓存中,并为它创建索引。相反地,如果增量的事件类型是 Deleted(删除对象),那么 Informer 就会从本地缓存中删除这个对象。
这个同步本地缓存的工作,是 Informer 的第一个职责,也是它最重要的职责。
而 Informer 的第二个职责,则是根据这些事件的类型,触发事先注册好的 ResourceEventHandler。这些 Handler,需要在创建控制器的时候注册给它对应的 Informer。
接下来,我们就来编写这个控制器的定义,它的主要内容如下所示:
func NewController(
kubeclientset kubernetes.Interface,
networkclientset clientset.Interface,
networkInformer informers.NetworkInformer) *Controller {
...
controller := &Controller{
kubeclientset: kubeclientset,
networkclientset: networkclientset,
networksLister: networkInformer.Lister(),
networksSynced: networkInformer.Informer().HasSynced,
workqueue: workqueue.NewNamedRateLimitingQueue(..., "Networks"),
...
}
networkInformer.Informer().AddEventHandler(cache.ResourceEventHandlerFuncs{
AddFunc: controller.enqueueNetwork,
UpdateFunc: func(old, new interface{}) {
oldNetwork := old.(*samplecrdv1.Network)
newNetwork := new.(*samplecrdv1.Network)
if oldNetwork.ResourceVersion newNetwork.ResourceVersion {
return
}
controller.enqueueNetwork(new)
},
DeleteFunc: controller.enqueueNetworkForDelete,
return controller
}
我前面在 main 函数里创建了两个 client(kubeclientset 和 networkclientset),然后在这段代码里,使用这两个 client 和前面创建的 Informer,初始化了自定义控制器。
值得注意的是,在这个自定义控制器里,我还设置了一个工作队列(work queue),它正是处于示意图中间位置的 WorkQueue。这个工作队列的作用是,负责同步 Informer 和控制循环之间的数据。
实际上,Kubernetes 项目为我们提供了很多个工作队列的实现,你可以根据需要选择合适的库直接使用。
然后,我为 networkInformer 注册了三个 Handler(AddFunc、UpdateFunc 和 DeleteFunc),分别对应 API 对象的“添加”“更新”和“删除”事件。而具体的处理操作,都是将该事件对应的 API 对象加入到工作队列中。
需要注意的是,实际入队的并不是 API 对象本身,而是它们的 Key,即:该 API 对象的/。
而我们后面即将编写的控制循环,则会不断地从这个工作队列里拿到这些 Key,然后开始执行真正的控制逻辑。
综合上面的讲述,你现在应该就能明白,所谓 Informer,其实就是一个带有本地缓存和索引机制的、可以注册 EventHandler 的 client。 它是自定义控制器跟 APIServer 进行数据同步的重要组件。
更具体地说,Informer 通过一种叫作 ListAndWatch 的方法,把 APIServer 中的 API 对象缓存在了本地,并负责更新和维护这个缓存。
其中,ListAndWatch 方法的含义是:首先,通过 APIServer 的 LIST API“获取”所有最新版本的 API 对象;然后,再通过 WATCH API 来“监听”所有这些 API 对象的变化。
而通过监听到的事件变化,Informer 就可以实时地更新本地缓存,并且调用这些事件对应的 EventHandler 了。
此外,在这个过程中,每经过 resyncPeriod 指定的时间,Informer 维护的本地缓存,都会使用最近一次 LIST 返回的结果强制更新一次,从而保证缓存的有效性。在 Kubernetes 中,这个缓存强制更新的操作就叫作:resync。
需要注意的是,这个定时 resync 操作,也会触发 Informer 注册的“更新”事件。但此时,这个“更新”事件对应的 Network 对象实际上并没有发生变化,即:新、旧两个 Network 对象的 ResourceVersion 是一样的。在这种情况下,Informer 就不需要对这个更新事件再做进一步的处理了。
这也是为什么我在上面的 UpdateFunc 方法里,先判断了一下新、旧两个 Network 对象的版本(ResourceVersion)是否发生了变化,然后才开始进行的入队操作。
以上,就是 Kubernetes 中的 Informer 库的工作原理了。
接下来,我们就来到了示意图中最后面的控制循环(Control Loop)部分,也正是我在 main 函数最后调用 controller.Run() 启动的“控制循环”。它的主要内容如下所示:
func (c *Controller) Run(threadiness int, stopCh <-chan struct{}) error {
...
if ok := cache.WaitForCacheSync(stopCh, c.networksSynced); !ok {
return fmt.Errorf("failed to wait for caches to sync")
}
...
for i := 0; i < threadiness; i++ {
go wait.Until(c.runWorker, time.Second, stopCh)
}
...
return nil
}
可以看到,启动控制循环的逻辑非常简单:
- 首先,等待 Informer 完成一次本地缓存的数据同步操作;
- 然后,直接通过 goroutine 启动一个(或者并发启动多个)“无限循环”的任务。
而这个“无限循环”任务的每一个循环周期,执行的正是我们真正关心的业务逻辑。
所以接下来,我们就来编写这个自定义控制器的业务逻辑,它的主要内容如下所示:
func (c *Controller) runWorker() {
for c.processNextWorkItem() {
}
}
func (c *Controller) processNextWorkItem() bool {
obj, shutdown := c.workqueue.Get()
...
err := func(obj interface{}) error {
...
if err := c.syncHandler(key); err != nil {
return fmt.Errorf("error syncing '%s': %s", key, err.Error())
}
c.workqueue.Forget(obj)
...
return nil
}(obj)
...
return true
}
func (c *Controller) syncHandler(key string) error {
namespace, name, err := cache.SplitMetaNamespaceKey(key)
...
network, err := c.networksLister.Networks(namespace).Get(name)
if err != nil {
if errors.IsNotFound(err) {
glog.Warningf("Network does not exist in local cache: %s/%s, will delete it from Neutron ...",
namespace, name)
glog.Warningf("Network: %s/%s does not exist in local cache, will delete it from Neutron ...",
namespace, name)
// FIX ME: call Neutron API to delete this network by name.
//
// neutron.Delete(namespace, name)
return nil
}
...
return err
}
glog.Infof("[Neutron] Try to process network: %#v ...", network)
// FIX ME: Do diff().
//
// actualNetwork, exists := neutron.Get(namespace, name)
//
// if !exists {
// neutron.Create(namespace, name)
// } else if !reflect.DeepEqual(actualNetwork, network) {
// neutron.Update(namespace, name)
// }
return nil
}
可以看到,在这个执行周期里(processNextWorkItem),我们首先从工作队列里出队(workqueue.Get)了一个成员,也就是一个 Key(Network 对象的:namespace/name)。
然后,在 syncHandler 方法中,我使用这个 Key,尝试从 Informer 维护的缓存中拿到了它所对应的 Network 对象。
可以看到,在这里,我使用了 networksLister 来尝试获取这个 Key 对应的 Network 对象。这个操作,其实就是在访问本地缓存的索引。实际上,在 Kubernetes 的源码中,你会经常看到控制器从各种 Lister 里获取对象,比如:podLister、nodeLister 等等,它们使用的都是 Informer 和缓存机制。
而如果控制循环从缓存中拿不到这个对象(即:networkLister 返回了 IsNotFound 错误),那就意味着这个 Network 对象的 Key 是通过前面的“删除”事件添加进工作队列的。所以,尽管队列里有这个 Key,但是对应的 Network 对象已经被删除了。
这时候,我就需要调用 Neutron 的 API,把这个 Key 对应的 Neutron 网络从真实的集群里删除掉。
而如果能够获取到对应的 Network 对象,我就可以执行控制器模式里的对比“期望状态”和“实际状态”的逻辑了。
其中,自定义控制器“千辛万苦”拿到的这个 Network 对象,正是 APIServer 里保存的“期望状态”,即:用户通过 YAML 文件提交到 APIServer 里的信息。当然,在我们的例子里,它已经被 Informer 缓存在了本地。
那么,“实际状态”又从哪里来呢?
当然是来自于实际的集群了。
所以,我们的控制循环需要通过 Neutron API 来查询实际的网络情况。
比如,我可以先通过 Neutron 来查询这个 Network 对象对应的真实网络是否存在。
- 如果不存在,这就是一个典型的“期望状态”与“实际状态”不一致的情形。这时,我就需要使用这个 Network 对象里的信息(比如:CIDR 和 Gateway),调用 Neutron API 来创建真实的网络。
- 如果存在,那么,我就要读取这个真实网络的信息,判断它是否跟 Network 对象里的信息一致,从而决定我是否要通过 Neutron 来更新这个已经存在的真实网络。
这样,我就通过对比“期望状态”和“实际状态”的差异,完成了一次调协(Reconcile)的过程。
至此,一个完整的自定义 API 对象和它所对应的自定义控制器,就编写完毕了。
接下来,我们就一起来把这个项目运行起来,查看一下它的工作情况。
你可以自己编译这个项目,也可以直接使用我编译好的二进制文件(samplecrd-controller)。编译并启动这个项目的具体流程如下所示:
# Clone repo
$ git clone https://github.com/resouer/k8s-controller-custom-resource$ cd k8s-controller-custom-resource
### Skip this part if you don't want to build
# Install dependency
$ go get github.com/tools/godep
$ godep restore
# Build
$ go build -o samplecrd-controller .
$ ./samplecrd-controller -kubeconfig=$HOME/.kube/config -alsologtostderr=true
I0915 12:50:29.051349 27159 controller.go:84] Setting up event handlers
I0915 12:50:29.051615 27159 controller.go:113] Starting Network control loop
I0915 12:50:29.051630 27159 controller.go:116] Waiting for informer caches to sync
E0915 12:50:29.066745 27159 reflector.go:134] github.com/resouer/k8s-controller-custom-resource/pkg/client/informers/externalversions/factory.go:117: Failed to list *v1.Network: the server could not find the requested resource (get networks.samplecrd.k8s.io)
...
你可以看到,自定义控制器被启动后,一开始会报错。
这是因为,此时 Network 对象的 CRD 还没有被创建出来,所以 Informer 去 APIServer 里“获取”(List)Network 对象时,并不能找到 Network 这个 API 资源类型的定义,即:
Failed to list *v1.Network: the server could not find the requested resource (get networks.samplecrd.k8s.io)
所以,接下来我就需要创建 Network 对象的 CRD,这个操作在前面已经介绍过了。
在另一个 shell 窗口里执行:
$ kubectl apply -f crd/network.yaml
这时候,你就会看到控制器的日志恢复了正常,控制循环启动成功:
...
I0915 12:50:29.051630 27159 controller.go:116] Waiting for informer caches to sync
...
I0915 12:52:54.346854 25245 controller.go:121] Starting workers
I0915 12:52:54.346914 25245 controller.go:127] Started workers
接下来,我就可以进行 Network 对象的增删改查操作了。
首先,创建一个 Network 对象:
$ cat example/example-network.yaml
apiVersion: samplecrd.k8s.io/v1
kind: Network
metadata:
name: example-network
spec:
cidr: "192.168.0.0/16"
gateway: "192.168.0.1"
$ kubectl apply -f example/example-network.yaml
network.samplecrd.k8s.io/example-network created
这时候,查看一下控制器的输出:
...
I0915 12:50:29.051349 27159 controller.go:84] Setting up event handlers
I0915 12:50:29.051615 27159 controller.go:113] Starting Network control loop
I0915 12:50:29.051630 27159 controller.go:116] Waiting for informer caches to sync
...
I0915 12:52:54.346854 25245 controller.go:121] Starting workers
I0915 12:52:54.346914 25245 controller.go:127] Started workers
I0915 12:53:18.064409 25245 controller.go:229] [Neutron] Try to process network: &v1.Network{TypeMeta:v1.TypeMeta{Kind:"", APIVersion:""}, ObjectMeta:v1.ObjectMeta{Name:"example-network", GenerateName:"", Namespace:"default", ... ResourceVersion:"479015", ... Spec:v1.NetworkSpec{Cidr:"192.168.0.0/16", Gateway:"192.168.0.1"}} ...
I0915 12:53:18.064650 25245 controller.go:183] Successfully synced 'default/example-network'
...
可以看到,我们上面创建 example-network 的操作,触发了 EventHandler 的“添加”事件,从而被放进了工作队列。
紧接着,控制循环就从队列里拿到了这个对象,并且打印出了正在“处理”这个 Network 对象的日志。
可以看到,这个 Network 的 ResourceVersion,也就是 API 对象的版本号,是 479015,而它的 Spec 字段的内容,跟我提交的 YAML 文件一摸一样,比如,它的 CIDR 网段是:192.168.0.0/16。
这时候,我来修改一下这个 YAML 文件的内容,如下所示:
$ cat example/example-network.yaml
apiVersion: samplecrd.k8s.io/v1
kind: Network
metadata:
name: example-network
spec:
cidr: "192.168.1.0/16"
gateway: "192.168.1.1"
可以看到,我把这个 YAML 文件里的 CIDR 和 Gateway 字段的修改成了 192.168.1.0/16 网段。
然后,我们执行了 kubectl apply 命令来提交这次更新,如下所示:
$ kubectl apply -f example/example-network.yaml
network.samplecrd.k8s.io/example-network configured
这时候,我们就可以观察一下控制器的输出:
...
I0915 12:53:51.126029 25245 controller.go:229] [Neutron] Try to process network: &v1.Network{TypeMeta:v1.TypeMeta{Kind:"", APIVersion:""}, ObjectMeta:v1.ObjectMeta{Name:"example-network", GenerateName:"", Namespace:"default", ... ResourceVersion:"479062", ... Spec:v1.NetworkSpec{Cidr:"192.168.1.0/16", Gateway:"192.168.1.1"}} ...
I0915 12:53:51.126348 25245 controller.go:183] Successfully synced 'default/example-network'
可以看到,这一次,Informer 注册的“更新”事件被触发,更新后的 Network 对象的 Key 被添加到了工作队列之中。
所以,接下来控制循环从工作队列里拿到的 Network 对象,与前一个对象是不同的:它的 ResourceVersion 的值变成了 479062;而 Spec 里的字段,则变成了 192.168.1.0/16 网段。
最后,我再把这个对象删除掉:
$ kubectl delete -f example/example-network.yaml
这一次,在控制器的输出里,我们就可以看到,Informer 注册的“删除”事件被触发,并且控制循环“调用”Neutron API“删除”了真实环境里的网络。这个输出如下所示:
W0915 12:54:09.738464 25245 controller.go:212] Network: default/example-network does not exist in local cache, will delete it from Neutron ...
I0915 12:54:09.738832 25245 controller.go:215] [Neutron] Deleting network: default/example-network ...
I0915 12:54:09.738854 25245 controller.go:183] Successfully synced 'default/example-network'
以上,就是编写和使用自定义控制器的全部流程了。
在原生API对象上自定义Informer
实际上,这套流程不仅可以用在自定义 API 资源上,也完全可以用在 Kubernetes 原生的默认 API 对象上。
比如,我们在 main 函数里,除了创建一个 Network Informer 外,还可以初始化一个 Kubernetes 默认 API 对象的 Informer 工厂,比如 Deployment 对象的 Informer。这个具体做法如下所示:
func main() {
...
kubeInformerFactory := kubeinformers.NewSharedInformerFactory(kubeClient, time.Second*30)
controller := NewController(kubeClient, exampleClient,
kubeInformerFactory.Apps().V1().Deployments(),
networkInformerFactory.Samplecrd().V1().Networks())
go kubeInformerFactory.Start(stopCh)
...
}
首先 ,使用 Kubernetes 的 client(kubeClient)创建了一个工厂;
然后,我用跟 Network 类似的处理方法,生成了一个 Deployment Informer;
接着,我把 Deployment Informer 传递给了自定义控制器;当然,我也要调用 Start 方法来启动这个 Deployment Informer。
而有了这个 Deployment Informer 后,这个控制器也就持有了所有 Deployment 对象的信息。接下来,它既可以通过 deploymentInformer.Lister() 来获取 Etcd 里的所有 Deployment 对象,也可以为这个 Deployment Informer 注册具体的 Handler 来。
更重要的是,这就使得在这个自定义控制器里面,我可以通过对自定义 API 对象和默认 API 对象进行协同,从而实现更加复杂的编排功能。
比如:用户每创建一个新的 Deployment,这个自定义控制器,就可以为它创建一个对应的 Network 供它使用。
总结Kubernetes API 编程范式的核心思想
- 所谓的 Informer,就是一个自带缓存和索引机制,可以触发 Handler 的客户端库。这个本地缓存在 Kubernetes 中一般被称为 Store,索引一般被称为 Index。
- Informer 使用了 Reflector 包,它是一个可以通过 ListAndWatch 机制获取并监视 API 对象变化的客户端封装。
- Reflector 和 Informer 之间,用到了一个“增量先进先出队列”进行协同。而 Informer 与你要编写的控制循环之间,则使用了一个工作队列来进行协同。
- 在实际应用中,除了控制循环之外的所有代码,实际上都是 Kubernetes 为你自动生成的,即:pkg/client/{informers, listers, clientset}里的内容。
- 而这些自动生成的代码,就为我们提供了一个可靠而高效地获取 API 对象“期望状态”的编程库。
- 所以,接下来,作为开发者,你就只需要关注如何拿到“实际状态”,然后如何拿它去跟“期望状态”做对比,从而决定接下来要做的业务逻辑即可。
为什么 Informer 和你编写的控制循环之间,一定要使用一个工作队列来进行协作呢?
一般这种工作队列结构主要是为了匹配双方速度不一致,为了解耦,防止控制循环执行过慢把Informer 拖死。比如典型生产者消费者问题。
基于角色的权限控制:RBAC
在 Kubernetes 项目中,负责完成授权(Authorization)工作的机制,就是 RBAC:基于角色的访问控制(Role-Based Access Control)。
明确三个最基本的概念。
- Role:角色,它其实是一组规则,定义了一组对 Kubernetes API 对象的操作权限。
- Subject:被作用者,既可以是“人”,也可以是“机器”,也可以使你在 Kubernetes 里定义的“用户”。
- RoleBinding:定义了“被作用者”和“角色”的绑定关系。
而这三个概念,其实就是整个 RBAC 体系的核心所在。
Role
实际上,Role 本身就是一个 Kubernetes 的 API 对象,定义如下所示:
kind: Role
apiVersion: rbac.authorization.k8s.io/v1
metadata:
namespace: mynamespace
name: example-role
rules:
- apiGroups: [""]
resources: ["pods"]
verbs: ["get", "watch", "list"]
首先,这个 Role 对象指定了它能产生作用的 Namepace 是:mynamespace。
Namespace 是 Kubernetes 项目里的一个逻辑管理单位。不同 Namespace 的 API 对象,在通过 kubectl 命令进行操作的时候,是互相隔离开的。
当然,这仅限于逻辑上的“隔离”,Namespace 并不会提供任何实际的隔离或者多租户能力。
然后,这个 Role 对象的 rules 字段,就是它所定义的权限规则。在上面的例子里,这条规则的含义就是:允许“被作用者”,对 mynamespace 下面的 Pod 对象,进行 GET、WATCH 和 LIST 操作。
那么,这个具体的“被作用者”又是如何指定的呢?这就需要通过 RoleBinding 来实现了。
RoleBinding
当然,RoleBinding 本身也是一个 Kubernetes 的 API 对象。它的定义如下所示:
kind: RoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: example-rolebinding
namespace: mynamespace
subjects:
- kind: User
name: example-user
apiGroup: rbac.authorization.k8s.io
roleRef:
kind: Role
name: example-role
apiGroup: rbac.authorization.k8s.io
可以看到,这个 RoleBinding 对象里定义了一个 subjects 字段,即“被作用者”。它的类型是 User,即 Kubernetes 里的用户。这个用户的名字是 example-user。
可是,在 Kubernetes 中,其实并没有一个叫作“User”的 API 对象。而且,我们在前面和部署使用 Kubernetes 的流程里,既不需要 User,也没有创建过 User。
这个 User 到底是从哪里来的呢?
实际上,Kubernetes 里的“User”,也就是“用户”,只是一个授权系统里的逻辑概念。它需要通过外部认证服务,比如 Keystone,来提供。或者,你也可以直接给 APIServer 指定一个用户名、密码文件。那么 Kubernetes 的授权系统,就能够从这个文件里找到对应的“用户”了。当然,在大多数私有的使用环境中,我们只要使用 Kubernetes 提供的内置“用户”,就足够了。
接下来,我们会看到一个 roleRef 字段。正是通过这个字段,RoleBinding 对象就可以直接通过名字,来引用我们前面定义的 Role 对象(example-role),从而定义了“被作用者(Subject)”和“角色(Role)”之间的绑定关系。
需要再次提醒的是,Role 和 RoleBinding 对象都是 Namespaced 对象(NamespacedObject),它们对权限的限制规则仅在它们自己的 Namespace 内有效,roleRef 也只能引用当前 Namespace 里的 Role 对象
那么,对于非 Namespaced(Non-namespaced)对象(比如:Node),或者,某一个 Role 想要作用于所有的 Namespace 的时候,我们又该如何去做授权呢?
这时候,我们就必须要使用 ClusterRole 和 ClusterRoleBinding 这两个组合了。这两个 API 对象的用法跟 Role 和 RoleBinding 完全一样。只不过,它们的定义里,没有了 Namespace 字段,如下所示:
kind: ClusterRole
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: example-clusterrole
rules:
- apiGroups: [""]
resources: ["pods"]
verbs: ["get", "watch", "list"]
kind: ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: example-clusterrolebinding
subjects:
- kind: User
name: example-user
apiGroup: rbac.authorization.k8s.io
roleRef:
kind: ClusterRole
name: example-clusterrole
apiGroup: rbac.authorization.k8s.io
上面的例子里的 ClusterRole 和 ClusterRoleBinding 的组合,意味着名叫 example-user 的用户,拥有对所有 Namespace 里的 Pod 进行 GET、WATCH 和 LIST 操作的权限。
更进一步地,在 Role 或者 ClusterRole 里面,如果要赋予用户 example-user 所有权限,那你就可以给它指定一个 verbs 字段的全集,如下所示:
verbs: ["get", "list", "watch", "create", "update", "patch", "delete"]
这些就是当前 Kubernetes(v1.11)里能够对 API 对象进行的所有操作了。
类似的,Role 对象的 rules 字段也可以进一步细化。比如,你可以只针对某一个具体的对象进行权限设置,如下所示:
rules:
- apiGroups: [""]
resources: ["configmaps"]
resourceNames: ["my-config"]
verbs: ["get"]
这个例子就表示,这条规则的“被作用者”,只对名叫“my-config”的 ConfigMap 对象,有进行 GET 操作的权限。
由 Kubernetes 负责管理的“内置用户”: ServiceAccount
为 ServiceAccount 分配权限的过程。
首先,我们要定义一个 ServiceAccount。它的 API 对象非常简单,如下所示:
apiVersion: v1
kind: ServiceAccount
metadata:
namespace: mynamespace
name: example-sa
可以看到,一个最简单的 ServiceAccount 对象只需要 Name 和 Namespace 这两个最基本的字段。
然后,我们通过编写 RoleBinding 的 YAML 文件,来为这个 ServiceAccount 分配权限:
kind: RoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: example-rolebinding
namespace: mynamespace
subjects:
- kind: ServiceAccount
name: example-sa
namespace: mynamespace
roleRef:
kind: Role
name: example-role
apiGroup: rbac.authorization.k8s.io
可以看到,在这个 RoleBinding 对象里,subjects 字段的类型(kind),不再是一个 User,而是一个名叫 example-sa 的 ServiceAccount。而 roleRef 引用的 Role 对象,依然名叫 example-role,也这就是上面定义的Role 对象。
接着,我们用 kubectl 命令创建这三个对象:
$ kubectl create -f svc-account.yaml
$ kubectl create -f role-binding.yaml
$ kubectl create -f role.yaml
然后,我们来查看一下这个 ServiceAccount 的详细信息:
$ kubectl get sa -n mynamespace -o yaml
- apiVersion: v1
kind: ServiceAccount
metadata:
creationTimestamp: 2018-09-08T12:59:17Z
name: example-sa
namespace: mynamespace
resourceVersion: "409327"
...
secrets:
- name: example-sa-token-vmfg6
可以看到,Kubernetes 会为一个 ServiceAccount 自动创建并分配一个 Secret 对象,即:上述 ServiceAcount 定义里最下面的 secrets 字段。
这个 Secret,就是这个 ServiceAccount 对应的、用来跟 APIServer 进行交互的授权文件,我们一般称它为:Token。Token 文件的内容一般是证书或者密码,它以一个 Secret 对象的方式保存在 Etcd 当中。
这时候,用户的 Pod,就可以声明使用这个 ServiceAccount 了,比如下面这个例子:
apiVersion: v1
kind: Pod
metadata:
namespace: mynamespace
name: sa-token-test
spec:
containers:
- name: nginx
image: nginx:1.7.9
serviceAccountName: example-sa
在这个例子里,我定义了 Pod 要使用的要使用的 ServiceAccount 的名字是:example-sa。
等这个 Pod 运行起来之后,我们就可以看到,该 ServiceAccount 的 token,也就是一个 Secret 对象,被 Kubernetes 自动挂载到了容器的 /var/run/secrets/kubernetes.io/serviceaccount 目录下,如下所示:
$ kubectl describe pod sa-token-test -n mynamespace
Name: sa-token-test
Namespace: mynamespace
...
Containers:
nginx:
...
Mounts:
/var/run/secrets/kubernetes.io/serviceaccount from example-sa-token-vmfg6 (ro)
这时候,我们可以通过 kubectl exec 查看到这个目录里的文件:
$ kubectl exec -it sa-token-test -n mynamespace -- /bin/bash
root@sa-token-test:/# ls /var/run/secrets/kubernetes.io/serviceaccount
ca.crt namespace token
如上所示,容器里的应用,就可以使用这个 ca.crt 来访问 APIServer 了。更重要的是,此时它只能够做 GET、WATCH 和 LIST 操作。因为 example-sa 这个 ServiceAccount 的权限,已经被我们绑定了 Role 做了限制。
如果一个 Pod 没有声明 serviceAccountName,Kubernetes 会自动在它的 Namespace 下创建一个名叫 default 的默认 ServiceAccount,然后分配给这个 Pod。
但在这种情况下,这个默认 ServiceAccount 并没有关联任何 Role。也就是说,此时它有访问 APIServer 的绝大多数权限。当然,这个访问所需要的 Token,还是默认 ServiceAccount 对应的 Secret 对象为它提供的,如下所示。
$kubectl describe sa default
Name: default
Namespace: default
Labels: <none>
Annotations: <none>
Image pull secrets: <none>
Mountable secrets: default-token-s8rbq
Tokens: default-token-s8rbq
Events: <none>
$ kubectl get secret
NAME TYPE DATA AGE
kubernetes.io/service-account-token 3 82d
$ kubectl describe secret default-token-s8rbq
Name: default-token-s8rbq
Namespace: default
Labels: <none>
Annotations: kubernetes.io/service-account.name=default
kubernetes.io/service-account.uid=ffcb12b2-917f-11e8-abde-42010aa80002
Type: kubernetes.io/service-account-token
Data
ca.crt: 1025 bytes
namespace: 7 bytes
token: <TOKEN数据>
可以看到,Kubernetes 会自动为默认 ServiceAccount 创建并绑定一个特殊的 Secret:它的类型是kubernetes.io/service-account-token;它的 Annotation 字段,声明了kubernetes.io/service-account.name=default,即这个 Secret 会跟同一 Namespace 下名叫 default 的 ServiceAccount 进行绑定。
所以,在生产环境中,强烈建议为所有 Namespace 下的默认 ServiceAccount,绑定一个只读权限的 Role。
除了前面使用的“用户”(User),Kubernetes 还拥有“用户组”(Group)的概念,也就是一组“用户”的意思。 如果你为 Kubernetes 配置了外部认证服务的话,这个“用户组”的概念就会由外部认证服务提供。
而对于 Kubernetes 的内置“用户”ServiceAccount 来说,上述“用户组”的概念也同样适用。
实际上,一个 ServiceAccount,在 Kubernetes 里对应的“用户”的名字是:
system:serviceaccount:<Namespace名字>:<ServiceAccount名字>
而它对应的内置“用户组”的名字,就是:
system:serviceaccounts:<Namespace名字>
比如,现在我们可以在 RoleBinding 里定义如下的 subjects:
subjects:
- kind: Group
name: system:serviceaccounts:mynamespace
apiGroup: rbac.authorization.k8s.io
这就意味着这个 Role 的权限规则,作用于 mynamespace 里的所有 ServiceAccount。这就用到了“用户组”的概念。
比如:
subjects:
- kind: Group
name: system:serviceaccounts
apiGroup: rbac.authorization.k8s.io
就意味着这个 Role 的权限规则,作用于整个系统里的所有 ServiceAccount。
在 Kubernetes 中已经内置了很多个为系统保留的 ClusterRole,它们的名字都以 system: 开头。你可以通过 kubectl get clusterroles 查看到它们。
Kubernetes 还提供了四个预先定义好的 ClusterRole 来供用户直接使用:
- cluster-admin;
- admin;
- edit;
- view。
cluster-admin 角色,对应的是整个 Kubernetes 项目中的最高权限(verbs=*)所以,请务必要谨慎而小心地使用 cluster-admin。
Operator 的工作原理
在 Kubernetes 中,管理“有状态应用”是一个比较复杂的过程,尤其是编写 Pod 模板的时候,总有一种“在 YAML 文件里编程序”的感觉,让人很不舒服。
而在 Kubernetes 生态中,还有一个相对更加灵活和编程友好的管理“有状态应用”的解决方案,它就是:Operator。
Operator 的工作原理,实际上是利用了 Kubernetes 的自定义 API 资源(CRD),来描述我们想要部署的“有状态应用”;然后在自定义控制器里,根据自定义 API 对象的变化,来完成具体的部署和运维工作。
编写一个 Operator,与前面编写一个自定义控制器的过程,没什么不同。
列举出一些不适用 CRD 的场景?以及造成 CRD 性能瓶颈的 主要原因?
CRD 目前不支持 protobuf,当 API Object 数量 >1K,或者单个对象 >1KB,或者高频请求时,CRD 的响应都会有问题。
所以,CRD 千万不能也不应该被当作数据库使用。其实像 Kubernetes ,或者说 Etcd 本身,最佳的使用场景就是作为配置管理的依赖。
此外,如果业务需求不能用 CRD 进行建模的时候,比如,需要等待 API 最终返回,或者需要检查 API 的返回值,也是不能用 CRD 的。
同时,当你需要完整的 APIServer 而不是只关心 API 对象的时候,请使用 API Aggregator。
PV、PVC、StorageClass
PV 描述的,是持久化存储数据卷。
PVC 描述的,则是 Pod 所希望使用的持久化存储的属性。
StorageClass 对象的作用,其实就是创建 PV 的模板。
具体地说,StorageClass 对象会定义如下两个部分内容:
- 第一,PV 的属性。比如,存储类型、Volume 的大小等等。
- 第二,创建这种 PV 需要用到的存储插件。比如,Ceph 等等。
用如下所示的一幅示意图描述三者之间的关系:
从图中我们可以看到,在这个体系中:
- PVC 描述的,是 Pod 想要使用的持久化存储的属性,比如存储的大小、读写权限等。
- PV 描述的,则是一个具体的 Volume 的属性,比如 Volume 的类型、挂载目录、远程存储服务器地址等。
- 而 StorageClass 的作用,则是充当 PV 的模板。并且,只有同属于一个 StorageClass 的 PV 和 PVC,才可以绑定在一起。
当然,StorageClass 的另一个重要作用,是指定 PV 的 Provisioner(存储插件)。这时候,如果你的存储插件支持 Dynamic Provisioning 的话,Kubernetes 就可以自动为你创建 PV 了。
删除 PV
手动创建 PV 的方式,即 Static 的 PV 管理方式,在删除 PV 时需要按如下流程执行操作:
- 删除使用这个 PV 的 Pod;
- 从宿主机移除本地磁盘(比如,umount 它);
- 删除 PVC;
- 删除 PV。
如果不按照这个流程的话,这个 PV 的删除就会失败。
CSI插件
待补充
单机容器网络的实现原理和 docker0 网桥的作用。
Veth Pair 的虚拟设备
Veth Pair 设备的特点是:它被创建出来后,总是以两张虚拟网卡(Veth Peer)的形式成对出现的。并且,从其中一个“网卡”发出的数据包,可以直接出现在与它对应的另一张“网卡”上,哪怕这两个“网卡”在不同的 Network Namespace 里。
这就使得 Veth Pair 常常被用作连接不同 Network Namespace 的“网线”。
当创建容器的时候,这个容器里有一张叫作 eth0 的网卡,它正是一个 Veth Pair 设备在容器里的这一端。
而这个 Veth Pair 设备的另一端,则在宿主机上。如:
# 在宿主机上
$ ifconfig
...
docker0 Link encap:Ethernet HWaddr 02:42:d8:e4:df:c1
inet addr:172.17.0.1 Bcast:0.0.0.0 Mask:255.255.0.0
inet6 addr: fe80::42:d8ff:fee4:dfc1/64 Scope:Link
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
RX packets:309 errors:0 dropped:0 overruns:0 frame:0
TX packets:372 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:0
RX bytes:18944 (18.9 KB) TX bytes:8137789 (8.1 MB)
veth9c02e56 Link encap:Ethernet HWaddr 52:81:0b:24:3d:da
inet6 addr: fe80::5081:bff:fe24:3dda/64 Scope:Link
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
RX packets:288 errors:0 dropped:0 overruns:0 frame:0
TX packets:371 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:0
RX bytes:21608 (21.6 KB) TX bytes:8137719 (8.1 MB)
$ brctl show
bridge name bridge id STP enabled interfaces
docker0 8000.0242d8e4dfc1 no veth9c02e56
通过 brctl show 的输出,你可以看到这张 veth9c02e56 网卡被“插”在了 docker0 上。
同一个宿主机上的不同容器通过 docker0 网桥进行通信,如下所示:
在默认情况下,被限制在 Network Namespace 里的容器进程,实际上是通过 Veth Pair 设备 + 宿主机网桥的方式,实现了跟同其他容器的数据交换。
容器跨主机网络
要理解容器“跨主通信”的原理,就一定要先从 Flannel 这个项目说起。
Flannel 项目是 CoreOS 公司主推的容器网络方案。事实上,Flannel 项目本身只是一个框架,真正为我们提供容器网络功能的,是 Flannel 的后端实现。目前,Flannel 支持三种后端实现,分别是:
- VXLAN;
- host-gw;
- UDP。
UDP 模式
UDP 模式是 Flannel 项目最早支持的一种方式,却也是性能最差的一种方式。所以,这个模式目前已经被弃用。
UDP模式跨宿主机网络的实现原理
Flannel进程在宿主机上创建flannel0设备,它是一个 TUN 设备(Tunnel 设备)。
在 Linux 中,TUN 设备是一种工作在三层(Network Layer)的虚拟网络设备。TUN 设备的功能非常简单,即:在操作系统内核和用户应用程序之间传递 IP 包。
当操作系统将一个 IP 包发送给 flannel0 设备之后,flannel0 就会把这个 IP 包,交给创建这个设备的应用程序,也就是 Flannel 进程。这是一个从内核态(Linux 操作系统)向用户态(Flannel 进程)的流动方向。
反之,如果 Flannel 进程向 flannel0 设备发送了一个 IP 包,那么这个 IP 包就会出现在宿主机网络栈中,然后根据宿主机的路由表进行下一步处理。这是一个从用户态向内核态的流动方向。
所以,当 IP 包从容器经过 docker0 出现在宿主机,然后又根据路由表进入 flannel0 设备后,宿主机上的 flanneld 进程(Flannel 项目在每个宿主机上的主进程),就会收到这个 IP 包。
在由 Flannel 管理的容器网络里,一台宿主机上的所有容器,都属于该宿主机被分配的一个“子网”。
子网与宿主机的对应关系,正是保存在 Etcd 当中,如下所示:
$ etcdctl ls /coreos.com/network/subnets
/coreos.com/network/subnets/100.96.1.0-24
/coreos.com/network/subnets/100.96.2.0-24
/coreos.com/network/subnets/100.96.3.0-24
假设有两台宿主机:
- 宿主机 Node 1 上有一个容器 container-1,它的 IP 地址是 100.96.1.2,对应的 docker0 网桥的地址是:100.96.1.1/24。
- 宿主机 Node 2 上有一个容器 container-2,它的 IP 地址是 100.96.2.3,对应的 docker0 网桥的地址是:100.96.2.1/24。
每台宿主机上的 flanneld,都监听着一个 8285 端口,flanneld进程 在收到 container-1 发给 container-2 的 IP 包之后,会把这个 IP 包直接封装在一个 UDP 包里,然后发送给 Node 2的8285端口。不难理解,这个 UDP 包的源地址,就是 flanneld 所在的 Node 1 的地址,而目的地址,则是 container-2 所在的宿主机 Node 2 的地址。
通过这样一个普通的、宿主机之间的 UDP 通信,一个 UDP 包就从 Node 1 到达了 Node 2。而 Node 2 上监听 8285 端口的进程也是 flanneld,所以这时候,flanneld 就可以从这个 UDP 包里解析出封装在里面的、container-1 发来的原 IP 包。
而接下来 flanneld 的工作就非常简单了:flanneld 会直接把这个 IP 包发送给它所管理的 TUN 设备,即 flannel0 设备。
根据 TUN 设备的原理,这正是一个从用户态向内核态的流动方向(Flannel 进程向 TUN 设备发送数据包),所以 Linux 内核网络栈就会负责处理这个 IP 包,具体的处理方法,就是通过本机的路由表来寻找这个 IP 包的下一步流向。
Linux 内核会按照路由规则,把这个 IP 包转发给 docker0 网桥。
docker0 网桥会扮演二层交换机的角色,将数据包发送给正确的端口,进而通过 Veth Pair 设备进入到 container-2 的 Network Namespace 里。
而 container-2 返回给 container-1 的数据包,则会经过与上述过程完全相反的路径回到 container-1 中。
docker0 网桥的地址范围必须是 Flannel 为宿主机分配的子网。
基于 Flannel UDP 模式的跨主通信的基本原理
Flannel UDP 模式提供的其实是一个三层的 Overlay 网络,即:它首先对发出端的 IP 包进行 UDP 封装,然后在接收端进行解封装拿到原始的 IP 包,进而把这个 IP 包转发给目标容器。这就好比,Flannel 在不同宿主机上的两个容器之间打通了一条“隧道”,使得这两个容器可以直接使用 IP 地址进行通信,而无需关心容器和宿主机的分布情况。
VXLAN 模式 主流的容器网络方案
VXLAN,即 Virtual Extensible LAN(虚拟可扩展局域网),是 Linux 内核本身就支持的一种网络虚似化技术。所以说,VXLAN 可以完全在内核态实现上述封装和解封装的工作,从而通过与前面相似的“隧道”机制,构建出覆盖网络(Overlay Network)。
VXLAN 的覆盖网络的设计思想是:在现有的三层网络之上,“覆盖”一层虚拟的、由内核 VXLAN 模块负责维护的二层网络,使得连接在这个 VXLAN 二层网络上的“主机”(虚拟机或者容器都可以)之间,可以像在同一个局域网(LAN)里那样自由通信。当然,实际上,这些“主机”可能分布在不同的宿主机上,甚至是分布在不同的物理机房里。
而为了能够在二层网络上打通“隧道”,VXLAN 会在宿主机上设置一个特殊的网络设备作为“隧道”的两端。这个设备就叫作 VTEP,即:VXLAN Tunnel End Point(虚拟隧道端点)。
而 VTEP 设备的作用,其实跟 flanneld 进程非常相似。只不过,它进行封装和解封装的对象,是二层数据帧(Ethernet frame);而且这个工作的执行流程,全部是在内核里完成的(因为 VXLAN 本身就是 Linux 内核中的一个模块)。
基于 VTEP 设备进行“隧道”通信的流程
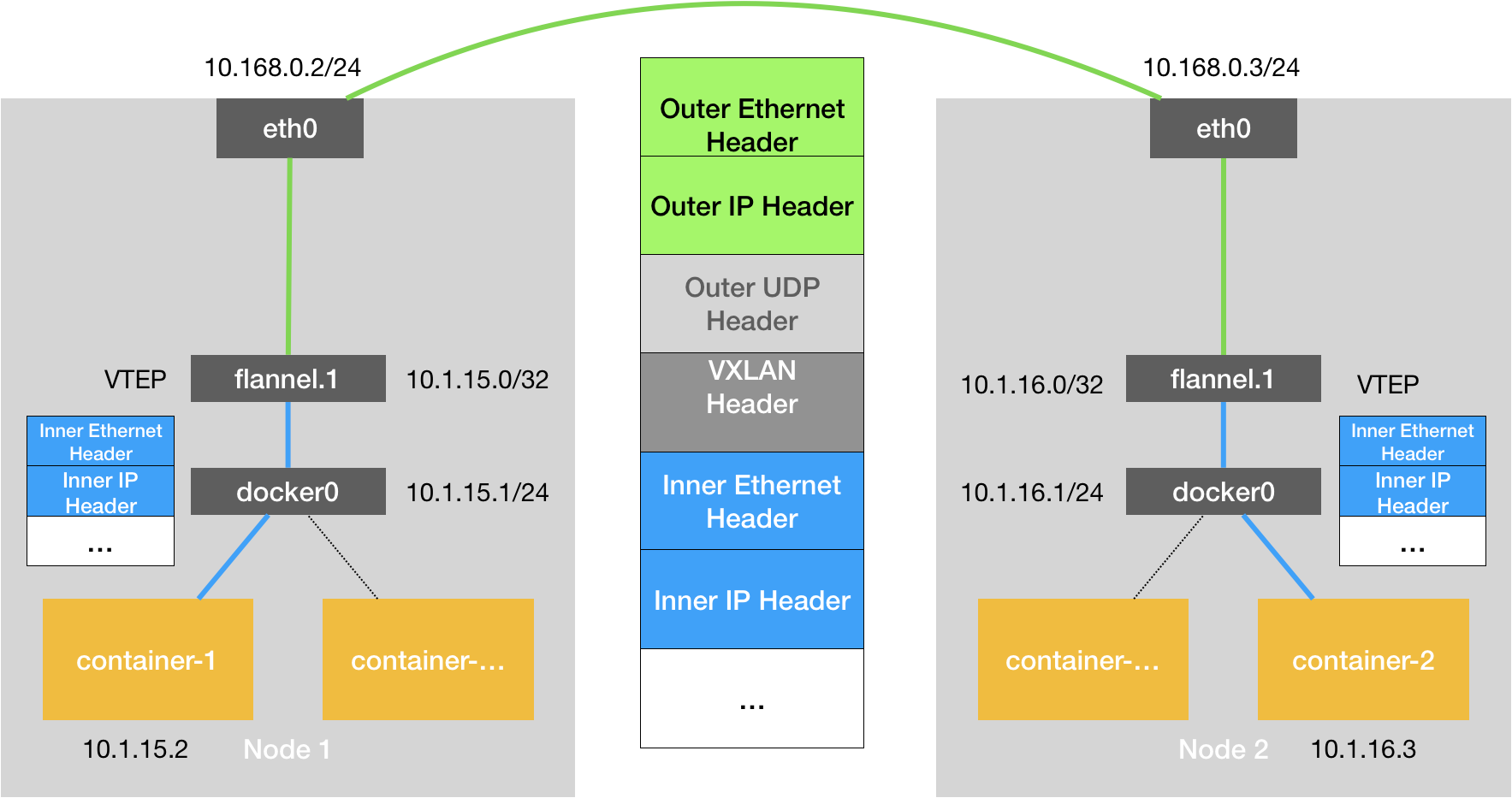
可以看到,图中每台宿主机上名叫 flannel.1 的设备,就是 VXLAN 所需的 VTEP 设备,它既有 IP 地址,也有 MAC 地址。
UDP 和 VXLAN 有一个共性,那就是用户的容器都连接在 docker0 网桥上。而网络插件则在宿主机上创建了一个特殊的设备(UDP 模式创建的是 TUN 设备,VXLAN 模式创建的则是 VTEP 设备),docker0 与这个设备之间,通过 IP 转发(路由表)进行协作。
然后,网络插件真正要做的事情,则是通过某种方法,把不同宿主机上的特殊设备连通,从而达到容器跨主机通信的目的。
在 Kubernetes 环境里,通过一个叫作 CNI 的接口,维护了一个单独的网桥来代替 docker0。这个网桥的名字就叫作:CNI 网桥,它在宿主机上的设备名称默认是:cni0。
如下图所示:
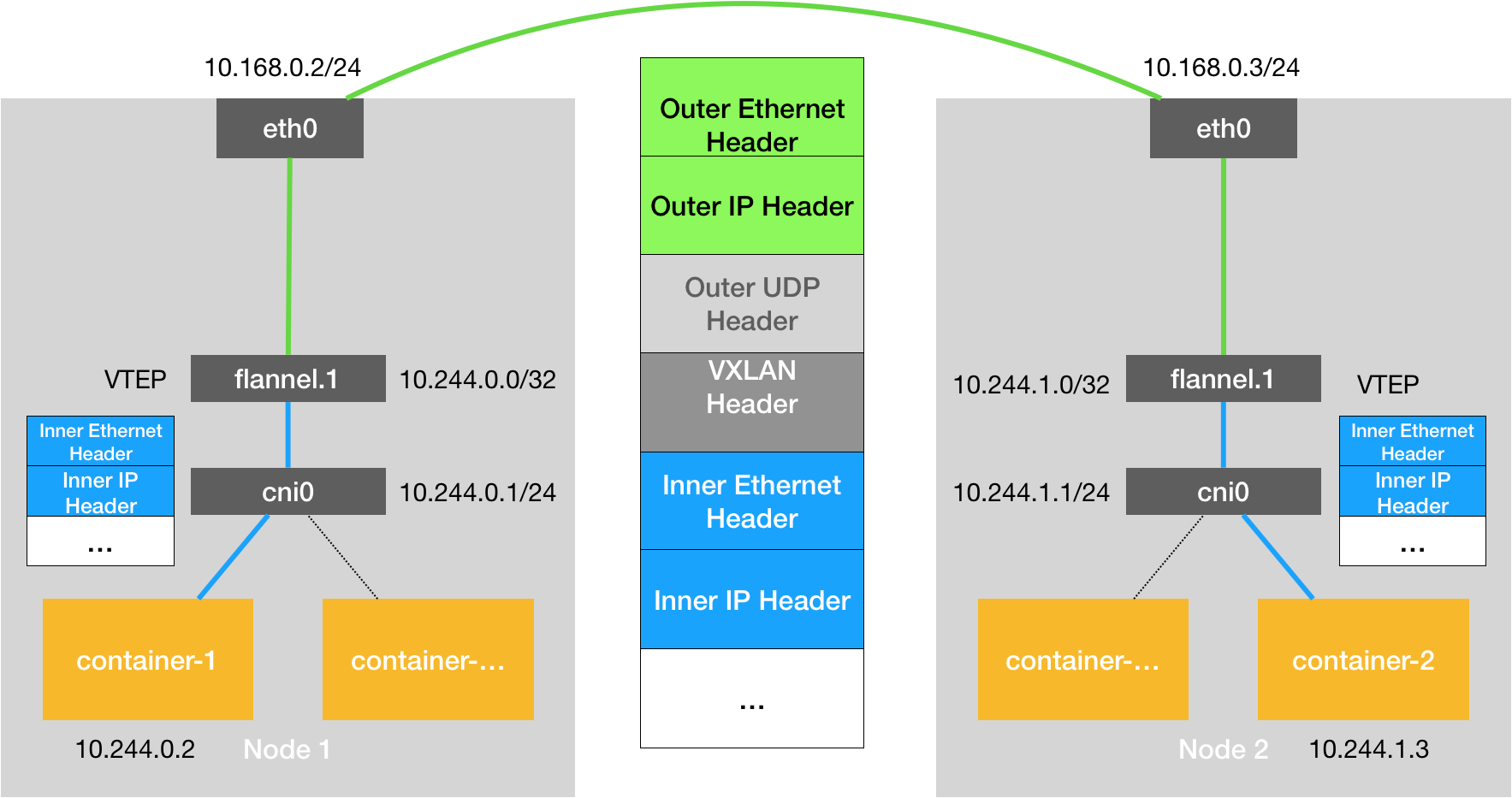
Kubernetes 之所以要设置一个与 docker0 网桥功能几乎一样的 CNI 网桥,主要原因包括两个方面:
- 一方面,Kubernetes 项目并没有使用 Docker 的网络模型(CNM),所以它并不希望、也不具备配置 docker0 网桥的能力;
- 另一方面,这还与 Kubernetes 如何配置 Pod,也就是 Infra 容器的 Network Namespace 密切相关。
CNI 的设计思想,就是:Kubernetes 在启动 Infra 容器之后,就可以直接调用 CNI 网络插件,为这个 Infra 容器的 Network Namespace,配置符合预期的网络栈。
host-gw 模式纯三层(Pure Layer 3)网络方案(还有Calico 项目)

host-gw 模式的工作原理,其实就是将每个 Flannel 子网(Flannel Subnet,比如:10.244.1.0/24)的“下一跳”,设置成了该子网对应的宿主机的 IP 地址。
也就是说,这台“主机”(Host)会充当这条容器通信路径里的“网关”(Gateway)。这也正是“host-gw”的含义。
Flannel 子网和主机的信息,都是保存在 Etcd 当中的。flanneld 只需要 WACTH 这些数据的变化,然后实时更新路由表即可。
注意:在 Kubernetes v1.7 之后,类似 Flannel、Calico 的 CNI 网络插件都是可以直接连接 Kubernetes 的 APIServer 来访问 Etcd 的,无需额外部署 Etcd 给它们使用。
而在这种模式下,容器通信的过程就免除了额外的封包和解包带来的性能损耗。根据实际的测试,host-gw 的性能损失大约在 10% 左右,而其他所有基于 VXLAN“隧道”机制的网络方案,性能损失都在 20%~30% 左右。
当然,通过上面的叙述,你也应该看到,host-gw 模式能够正常工作的核心,就在于 IP 包在封装成帧发送出去的时候,会使用路由表里的“下一跳”来设置目的 MAC 地址。这样,它就会经过二层网络到达目的宿主机。
所以说,Flannel host-gw 模式必须要求集群宿主机之间是二层连通的。
Calico 项目提供的网络解决方案,与 Flannel 的 host-gw 模式,几乎是完全一样的。也就是说,Calico 也会在每台宿主机上,添加一个格式如下所示的路由规则:
<目的容器IP地址段> via <网关的IP地址> dev eth0
其中,网关的 IP 地址,正是目的容器所在宿主机的 IP 地址。
而正如前所述,这个三层网络方案得以正常工作的核心,是为每个容器的 IP 地址,找到它所对应的、“下一跳”的网关。
不过,不同于 Flannel 通过 Etcd 和宿主机上的 flanneld 来维护路由信息的做法,Calico 项目使用了一个“重型武器”来自动地在整个集群中分发路由信息。
这个“重型武器”,就是 BGP。
BGP 的全称是 Border Gateway Protocol,即:边界网关协议。 它是一个 Linux 内核原生就支持的、专门用在大规模数据中心里维护不同的“自治系统”之间路由信息的、无中心的路由协议。
所谓 BGP,就是在大规模网络中实现节点路由信息共享的一种协议。
而 BGP 的这个能力,正好可以取代 Flannel 维护主机上路由表的功能。而且,BGP 这种原生就是为大规模网络环境而实现的协议,其可靠性和可扩展性,远非 Flannel 自己的方案可比。
Calico 工作原理(待补充)
三层网络方案和“隧道模式”的异同,以及各自的优缺点?
隧道模式最大的特点,在于需要通过某种方式比如 UDP 或者 VXLAN 来对原始的容器间通信的网络包进行封装,然后伪装成宿主机间的网络通信来完成容器跨主通信。这个过程中就不可避免的需要封包和解封包。这两个操作的性能损耗都是非常明显的。而三层网络方案则避免了这个过程,所以性能会得到很大的提升。
不过,隧道模式的优点在于,它依赖的底层原理非常直白,内核里的实现也非常成熟和稳定。而三层网络方案,相对来说维护成本会比较高,容易碰到路由规则分发和设置出现问题的情况,并且当容器数量很多时,宿主机上的路由规则会非常复杂,难以 Debug。所以最终选择选择哪种方案,还是要看自己的具体需求。
NetworkPolicy Kubernetes 的网络隔离方案
Kubernetes 里的 Pod 默认都是“允许所有”(Accept All)的,即:Pod 可以接收来自任何发送方的请求;或者,向任何接收方发送请求。而如果你要对这个情况作出限制,就必须通过 NetworkPolicy 对象来指定。
NetworkPolicy 定义的规则,其实就是“白名单”。
在具体实现上,凡是支持 NetworkPolicy 的 CNI 网络插件,都维护着一个 NetworkPolicy Controller,通过控制循环的方式对 NetworkPolicy 对象的增删改查做出响应,然后在宿主机上完成 iptables 规则的配置工作。
在 Kubernetes 生态里,目前已经实现了 NetworkPolicy 的网络插件包括 Calico、Weave 和 kube-router 等多个项目,但是并不包括 Flannel 项目。
所以说,如果想要在使用 Flannel 的同时还使用 NetworkPolicy 的话,你就需要再额外安装一个网络插件,比如 Calico 项目,来负责执行 NetworkPolicy。
Kubernetes 网络插件对 Pod 进行隔离,其实是靠在宿主机上生成 NetworkPolicy 对应的 iptable 规则来实现的。
NetworkPolicy 实际上只是宿主机上的一系列 iptables 规则。这跟传统 IaaS 里面的安全组(Security Group)其实是非常类似的。
Service
Service 是由 kube-proxy 组件,加上 iptables 来共同实现的。
对于一个新的Service对象被提交给 Kubernetes,那么 kube-proxy 就可以通过 Service 的 Informer 感知到这样一个 Service 对象的添加。而作为对这个事件的响应,它就会在宿主机上创建这样一条 iptables 规则(你可以通过 iptables-save 看到它),
Kubernetes 的 kube-proxy支持iptables的模式与IPVS的模式。
kube-proxy 通过 iptables 处理 Service 的过程,其实需要在宿主机上设置相当多的 iptables 规则。而且,kube-proxy 还需要在控制循环里不断地刷新这些规则来确保它们始终是正确的。
不难想到,当你的宿主机上有大量 Pod 的时候,成百上千条 iptables 规则不断地被刷新,会大量占用该宿主机的 CPU 资源,甚至会让宿主机“卡”在这个过程中。所以说,一直以来,基于 iptables 的 Service 实现,都是制约 Kubernetes 项目承载更多量级的 Pod 的主要障碍。
而 IPVS 模式的 Service,就是解决这个问题的一个行之有效的方法。
IPVS 模式的工作原理,其实跟 iptables 模式类似。当我们创建了前面的 Service 之后,kube-proxy 首先会在宿主机上创建一个虚拟网卡(叫作:kube-ipvs0),并为它分配 Service VIP 作为 IP 地址
而接下来,kube-proxy 就会通过 Linux 的 IPVS 模块,为这个 IP 地址设置三个 IPVS 虚拟主机,并设置这三个虚拟主机之间使用轮询模式 (rr) 来作为负载均衡策略。
相比于 iptables,IPVS 在内核中的实现其实也是基于 Netfilter 的 NAT 模式,所以在转发这一层上,理论上 IPVS 并没有显著的性能提升。但是,IPVS 并不需要在宿主机上为每个 Pod 设置 iptables 规则,而是把对这些“规则”的处理放到了内核态,从而极大地降低了维护这些规则的代价。
需要注意的是,IPVS 模块只负责上述的负载均衡和代理功能。而一个完整的 Service 流程正常工作所需要的包过滤、SNAT 等操作,还是要靠 iptables 来实现。只不过,这些辅助性的 iptables 规则数量有限,也不会随着 Pod 数量的增加而增加。
所以,在大规模集群里,非常建议将 kube-proxy 设置–proxy-mode=ipvs 来开启这个功能。它为 Kubernetes 集群规模带来的提升,还是非常巨大的。
如何从外部(Kubernetes 集群之外),访问到 Kubernetes 里创建的 Service?
最常用的一种方式就是:NodePort。
比如在Service 的定义里,我们声明它的类型是,type=NodePort。然后,我在 ports 字段里声明了 Service 的 8080 端口代理 Pod 的 80 端口,Service 的 443 端口代理 Pod 的 443 端口。
如果你不显式地声明 nodePort 字段,Kubernetes 就会为你分配随机的可用端口来设置代理。这个端口的范围默认是 30000-32767,你可以通过 kube-apiserver 的–service-node-port-range 参数来修改它。
这时候,要访问这个 Service,你只需要访问:
<任何一台宿主机的IP地址>:8080
就可以访问到某一个被代理的 Pod 的 80 端口了。
需要注意的是,在 NodePort 方式下,Kubernetes 会在 IP 包离开宿主机发往目的 Pod 时,对这个 IP 包做一次 SNAT 操作。
为什么一定要对流出的包做 SNAT操作呢?
当一个外部的 client 通过 node 2 的地址访问一个 Service 的时候,node 2 上的负载均衡规则,就可能把这个 IP 包转发给一个在 node 1 上的 Pod。这里没有任何问题。
而当 node 1 上的这个 Pod 处理完请求之后,它就会按照这个 IP 包的源地址发出回复。
可是,如果没有做 SNAT 操作的话,这时候,被转发来的 IP 包的源地址就是 client 的 IP 地址。所以此时,Pod 就会直接将回复发给client。对于 client 来说,它的请求明明发给了 node 2,收到的回复却来自 node 1,这个 client 很可能会报错。
对于 Pod 需要明确知道所有请求来源的场景来说,可以将 Service 的 spec.externalTrafficPolicy 字段设置为 local,这就保证了所有 Pod 通过 Service 收到请求之后,一定可以看到真正的、外部 client 的源地址。
这个机制的实现原理非常简单:这时候,一台宿主机上的 iptables 规则,会设置为只将 IP 包转发给运行在这台宿主机上的 Pod。所以这时候,Pod 就可以直接使用源地址将回复包发出,不需要事先进行 SNAT 了。
LoadBalancer
从外部访问 Service 的第二种方式,适用于公有云上的 Kubernetes 服务。这时候,你可以指定一个 LoadBalancer 类型的 Service。
在公有云提供的 Kubernetes 服务里,都使用了一个叫作 CloudProvider 的转接层,来跟公有云本身的 API 进行对接。所以,在上述 LoadBalancer 类型的 Service 被提交后,Kubernetes 就会调用 CloudProvider 在公有云上为你创建一个负载均衡服务,并且把被代理的 Pod 的 IP 地址配置给负载均衡服务做后端。
ExternalName
而第三种方式,是 Kubernetes 在 1.7 之后支持的一个新特性,叫作 ExternalName。
举个例子:
kind: Service
apiVersion: v1
metadata:
name: my-service
spec:
type: ExternalName
externalName: my.database.example.com
在上述 Service 的 YAML 文件中,我指定了一个 externalName=my.database.example.com 的字段。而且你应该会注意到,这个 YAML 文件里不需要指定 selector。
这时候,当你通过 Service 的 DNS 名字访问它的时候,比如访问:my-service.default.svc.cluster.local。那么,Kubernetes 为你返回的就是my.database.example.com。所以说,ExternalName 类型的 Service,其实是在 kube-dns 里为你添加了一条 CNAME 记录。这时,访问 my-service.default.svc.cluster.local 就和访问 my.database.example.com 这个域名是一个效果了。
访问这个服务的工作方式与其它的相同,唯一不同的是重定向发生在 DNS 层,而且不会进行代理或转发。 如果后续决定要将数据库迁移到 Kubernetes 集群中,可以启动对应的 Pod,增加合适的 Selector 或 Endpoint,修改 Service 的 type,完全不需要修改调用的代码,这样就完全解耦了。
此外,Kubernetes 的 Service 还允许你为 Service 分配公有 IP 地址,比如下面这个例子:
kind: Service
apiVersion: v1
metadata:
name: my-service
spec:
selector:
app: MyApp
ports:
- name: http
protocol: TCP
port: 80
targetPort: 9376
externalIPs:
- 80.11.12.10
在上述 Service 中,我为它指定的 externalIPs=80.11.12.10,那么此时,你就可以通过访问 80.11.12.10:80 访问到被代理的 Pod 了。不过,在这里 Kubernetes 要求 externalIPs 必须是至少能够路由到一个 Kubernetes 的节点。
一个 iptables 模式的 Service 对应的规则.
它们包括:
- KUBE-SERVICES 或者 KUBE-NODEPORTS 规则对应的 Service 的入口链,这个规则应该与 VIP 和 Service 端口一一对应;
- KUBE-SEP-(hash) 规则对应的 DNAT 链,这些规则应该与 Endpoints 一一对应;
- KUBE-SVC-(hash) 规则对应的负载均衡链,这些规则的数目应该与 Endpoints 数目一致;
- 如果是 NodePort 模式的话,还有 POSTROUTING 处的 SNAT 链。
Pod 没办法通过 Service 访问到自己?
这往往就是因为 kubelet 的 hairpin-mode 没有被正确设置。
只需要确保将 kubelet 的 hairpin-mode 设置为 hairpin-veth 或者 promiscuous-bridge 即可。
- 其中,在 hairpin-veth 模式下,你应该能看到 CNI 网桥对应的各个 VETH 设备,都将 Hairpin 模式设置为了 1,如下所示:
$ for d in /sys/devices/virtual/net/cni0/brif/veth*/hairpin_mode; do echo "$d = $(cat $d)"; done
/sys/devices/virtual/net/cni0/brif/veth4bfbfe74/hairpin_mode = 1
/sys/devices/virtual/net/cni0/brif/vethfc2a18c5/hairpin_mode = 1
- 如果是 promiscuous-bridge 模式的话,你应该看到 CNI 网桥的混杂模式(PROMISC)被开启,如下所示:
$ ifconfig cni0 |grep PROMISC
UP BROADCAST RUNNING PROMISC MULTICAST MTU:1460 Metric:1
Ingress
内置全局的、为了代理不同后端 Service 而设置的负载均衡服务,就是 Kubernetes 里的 Ingress 服务。
所谓 Ingress,就是 Service 的“Service”。
目前,Ingress 只能工作在七层,而 Service 只能工作在四层。所以当你想要在 Kubernetes 里为应用进行 TLS 配置等 HTTP 相关的操作时,都必须通过 Ingress 来进行。
所谓 Ingress 对象,其实就是 Kubernetes 项目对“反向代理”的一种抽象。
在实际的使用中,你只需要从社区里选择一个具体的 Ingress Controller,把它部署在 Kubernetes 集群里即可。
然后,这个 Ingress Controller 会根据你定义的 Ingress 对象,提供对应的代理能力。目前,业界常用的各种反向代理项目,比如 Nginx、HAProxy、Envoy、Traefik 等,都已经为 Kubernetes 专门维护了对应的 Ingress Controller。
一个 Nginx Ingress Controller 为你提供的服务,其实是一个可以根据 Ingress 对象和被代理后端 Service 的变化,来自动进行更新的 Nginx 负载均衡器。
最后需要创建一个 Service 来把 Nginx Ingress Controller 管理的 Nginx 服务暴露出去。
Kubernetes 的资源模型与资源管理。
资源模型
在 Kubernetes 里,Pod 是最小的原子调度单位。这也就意味着,所有跟调度和资源管理相关的属性都应该是属于 Pod 对象的字段。而这其中最重要的部分,就是 Pod 的 CPU 和内存配置。
在 Kubernetes 中,像 CPU 这样的资源被称作 “可压缩资源”(compressible resources) 。它的典型特点是,当可压缩资源不足时,Pod 只会“饥饿”,但不会退出。
而像内存这样的资源,则被称作 “不可压缩资源(incompressible resources) 。当不可压缩资源不足时,Pod 就会因为 OOM(Out-Of-Memory)被内核杀掉。
MiB(mebibyte)和 MB(megabyte)的区别?
1Mi=10241024;1M=10001000
Kubernetes 里 Pod 的 CPU 和内存资源,实际上还要分为 limits 和 requests 两种情况,如下所示:
spec.containers[].resources.limits.cpu
spec.containers[].resources.limits.memory
spec.containers[].resources.requests.cpu
spec.containers[].resources.requests.memory
这两者的区别其实非常简单:在调度的时候,kube-scheduler 只会按照 requests 的值进行计算。而在真正设置 Cgroups 限制的时候,kubelet 则会按照 limits 的值来进行设置。
更确切地说,当你指定了 requests.cpu=250m 之后,相当于将 Cgroups 的 cpu.shares 的值设置为 (250/1000)*1024。而当你没有设置 requests.cpu 的时候,cpu.shares 默认则是 1024。这样,Kubernetes 就通过 cpu.shares 完成了对 CPU 时间的按比例分配。
而如果你指定了 limits.cpu=500m 之后,则相当于将 Cgroups 的 cpu.cfs_quota_us 的值设置为 (500/1000)*100ms,而 cpu.cfs_period_us 的值始终是 100ms。这样,Kubernetes 就为你设置了这个容器只能用到 CPU 的 50%。
而对于内存来说,当你指定了 limits.memory=128Mi 之后,相当于将 Cgroups 的 memory.limit_in_bytes 设置为 128 * 1024 * 1024。而需要注意的是,在调度的时候,调度器只会使用 requests.memory=64Mi 来进行判断。
Kubernetes 这种对 CPU 和内存资源限额的设计,实际上参考了 Borg 论文中对“动态资源边界”的定义,既:容器化作业在提交时所设置的资源边界,并不一定是调度系统所必须严格遵守的,这是因为在实际场景中,大多数作业使用到的资源其实远小于它所请求的资源限额。
基于这种假设,Borg 在作业被提交后,会主动减小它的资源限额配置,以便容纳更多的作业、提升资源利用率。而当作业资源使用量增加到一定阈值时,Borg 会通过“快速恢复”过程,还原作业原始的资源限额,防止出现异常情况。
而 Kubernetes 的 requests+limits 的做法,其实就是上述思路的一个简化版:用户在提交 Pod 时,可以声明一个相对较小的 requests 值供调度器使用,而 Kubernetes 真正设置给容器 Cgroups 的,则是相对较大的 limits 值。不难看到,这跟 Borg 的思路相通的。
QoS 模型
在 Kubernetes 中,不同的 requests 和 limits 的设置方式,其实会将这个 Pod 划分到不同的 QoS 级别当中。
当 Pod 里的每一个 Container 都同时设置了 requests 和 limits,并且 requests 和 limits 值相等的时候,这个 Pod 就属于 Guaranteed 类别,
而当 Pod 不满足 Guaranteed 的条件,但至少有一个 Container 设置了 requests。那么这个 Pod 就会被划分到 Burstable 类别。
而如果一个 Pod 既没有设置 requests,也没有设置 limits,那么它的 QoS 类别就是 BestEffort。
三种 QoS类别 划分的主要应用场景,是当宿主机资源紧张的时候,kubelet 对 Pod 进行 Eviction(即资源回收)时需要用到的。
具体地说,当 Kubernetes 所管理的宿主机上不可压缩资源短缺时,就有可能触发 Eviction。比如,可用内存(memory.available)、可用的宿主机磁盘空间(nodefs.available),以及容器运行时镜像存储空间(imagefs.available)等等。
目前,Kubernetes 为你设置的 Eviction 的默认阈值如下所示:
memory.available<100Mi
nodefs.available<10%
nodefs.inodesFree<5%
imagefs.available<15%
当然,上述各个触发条件在 kubelet 里都是可配置的。比如下面这个例子:
kubelet --eviction-hard=imagefs.available<10%,memory.available<500Mi,nodefs.available<5%,nodefs.inodesFree<5% --eviction-soft=imagefs.available<30%,nodefs.available<10% --eviction-soft-grace-period=imagefs.available=2m,nodefs.available=2m --eviction-max-pod-grace-period=600
在这个配置中,你可以看到 Eviction 在 Kubernetes 里其实分为Soft和Hard 两种模式。
其中,Soft Eviction 允许你为 Eviction 过程设置一段“优雅时间”,比如上面例子里的 imagefs.available=2m,就意味着当 imagefs 不足的阈值达到 2 分钟之后,kubelet 才会开始 Eviction 的过程。
而 Hard Eviction 模式下,Eviction 过程就会在阈值达到之后立刻开始。
Kubernetes 计算 Eviction 阈值的数据来源,主要依赖于从 Cgroups 读取到的值,以及使用 cAdvisor 监控到的数据。
当宿主机的 Eviction 阈值达到后,就会进入 MemoryPressure 或者 DiskPressure 状态,从而避免新的 Pod 被调度到这台宿主机上。
而当 Eviction 发生的时候,kubelet 具体会挑选哪些 Pod 进行删除操作,就需要参考这些 Pod 的 QoS 类别了。
- 首当其冲的,自然是 BestEffort 类别的 Pod。
- 其次,是属于 Burstable 类别、并且发生“饥饿”的资源使用量已经超出了 requests 的 Pod。
- 最后,才是 Guaranteed 类别。并且,Kubernetes 会保证只有当 Guaranteed 类别的 Pod 的资源使用量超过了其 limits 的限制,或者宿主机本身正处于 Memory Pressure 状态时,Guaranteed 的 Pod 才可能被选中进行 Eviction 操作。
当然,对于同 QoS 类别的 Pod 来说,Kubernetes 还会根据 Pod 的优先级来进行进一步地排序和选择。
Kubernetes 里一个非常有用的特性:cpuset 的设置。
在使用容器的时候,你可以通过设置 cpuset 把容器绑定到某个 CPU 的核上,而不是像 cpushare 那样共享 CPU 的计算能力。
这种情况下,由于操作系统在 CPU 之间进行上下文切换的次数大大减少,容器里应用的性能会得到大幅提升。事实上,cpuset 方式,是生产环境里部署在线应用类型的 Pod 时,非常常用的一种方式。
实现方法非常简单:
- 首先,你的 Pod 必须是 Guaranteed 的 QoS 类型;
- 然后,你只需要将 Pod 的 CPU 资源的 requests 和 limits 设置为同一个相等的整数值即可。
为什么宿主机进入 MemoryPressure 或者 DiskPressure 状态后,新的 Pod 就不会被调度到这台宿主机上呢?
在 Kubernetes 里,实际上有一种叫作 Taint Nodes by Condition 的机制.
即当Node 本身进入异常状态的时候,比如 Condition 变成了 DiskPressure。那么, Kubernetes 会通过 Controller 自动给 Node 加上对应的 Taint,从而阻止新的 Pod 调度到这台宿主机上。
Kubernetes 的默认调度器(default scheduler)。
在 Kubernetes 项目中,默认调度器的主要职责,就是为一个新创建出来的 Pod,寻找一个最合适的节点(Node)。
而这里“最合适”的含义,包括两层:
- 从集群所有的节点中,根据调度算法挑选出所有可以运行该 Pod 的节点;
- 从第一步的结果中,再根据调度算法挑选一个最符合条件的节点作为最终结果。
所以在具体的调度流程中,默认调度器会首先调用一组叫作 Predicate 的调度算法,来检查每个 Node。然后,再调用一组叫作 Priority 的调度算法,来给上一步得到的结果里的每个 Node 打分。最终的调度结果,就是得分最高的那个 Node。
调度过程中 Predicates 和 Priorities 两个调度策略
Predicates
Predicates 在调度过程中的作用,可以理解为 Filter,即:它按照调度策略,从当前集群的所有节点中,“过滤”出一系列符合条件的节点。这些节点,都是可以运行待调度 Pod 的宿主机。
而在 Kubernetes 中,默认的调度策略有如下三种。
第一种类型,叫作 GeneralPredicates。
顾名思义,这一组过滤规则,负责的是最基础的调 Soft 和 Hard 两种模式 度策略。比如,PodFitsResources 计算的就是宿主机的 CPU 和内存资源等是否够用。
第二种类型,是与 Volume 相关的过滤规则。
这一组过滤规则,负责的是跟容器持久化 Volume 相关的调度策略。
其中,NoDiskConflict 检查的条件,是多个 Pod 声明挂载的持久化 Volume 是否有冲突。比如,AWS EBS 类型的 Volume,是不允许被两个 Pod 同时使用的。所以,当一个名叫 A 的 EBS Volume 已经被挂载在了某个节点上时,另一个同样声明使用这个 A Volume 的 Pod,就不能被调度到这个节点上了。
而 MaxPDVolumeCountPredicate 检查的条件,则是一个节点上某种类型的持久化 Volume 是不是已经超过了一定数目,如果是的话,那么声明使用该类型持久化 Volume 的 Pod 就不能再调度到这个节点了。
而 VolumeZonePredicate,则是检查持久化 Volume 的 Zone(高可用域)标签,是否与待考察节点的 Zone 标签相匹配。
此外,这里还有一个叫作 VolumeBindingPredicate 的规则。它负责检查的,是该 Pod 对应的 PV 的 nodeAffinity 字段,是否跟某个节点的标签相匹配。
第三种类型,是宿主机相关的过滤规则。
这一组规则,主要考察待调度 Pod 是否满足 Node 本身的某些条件。
比如,PodToleratesNodeTaints,负责检查的就是我们前面经常用到的 Node 的“污点”机制。只有当 Pod 的 Toleration 字段与 Node 的 Taint 字段能够匹配的时候,这个 Pod 才能被调度到该节点上。
而 NodeMemoryPressurePredicate,检查的是当前节点的内存是不是已经不够充足,如果是的话,那么待调度 Pod 就不能被调度到该节点上。
第四种类型,是 Pod 相关的过滤规则。
这一组规则,跟 GeneralPredicates 大多数是重合的。而比较特殊的,是 PodAffinityPredicate。这个规则的作用,是检查待调度 Pod 与 Node 上的已有 Pod 之间的亲密(affinity)和反亲密(anti-affinity)关系。
上面这四种类型的 Predicates,就构成了调度器确定一个 Node 可以运行待调度 Pod 的基本策略。
在具体执行的时候, 当开始调度一个 Pod 时,Kubernetes 调度器会同时启动 16 个 Goroutine,来并发地为集群里的所有 Node 计算 Predicates,最后返回可以运行这个 Pod 的宿主机列表。
Priorities
在 Predicates 阶段完成了节点的“过滤”之后,Priorities 阶段的工作就是为这些节点打分。这里打分的范围是 0-10 分,得分最高的节点就是最后被 Pod 绑定的最佳节点。
Priorities 里最常用到的一个打分规则,是 LeastRequestedPriority。它的计算方法,可以简单地总结为如下所示的公式:
score = (cpu((capacity-sum(requested))10/capacity) + memory((capacity-sum(requested))10/capacity))/2
可以看到,这个算法实际上就是在选择空闲资源(CPU 和 Memory)最多的宿主机。
而与 LeastRequestedPriority 一起发挥作用的,还有 BalancedResourceAllocation。它的计算公式如下所示:
score = 10 - variance(cpuFraction,memoryFraction,volumeFraction)*10
其中,每种资源的 Fraction 的定义是 :Pod 请求的资源 / 节点上的可用资源。而 variance 算法的作用,则是计算每两种资源 Fraction 之间的“距离”。而最后选择的,则是资源 Fraction 差距最小的节点。
所以说,BalancedResourceAllocation 选择的,其实是调度完成后,所有节点里各种资源分配最均衡的那个节点,从而避免一个节点上 CPU 被大量分配、而 Memory 大量剩余的情况。
此外,还有 NodeAffinityPriority、TaintTolerationPriority 和 InterPodAffinityPriority 这三种 Priority。顾名思义,它们与前面的 PodMatchNodeSelector、PodToleratesNodeTaints 和 PodAffinityPredicate 这三个 Predicate 的含义和计算方法是类似的。但是作为 Priority,一个 Node 满足上述规则的字段数目越多,它的得分就会越高。
在默认 Priorities 里,还有一个叫作 ImageLocalityPriority 的策略。它是在 Kubernetes v1.12 里新开启的调度规则,即:如果待调度 Pod 需要使用的镜像很大,并且已经存在于某些 Node 上,那么这些 Node 的得分就会比较高。
当然,为了避免这个算法引发调度堆叠,调度器在计算得分的时候还会根据镜像的分布进行优化,即:如果大镜像分布的节点数目很少,那么这些节点的权重就会被调低,从而“对冲”掉引起调度堆叠的风险。
Kubernetes 默认调度器的优先级(Priority)与抢占(Preemption)机制。
首先需要明确的是,优先级和抢占机制,解决的是 Pod 调度失败时该怎么办的问题。
正常情况下,当一个 Pod 调度失败后,它就会被暂时“搁置”起来,直到 Pod 被更新,或者集群状态发生变化,调度器才会对这个 Pod 进行重新调度。
但在有时候,我们希望的是这样一个场景。当一个高优先级的 Pod 调度失败后,该 Pod 并不会被“搁置”,而是会“挤走”某个 Node 上的一些低优先级的 Pod 。这样就可以保证这个高优先级 Pod 的调度成功。这个特性,其实也是一直以来就存在于 Borg 以及 Mesos 等项目里的一个基本功能。
而在 Kubernetes 里,优先级和抢占机制是在 1.10 版本后才逐步可用的。要使用这个机制,你首先需要在 Kubernetes 里提交一个 PriorityClass 的定义,如下所示:
apiVersion: scheduling.k8s.io/v1beta1
kind: PriorityClass
metadata:
name: high-priority
value: 1000000
globalDefault: false
description: "This priority class should be used for high priority service pods only."
上面这个 YAML 文件,定义的是一个名叫 high-priority 的 PriorityClass,其中 value 的值是 1000000 (一百万)。
kubernetes 规定,优先级是一个 32 bit 的整数,最大值不超过 1000000000(10 亿,1 billion),并且值越大代表优先级越高。 而超出 10 亿的值,其实是被 Kubernetes 保留下来分配给系统 Pod 使用的。显然,这样做的目的,就是保证系统 Pod 不会被用户抢占掉。
而一旦上述 YAML 文件里的 globalDefault 被设置为 true 的话,那就意味着这个 PriorityClass 的值会成为系统的默认值。而如果这个值是 false,就表示我们只希望声明使用该 PriorityClass 的 Pod 拥有值为 1000000 的优先级,而对于没有声明 PriorityClass 的 Pod 来说,它们的优先级就是 0。
在创建了 PriorityClass 对象之后,Pod 就可以声明使用它了,如下所示:
apiVersion: v1
kind: Pod
metadata:
name: nginx
labels:
env: test
spec:
containers:
- name: nginx
image: nginx
imagePullPolicy: IfNotPresent
priorityClassName: high-priority
可以看到,这个 Pod 通过 priorityClassName 字段,声明了要使用名叫 high-priority 的 PriorityClass。当这个 Pod 被提交给 Kubernetes 之后,Kubernetes 的 PriorityAdmissionController 就会自动将这个 Pod 的 spec.priority 字段设置为 1000000。
所以,当 Pod 拥有了优先级之后,高优先级的 Pod 就可能会比低优先级的 Pod 提前出队,从而尽早完成调度过程。这个过程,就是“优先级”这个概念在 Kubernetes 里的主要体现。
而当一个高优先级的 Pod 调度失败的时候,调度器的抢占能力就会被触发。这时,调度器就会试图从当前集群里寻找一个节点,使得当这个节点上的一个或者多个低优先级 Pod 被删除后,待调度的高优先级 Pod 就可以被调度到这个节点上。这个过程,就是“抢占”这个概念在 Kubernetes 里的主要体现。
Kubernetes 如何设计调度器里的抢占机制?
Kubernetes 调度器实现抢占算法的一个最重要的设计,就是在调度队列的实现里,使用了两个不同的队列。
第一个队列,叫作 activeQ。 凡是在 activeQ 里的 Pod,都是下一个调度周期需要调度的对象。所以,当你在 Kubernetes 集群里新创建一个 Pod 的时候,调度器会将这个 Pod 入队到 activeQ 里面。而我在前面提到过的、调度器不断从队列里出队(Pop)一个 Pod 进行调度,实际上都是从 activeQ 里出队的。
第二个队列,叫作 unschedulableQ,专门用来存放调度失败的 Pod。
而这里的一个关键点就在于,当一个 unschedulableQ 里的 Pod 被更新之后,调度器会自动把这个 Pod 移动到 activeQ 里,从而给这些调度失败的 Pod “重新做人”的机会。
回到我们的抢占者调度失败这个时间点上来。
调度失败之后,抢占者就会被放进 unschedulableQ 里面。
然后,这次失败事件就会触发调度器为抢占者寻找牺牲者的流程。
第一步,调度器会检查这次失败事件的原因,来确认抢占是不是可以帮助抢占者找到一个新节点。这是因为有很多 Predicates 的失败是不能通过抢占来解决的。比如,PodFitsHost 算法(负责的是,检查 Pod 的 nodeSelector 与 Node 的名字是否匹配),这种情况下,除非 Node 的名字发生变化,否则你即使删除再多的 Pod,抢占者也不可能调度成功。
第二步,如果确定抢占可以发生,那么调度器就会把自己缓存的所有节点信息复制一份,然后使用这个副本来模拟抢占过程。
这里的抢占过程很容易理解。调度器会检查缓存副本里的每一个节点,然后从该节点上最低优先级的 Pod 开始,逐一“删除”这些 Pod。而每删除一个低优先级 Pod,调度器都会检查一下抢占者是否能够运行在该 Node 上。一旦可以运行,调度器就记录下这个 Node 的名字和被删除 Pod 的列表,这就是一次抢占过程的结果了。
当遍历完所有的节点之后,调度器会在上述模拟产生的所有抢占结果里做一个选择,找出最佳结果。而这一步的判断原则,就是尽量减少抢占对整个系统的影响。比如,需要抢占的 Pod 越少越好,需要抢占的 Pod 的优先级越低越好,等等。
在得到了最佳的抢占结果之后,这个结果里的 Node,就是即将被抢占的 Node;被删除的 Pod 列表,就是牺牲者。所以接下来,调度器就可以真正开始抢占的操作了,这个过程,可以分为三步。
第一步,调度器会检查牺牲者列表,清理这些 Pod 所携带的 nominatedNodeName 字段。
第二步,调度器会把抢占者的 nominatedNodeName,设置为被抢占的 Node 的名字。
第三步,调度器会开启一个 Goroutine,同步地删除牺牲者。而第二步对抢占者 Pod 的更新操作,就会触发到我前面提到的“重新做人”的流程,从而让抢占者在下一个调度周期重新进入调度流程。
所以接下来,调度器就会通过正常的调度流程把抢占者调度成功。这也是为什么,我前面会说调度器并不保证抢占的结果:在这个正常的调度流程里,是一切皆有可能的。
不过,对于任意一个待调度 Pod 来说,因为有上述抢占者的存在,它的调度过程,其实是有一些特殊情况需要特殊处理的。
具体来说,在为某一对 Pod 和 Node 执行 Predicates 算法的时候,如果待检查的 Node 是一个即将被抢占的节点,即:调度队列里有 nominatedNodeName 字段值是该 Node 名字的 Pod 存在(可以称之为:“潜在的抢占者”)。那么,调度器就会对这个 Node ,将同样的 Predicates 算法运行两遍。
第一遍, 调度器会假设上述“潜在的抢占者”已经运行在这个节点上,然后执行 Predicates 算法;
第二遍, 调度器会正常执行 Predicates 算法,即:不考虑任何“潜在的抢占者”。
而只有这两遍 Predicates 算法都能通过时,这个 Pod 和 Node 才会被认为是可以绑定(bind)的。
不难想到,这里需要执行第一遍 Predicates 算法的原因,是由于 InterPodAntiAffinity 规则的存在。
由于 InterPodAntiAffinity 规则关心待考察节点上所有 Pod 之间的互斥关系,所以我们在执行调度算法时必须考虑,如果抢占者已经存在于待考察 Node 上时,待调度 Pod 还能不能调度成功。
当然,这也就意味着,我们在这一步只需要考虑那些优先级等于或者大于待调度 Pod 的抢占者。毕竟对于其他较低优先级 Pod 来说,待调度 Pod 总是可以通过抢占运行在待考察 Node 上。
而我们需要执行第二遍 Predicates 算法的原因,则是因为“潜在的抢占者”最后不一定会运行在待考察的 Node 上。关于这一点,前面已经讲解过了:Kubernetes 调度器并不保证抢占者一定会运行在当初选定的被抢占的 Node 上。
以上,就是 Kubernetes 默认调度器里优先级和抢占机制的实现原理了。
Kubernetes GPU 管理与 Device Plugin 机制。
待补充
kubelet 以及容器运行时管理
kubelet 的工作核心,就是一个控制循环,即:SyncLoop。而驱动这个控制循环运行的事件,包括四种:
- Pod 更新事件;
- Pod 生命周期变化;
- kubelet 本身设置的执行周期;
- 定时的清理事件。
kubelet 也是通过 Watch 机制,监听了与自己相关的 Pod 对象的变化。当然,这个 Watch 的过滤条件是该 Pod 的 nodeName 字段与自己相同。kubelet 会把这些 Pod 的信息缓存在自己的内存里。
而当一个 Pod 完成调度、与一个 Node 绑定起来之后, 这个 Pod 的变化就会触发 kubelet 在控制循环里注册的 Handler,也就是上图中的 HandlePods 部分。此时,通过检查该 Pod 在 kubelet 内存里的状态,kubelet 就能够判断出这是一个新调度过来的 Pod,从而触发 Handler 里 ADD 事件对应的处理逻辑。
在具体的处理过程当中,kubelet 会启动一个名叫 Pod Update Worker 的、单独的 Goroutine 来完成对 Pod 的处理工作。
kubelet 实际上就会调用一个叫作 GenericRuntime 的通用组件来发起创建 Pod 的 CRI 请求。
如果你使用的容器项目是 Docker 的话,那么负责响应这个请求的就是一个叫作 dockershim 的组件。它会把 CRI 请求里的内容拿出来,然后组装成 Docker API 请求发给 Docker Daemon。
CRI 与 容器运行时
把 kubelet 对容器的操作,统一地抽象成一个接口。这样,kubelet 就只需要跟这个接口打交道了。而作为具体的容器项目,比如 Docker、 rkt、runV,它们就只需要自己提供一个该接口的实现,然后对 kubelet 暴露出 gRPC 服务即可。这一层统一的容器操作接口,就是 CRI 了。
kubelet通过调用 GenericRuntime 的通用组件来发起创建 Pod 的 CRI 请求:
- 如果你使用的容器项目是 Docker 的话,那么负责响应这个请求的就是一个叫作 dockershim 的组件。
- 如果是其他的则需要在每台宿主机上单独安装一个负责响应 CRI 的组件,这个组件,一般被称作 CRI shim。顾名思义,CRI shim 的工作,就是扮演 kubelet 与容器项目之间的“垫片”(shim)。所以它的作用非常单一,那就是实现 CRI 规定的每个接口,然后把具体的 CRI 请求“翻译”成对后端容器项目的请求或者操作。
举个例子。CNCF 里的 containerd 项目,就可以提供一个典型的 CRI shim 的能力,即:将 Kubernetes 发出的 CRI 请求,转换成对 containerd 的调用,然后创建出 runC 容器。而 runC 项目,才是负责执行我们前面讲解过的设置容器 Namespace、Cgroups 和 chroot 等基础操作的组件。所以,这几层的组合关系,可以用如下所示的示意图来描述。
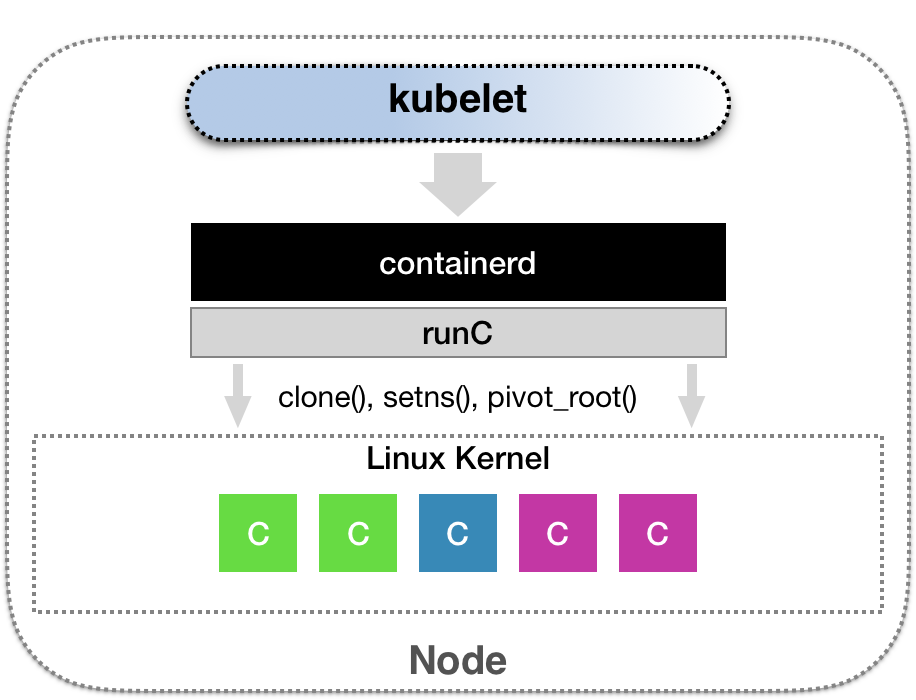
containerd 对 CRI 的具体实现
而作为一个 CRI shim,containerd 对 CRI 的具体实现,又是怎样的呢?
我们先来看一下 CRI 这个接口的定义。下面这幅示意图,就展示了 CRI 里主要的待实现接口。
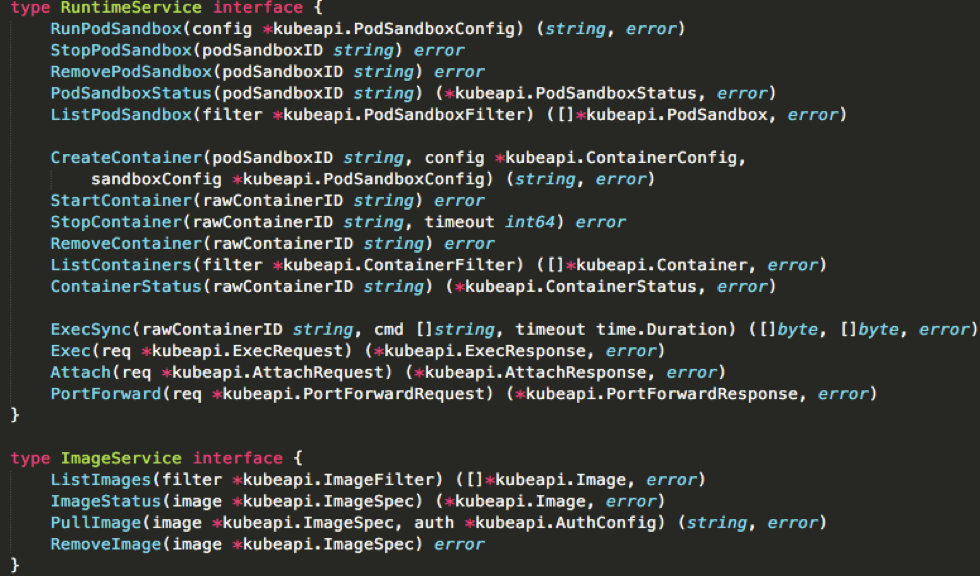
具体地说,我们可以把 CRI 分为两组:
- 第一组,是 RuntimeService。它提供的接口,主要是跟容器相关的操作。比如,创建和启动容器、删除容器、执行 exec 命令等等。
- 而第二组,则是 ImageService。它提供的接口,主要是容器镜像相关的操作,比如拉取镜像、删除镜像等等。
RuntimeService
在这一部分,CRI 设计的一个重要原则,就是确保这个接口本身,只关注容器,不关注 Pod。 这样做的原因,也很容易理解。
第一,Pod 是 Kubernetes 的编排概念,而不是容器运行时的概念。所以,我们就不能假设所有下层容器项目,都能够暴露出可以直接映射为 Pod 的 API。
第二,如果 CRI 里引入了关于 Pod 的概念,那么接下来只要 Pod API 对象的字段发生变化,那么 CRI 就很有可能需要变更。而在 Kubernetes 开发的前期,Pod 对象的变化还是比较频繁的,但对于 CRI 这样的标准接口来说,这个变更频率就有点麻烦了。
所以,在 CRI 的设计里,并没有一个直接创建 Pod 或者启动 Pod 的接口。
不过,相信你也已经注意到了,CRI 里还是有一组叫作 RunPodSandbox 的接口的。
这个 PodSandbox,对应的并不是 Kubernetes 里的 Pod API 对象,而只是抽取了 Pod 里的一部分与容器运行时相关的字段,比如 HostName、DnsConfig、CgroupParent 等。所以说,PodSandbox 这个接口描述的,其实是 Kubernetes 将 Pod 这个概念映射到容器运行时层面所需要的字段,或者说是一个 Pod 对象子集。
而作为具体的容器项目,你就需要自己决定如何使用这些字段来实现一个 Kubernetes 期望的 Pod 模型。这里的原理,可以用如下所示的示意图来表示清楚。
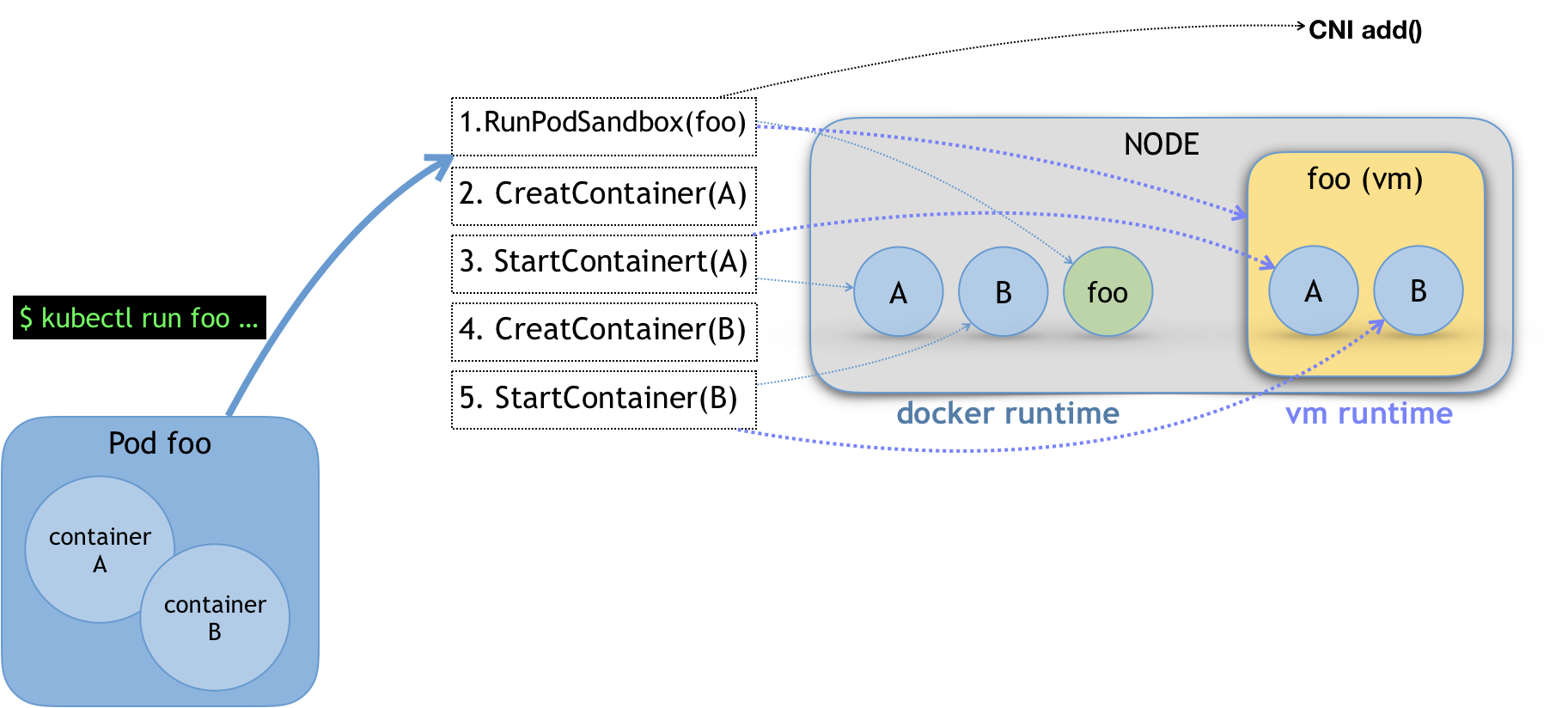
除了上述对容器生命周期的实现之外,CRI shim 还有一个重要的工作,就是如何实现 exec、logs 等接口。这些接口跟前面的操作有一个很大的不同,就是这些 gRPC 接口调用期间,kubelet 需要跟容器项目维护一个长连接来传输数据。这种 API,我们就称之为 Streaming API。
CRI shim 里对 Streaming API 的实现,依赖于一套独立的 Streaming Server 机制。这一部分原理,可以用如下所示的示意图来为你描述。
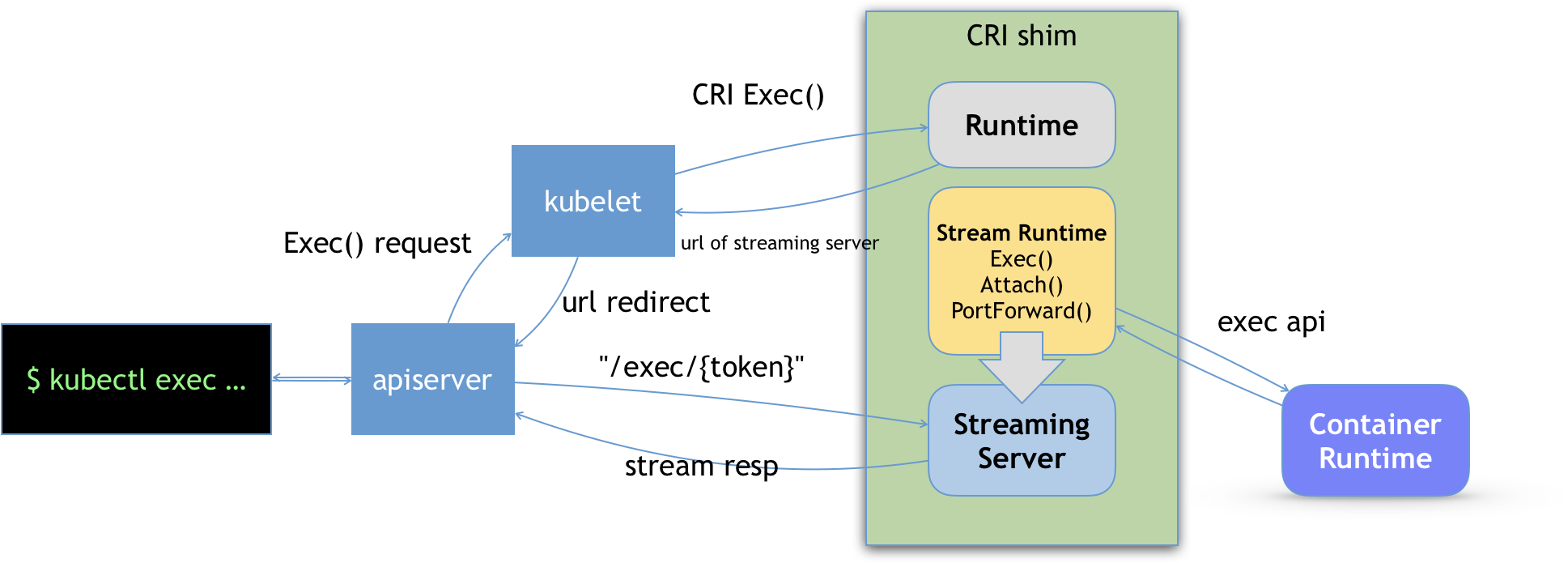
可以看到,当我们对一个容器执行 kubectl exec 命令的时候,这个请求首先交给 API Server,然后 API Server 就会调用 kubelet 的 Exec API。
这时,kubelet 就会调用 CRI 的 Exec 接口,而负责响应这个接口的,自然就是具体的 CRI shim。
但在这一步,CRI shim 并不会直接去调用后端的容器项目(比如 Docker )来进行处理,而只会返回一个 URL 给 kubelet。这个 URL,就是该 CRI shim 对应的 Streaming Server 的地址和端口。
而 kubelet 在拿到这个 URL 之后,就会把它以 Redirect 的方式返回给 API Server。所以这时候,API Server 就会通过重定向来向 Streaming Server 发起真正的 /exec 请求,与它建立长连接。
当然,这个 Streaming Server 本身,是需要通过使用 SIG-Node 为你维护的 Streaming API 库来实现的。并且,Streaming Server 会在 CRI shim 启动时就一起启动。此外,Stream Server 这一部分具体怎么实现,完全可以由 CRI shim 的维护者自行决定。比如,对于 Docker 项目来说,dockershim 就是直接调用 Docker 的 Exec API 来作为实现的。
以上,就是 CRI 的设计以及具体的工作原理了。
Kata Containers 与 gVisor
待补充
Prometheus
Prometheus 项目工作的核心,是使用 Pull (抓取)的方式去搜集被监控对象的 Metrics 数据(监控指标数据),然后,再把这些数据保存在一个 TSDB (时间序列数据库,比如 OpenTSDB、InfluxDB 等)当中,以便后续可以按照时间进行检索。
有了这套核心监控机制, Prometheus 剩下的组件就是用来配合这套机制的运行。比如:
-
Pushgateway,可以允许被监控对象以 Push 的方式向 Prometheus 推送 Metrics 数据。
-
而 Alertmanager,则可以根据 Metrics 信息灵活地设置报警。
-
当然, Prometheus 最受用户欢迎的功能,还是通过 Grafana 对外暴露出的、可以灵活配置的监控数据可视化界面。
有了 Prometheus 之后,我们就可以按照 Metrics 数据的来源,来对 Kubernetes 的监控体系做一个汇总了。
第一种 Metrics,是宿主机的监控数据。 这部分数据的提供,需要借助一个由 Prometheus 维护的Node Exporter 工具。一般来说,Node Exporter 会以 DaemonSet 的方式运行在宿主机上。其实,所谓的 Exporter,就是代替被监控对象来对 Prometheus 暴露出可以被“抓取”的 Metrics 信息的一个辅助进程。
而 Node Exporter 可以暴露给 Prometheus 采集的 Metrics 数据, 也不单单是节点的负载(Load)、CPU 、内存、磁盘以及网络这样的常规信息,它的 Metrics 指标可以说是“包罗万象”。
第二种 Metrics,是来自于 Kubernetes 的 API Server、kubelet 等组件的 /metrics API。 除了常规的 CPU、内存的信息外,这部分信息还主要包括了各个组件的核心监控指标。比如,对于 API Server 来说,它就会在 /metrics API 里,暴露出各个 Controller 的工作队列(Work Queue)的长度、请求的 QPS 和延迟数据等等。这些信息,是检查 Kubernetes 本身工作情况的主要依据。
第三种 Metrics,是 Kubernetes 相关的监控数据。 这部分数据,一般叫作 Kubernetes 核心监控数据(core metrics)。这其中包括了 Pod、Node、容器、Service 等主要 Kubernetes 核心概念的 Metrics。
其中,容器相关的 Metrics 主要来自于 kubelet 内置的 cAdvisor 服务。在 kubelet 启动后,cAdvisor 服务也随之启动,而它能够提供的信息,可以细化到每一个容器的 CPU 、文件系统、内存、网络等资源的使用情况。
需要注意的是,这里提到的 Kubernetes 核心监控数据,其实使用的是 Kubernetes 的一个非常重要的扩展能力,叫作 Metrics Server。
Metrics Server 在 Kubernetes 社区的定位,其实是用来取代 Heapster 这个项目的。在 Kubernetes 项目发展的初期,Heapster 是用户获取 Kubernetes 监控数据(比如 Pod 和 Node 的资源使用情况) 的主要渠道。而后面提出来的 Metrics Server,则把这些信息,通过标准的 Kubernetes API 暴露了出来。这样,Metrics 信息就跟 Heapster 完成了解耦,允许 Heapster 项目慢慢退出舞台。
而有了 Metrics Server 之后,用户就可以通过标准的 Kubernetes API 来访问到这些监控数据了。比如,下面这个 URL:
http://127.0.0.1:8001/apis/metrics.k8s.io/v1beta1/namespaces/<namespace-name>/pods/<pod-name>
当你访问这个 Metrics API 时,它就会为你返回一个 Pod 的监控数据,而这些数据,其实是从 kubelet 的 Summary API (即 :/stats/summary)采集而来的。Summary API 返回的信息,既包括了 cAdVisor 的监控数据,也包括了 kubelet 本身汇总的信息。
需要指出的是, Metrics Server 并不是 kube-apiserver 的一部分,而是通过 Aggregator 这种插件机制,在独立部署的情况下同 kube-apiserver 一起统一对外服务的。
Aggregator APIServer 的工作原理
可以看到,当 Kubernetes 的 API Server 开启了 Aggregator 模式之后,你再访问 apis/metrics.k8s.io/v1beta1 的时候,实际上访问到的是一个叫作 kube-aggregator 的代理。而 kube-apiserver,正是这个代理的一个后端;而 Metrics Server,则是另一个后端。
而且,在这个机制下,你还可以添加更多的后端给这个 kube-aggregator。所以 kube-aggregator 其实就是一个根据 URL 选择具体的 API 后端的代理服务器。通过这种方式,我们就可以很方便地扩展 Kubernetes 的 API 了。
而 Aggregator 模式的开启也非常简单:
- 如果你是使用 kubeadm 或者官方的 kube-up.sh 脚本部署 Kubernetes 集群的话,Aggregator 模式就是默认开启的;
- 如果是手动 DIY 搭建的话,你就需要在 kube-apiserver 的启动参数里加上如下所示的配置:
--requestheader-client-ca-file=<path to aggregator CA cert>
--requestheader-allowed-names=front-proxy-client
--requestheader-extra-headers-prefix=X-Remote-Extra-
--requestheader-group-headers=X-Remote-Group
--requestheader-username-headers=X-Remote-User
--proxy-client-cert-file=<path to aggregator proxy cert>
--proxy-client-key-file=<path to aggregator proxy key>
而这些配置的作用,主要就是为 Aggregator 这一层设置对应的 Key 和 Cert 文件。
Aggregator 功能开启之后,你只需要将 Metrics Server 的 YAML 文件部署起来,如下所示:
$ git clone https://github.com/kubernetes-incubator/metrics-server
$ cd metrics-server
$ kubectl create -f deploy/1.8+/
接下来,你就会看到 metrics.k8s.io 这个 API 出现在了你的 Kubernetes API 列表当中。
USE 原则和 RED 原则
最后,在具体的监控指标规划上,建议遵循业界通用的 USE 原则和 RED 原则。
其中,USE 原则指的是,按照如下三个维度来规划资源监控指标:
- 利用率(Utilization),资源被有效利用起来提供服务的平均时间占比;
- 饱和度(Saturation),资源拥挤的程度,比如工作队列的长度;
- 错误率(Errors),错误的数量。
而 RED 原则指的是,按照如下三个维度来规划服务监控指标:
- 每秒请求数量(Rate);
- 每秒错误数量(Errors);
- 服务响应时间(Duration)。
USE 原则主要关注的是“资源”,比如节点和容器的资源使用情况,而 RED 原则主要关注的是“服务”,比如 kube-apiserver 或者某个应用的工作情况。
Custom Metrics,自定义监控指标。
凭借强大的 API 扩展机制,Custom Metrics 已经成为了 Kubernetes 的一项标准能力。并且,Kubernetes 的自动扩展器组件 Horizontal Pod Autoscaler (HPA), 也可以直接使用 Custom Metrics 来执行用户指定的扩展策略,这里的整个过程都是非常灵活和可定制的。
不难想到,Kubernetes 里的 Custom Metrics 机制,也是借助 Aggregator APIServer 扩展机制来实现的。这里的具体原理是,当你把 Custom Metrics APIServer 启动之后,Kubernetes 里就会出现一个叫作custom.metrics.k8s.io的 API。而当你访问这个 URL 时,Aggregator 就会把你的请求转发给 Custom Metrics APIServer 。
而 Custom Metrics APIServer 的实现,其实就是一个 Prometheus 项目的 Adaptor。
比如,现在我们要实现一个根据指定 Pod 收到的 HTTP 请求数量来进行 Auto Scaling 的 Custom Metrics,这个 Metrics 就可以通过访问如下所示的自定义监控 URL 获取到:
https://<apiserver_ip>/apis/custom-metrics.metrics.k8s.io/v1beta1/namespaces/default/pods/sample-metrics-app/http_requests
这里的工作原理是,当你访问这个 URL 的时候,Custom Metrics APIServer 就会去 Prometheus 里查询名叫 sample-metrics-app 这个 Pod 的 http_requests 指标的值,然后按照固定的格式返回给访问者。
当然,http_requests 指标的值,就需要由 Prometheus 从目标 Pod 上采集来。
Prometheus Operator项目 通过 ServiceMonitor 对象来指定被监控 Pod
这里具体的做法有很多种,最普遍的做法,就是让 Pod 里的应用本身暴露出一个 /metrics API,然后在这个 API 里返回自己收到的 HTTP 的请求的数量。所以说,接下来 HPA 只需要定时访问前面提到的自定义监控 URL,然后根据这些值计算是否要执行 Scaling 即可。
容器日志收集与管理
首先需要明确的是,Kubernetes 里面对容器日志的处理方式,都叫作 cluster-level-logging,即:这个日志处理系统,与容器、Pod 以及 Node 的生命周期都是完全无关的。这种设计当然是为了保证,无论是容器挂了、Pod 被删除,甚至节点宕机的时候,应用的日志依然可以被正常获取到。
而对于一个容器来说,当应用把日志输出到 stdout 和 stderr 之后,容器项目在默认情况下就会把这些日志输出到宿主机上的一个 JSON 文件里。这样,你通过 kubectl logs 命令就可以看到这些容器的日志了。
Kubernetes 本身,实际上是不会为你做容器日志收集工作的,所以为了实现上述 cluster-level-logging,你需要在部署集群的时候,提前对具体的日志方案进行规划。而 Kubernetes 项目本身,主要为你推荐了三种日志方案。
第一种,在 Node 上部署 logging agent,将日志文件转发到后端存储里保存起来。
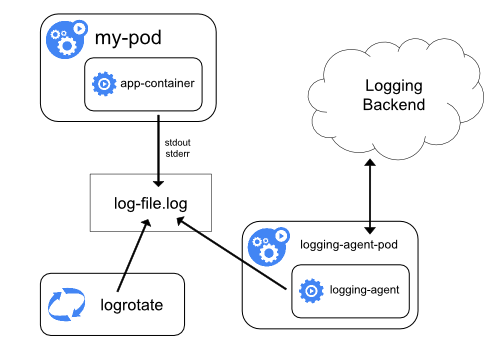
这里的核心就在于 logging agent ,它一般都会以 DaemonSet 的方式运行在节点上,然后将宿主机上的容器日志目录挂载进去,最后由 logging-agent 把日志转发出去。
在 Node 上部署 logging agent 最大的优点,在于一个节点只需要部署一个 agent,并且不会对应用和 Pod 有任何侵入性。所以,这个方案,在社区里是最常用的一种。
这种方案的不足之处就在于,它要求应用输出的日志,都必须是直接输出到容器的 stdout 和 stderr 里。
Kubernetes 容器日志方案的第二种
就是对这种特殊情况的一个处理,即:当容器的日志只能输出到某些文件里的时候,我们可以通过一个 sidecar 容器把这些日志文件重新输出到 sidecar 的 stdout 和 stderr 上,这样就能够继续使用第一种方案了。
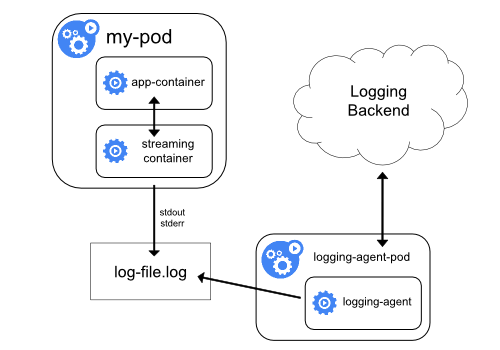
需要注意的是,这时候,宿主机上实际上会存在两份相同的日志文件:一份是应用自己写入的;另一份则是 sidecar 的 stdout 和 stderr 对应的 JSON 文件。这对磁盘是很大的浪费。所以说,除非万不得已或者应用容器完全不可能被修改,否则我还是建议你直接使用方案一,或者直接使用下面的第三种方案。
第三种方案,就是通过一个 sidecar 容器,直接把应用的日志文件发送到远程存储里面去。
也就是相当于把方案一里的 logging agent,放在了应用 Pod 里。这种方案的架构如下所示:
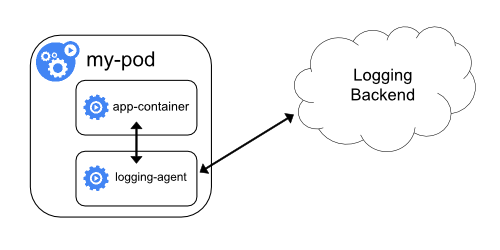
在这种方案里,你的应用还可以直接把日志输出到固定的文件里而不是 stdout,你的 logging-agent 还可以使用 fluentd,后端存储还可以是 ElasticSearch。只不过, fluentd 的输入源,变成了应用的日志文件。
需要注意的是,这种方案虽然部署简单,并且对宿主机非常友好,但是这个 sidecar 容器很可能会消耗较多的资源,甚至拖垮应用容器。并且,由于日志还是没有输出到 stdout 上,所以你通过 kubectl logs 是看不到任何日志输出的。
将日志直接输出到 stdout 和 stderr,有没有什么其他的隐患或者问题呢?如何进行处理呢?
这样做有一个问题,就是日志都需要经过 Docker Daemon 的处理才会写到宿主机磁盘上,所以宿主机没办法以容器为单位进行日志文件的 Rotate。这时候,还是要考虑通过宿主机的 Agent 来对容器日志进行处理和收集的方案。
创建一个Pod的流程
用户发起一个创建POD的POST请求到APIServer
APIServer收到请求后首先会过虑这个请求,并完成一些前置性的工作,比如授权、超时处理、审计等
然后,请求会进入 MUX 和 Routes 流程。APIServer根据这个请求去匹配找到对应的POD类型的定义
接着APIServer会进行一个 Convert 工作,将请求的内容转换成Super Version 对象,它正是该 API 资源类型所有版本的字段全集。
接下来,APIServer 会先后进行 Admission() (准入控制,比如添加标签,添加sidecar容器等) 和 Validation()(验证各个字段的合法性) 操作。
最后,APIServer 会把验证过的 API 对象转换成用户最初提交的版本,进行序列化操作,并调用 Etcd 的 API 把它保存起来。
Scheduler调度器通过监听APIServer,发现一个未调度的POD,
Scheduler开始尝试调度,排除不适合调度的节点,筛选出一组可以调度的节点,然后打分选出一个最高分的节点
然后将Pod 与 Node 绑定起来,然后将信息通过APIServer保存到ETCD中完成调度
节点上的kubelet通过WATCH机制,监听与自己相关的POD的对象,kubelet 会把相关的 Pod 的信息缓存在自己的内存里。
kubelet通过检查该 Pod 在 kubelet 内存里的状态,kubelet 就能够判断出这是一个新调度过来的 Pod,
kubelet 会启动一个名叫 Pod Update Worker 的、单独的 Goroutine 来为这个新的 Pod 生成对应的 Pod Status,检查 Pod 所声明使用的 Volume 是不是已经准备好。
然后,调用下层的容器运行时(比如 Docker),发起一个开始创建这个 Pod 所定义的容器的CRI请求。
容器运行时(比如 Docker)响应这个请求,然后开始创建对应的容器。